
Tarantool хранит данные в памяти (движок memtx) и/или на диске (vinyl), но устойчивость к сбоям обеспечивает не оперативная память, а два типа файлов на диске: снапшоты (.snap) и журнал упреждающей записи WAL (.xlog). Снапшот - это полный слепок всего набора данных на момент контрольной точки (checkpoint). WAL - это последовательность всех изменяющих запросов, записанных ПОСЛЕ снапшота. Эта пара и есть основа всей стратегии бэкапа: снапшот даёт базу, WAL даёт дельту до текущего момента.
Ключевая особенность движка - append-only архитектура. Tarantool никогда не перезаписывает уже записанные данные, он только дописывает новые файлы. Именно поэтому бэкап можно снимать в любой момент, прямо под нагрузкой, почти без накладных расходов: мы копируем файлы, которые гарантированно не меняются под нами.
Механика: как это устроено внутри
Снапшот и контрольная точка. Когда вы вызываете box.snapshot() (или его делает чекпойнт-демон), Tarantool фиксирует контрольную точку: сериализует всё содержимое memtx в новый .snap файл, имя которого равно текущему vclock/LSN (номер последней применённой транзакции). Важная деталь внутренней механики: создание снапшота НЕ начинает новый WAL-файл. Тот .xlog, который был текущим в момент старта снапшота, должен быть сохранён - в него продолжают писаться записи, появившиеся уже во время снятия снапшота.
Восстановление (recovery). При старте инстанс ищет самый свежий .snap, загружает его в память, а затем "доигрывает" поверх все .xlog с LSN больше, чем у снапшота, повторно применяя каждый записанный запрос (redo). Так состояние восстанавливается ровно до последней успешно записанной в WAL транзакции. После старта Tarantool обычно делает новый снапшот, и старые WAL становятся не нужны.
Чекпойнт-демон и сборщик мусора. Чекпойнт-демон - это постоянно работающий фибер. Он снимает снапшоты по расписанию, основанному на двух условиях: snapshot.by.interval (раз в N секунд) и snapshot.by.wal_size (когда суммарный размер WAL с момента последнего снапшота превысил порог). После нового снапшота включается сборщик мусора (garbage collector): когда число снапшотов превышает snapshot.count, удаляется самый старый .snap и все .xlog, которые старше него и чьи данные уже вошли в снапшот.
Сборщик мусора - ваш главный враг при ручном бэкаде. Если он удалит WAL между снятием снапшота и копированием, цепочка восстановления порвётся. Поэтому на время копирования смешанного (memtx+vinyl) бэкапа GC надо приостанавливать через box.backup.start().
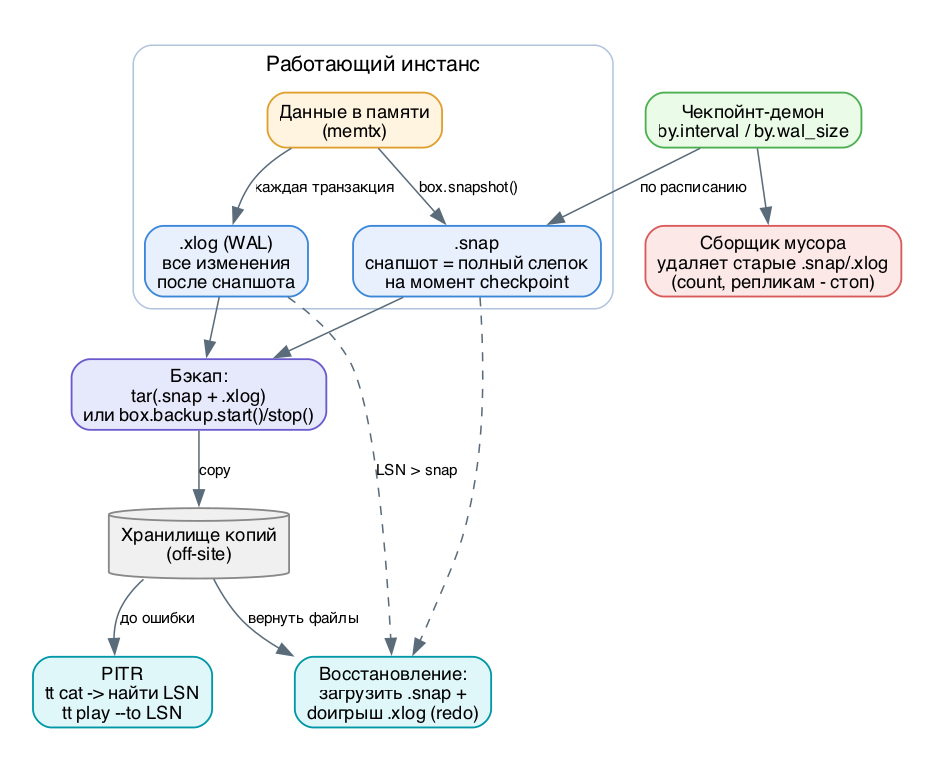
Снапшот плюс WAL: бэкап и восстановление
Ключевые команды и примеры
Ручное снятие снапшота.
Код: Выделить всё
-- форсировать контрольную точку прямо сейчас
box.snapshot()
-- посмотреть текущий vclock (позицию журнала)
box.info.vclock
-- ---
-- - {1: 999}
-- ...
Код: Выделить всё
tar czf backup_$(date +%F).tar.gz \
var/lib/instance001/*.snap \
var/lib/instance001/*.xlog
Код: Выделить всё
-- вернёт список файлов для копирования и приостановит GC
files = box.backup.start()
-- ... внешним инструментом копируем все пути из files в безопасное место ...
box.backup.stop() -- разрешаем сборщику мусора работать дальше
Код: Выделить всё
groups:
group001:
replicasets:
replicaset001:
instances:
instance001:
snapshot:
by:
interval: 7200 # снапшот каждые 2 часа
wal_size: 1000000000 # или при 1 ГБ WAL
count: 3 # хранить 3 снапшота
wal:
mode: write # write | fsync | none
max_size: 268435456 # ротация .xlog на 256 МБ
cleanup_delay: 18000 # отложить удаление WAL на 5 ч
Восстановление на точку времени (PITR). Если данные удалили и удаление разъехалось по репликам, восстанавливаем на момент ДО ошибки. Сначала ищем нужный LSN, читая журнал утилитой tt cat, затем доигрываем файлы в чистый инстанс утилитой tt play:
Код: Выделить всё
# посмотреть содержимое журнала и найти LSN ошибочной операции
tt cat var/lib/instance001/*.xlog --show-system
# доиграть снапшот и журналы в новый инстанс ДО нужного LSN
tt play 127.0.0.1:3302 \
var/lib/instance001/*.snap \
var/lib/instance001/*.xlog \
--to 4500 \
--username admin --password secret
- "Снапшота достаточно для бэкапа". Нет: между снапшотами есть транзакции, живущие только в WAL. Без .xlog вы откатитесь к моменту последней контрольной точки и потеряете дельту.
- "box.snapshot() начинает новый журнал". Нет. WAL, активный на момент старта снапшота, обязателен для восстановления - не удаляйте его вручную.
- "snapshot.count жёстко ограничивает диск". Не всегда: GC не удалит файлы, нужные подключающейся или отставшей реплике, а также во время box.backup.start(). При живой репликации checkpoint_count фактически не работает, пока все реплики не догнали мастер - диск может разрастись.
- "Реплика - это и есть бэкап". Реплика защищает от отказа железа, но НЕ от логической ошибки: DELETE/DROP мгновенно реплицируется на все узлы. Для защиты от ошибок оператора нужен именно файловый бэкап или PITR.
- "force_recovery починит всё". Опция force_recovery лишь пропускает битые записи в .snap/.xlog и читает столько, сколько сможет, завершаясь с предупреждением. Это аварийный режим спасения данных, а не штатное восстановление.
- LSN различаются на разных репликах. Фильтры --from/--to в tt cat/tt play осмысленны только в паре с конкретным --replica; смешивать ID реплик в одном фильтре нельзя.
- wal.mode: none отключает журнал целиком - данные между снапшотами не переживут рестарт. Применяйте только для кэшей, где потеря допустима.
Запустите локальный инстанс. Создайте спейс, вставьте несколько кортежей, вызовите box.snapshot() и запомните box.info.vclock. Затем вставьте ещё кортежи (НЕ делая снапшот) и аккуратно остановите инстанс (kill, не drop файлов). Удалите последний .xlog из каталога данных, запустите инстанс снова и убедитесь, что "послеснапшотные" вставки пропали, а данные из снапшота на месте. Верните .xlog, перезапустите и убедитесь, что данные восстановились полностью. Объясните себе, почему именно так: какой файл дал базу, какой - дельту.
Контрольные вопросы
- Что произойдёт при восстановлении, если у вас есть свежий .snap, но удалён .xlog, который был активен в момент его снятия? Почему?
- Чем горячий бэкап только-memtx отличается от смешанного memtx+vinyl и зачем во втором случае нужен box.backup.start()/stop()?
- Почему наличие реплик не отменяет необходимости файловых бэкапов, и от какого класса аварий защищает именно PITR через tt play?
- Как связаны snapshot.count (checkpoint_count) и работа сборщика мусора, и при каких условиях лимит на число снапшотов фактически не соблюдается?