
Когда вы запускаете экземпляр Tarantool, он не сразу становится полноправным членом набора реплик. Узел проходит несколько внутренних состояний, и за каждым стоит своя механика обмена файлами и сообщениями по сети. Понимать эту цепочку важно: именно здесь рождаются загадочные ошибки вроде ER_BOOTSTRAP_READONLY, застрявший orphan, XlogGapError и крутящийся в бесконечном цикле rejoin.
Главная последовательность, к которой мы идём:
Сразу зафиксируем терминологию, чтобы не путаться. Bootstrap - это рождение НАБОРА реплик (создание самого первого снапшота и UUID набора). Join - это вступление КОНКРЕТНОГО нового узла в уже существующий набор. Follow - рабочее состояние, когда узел просто тянет и применяет чужой WAL. Rejoin (rebootstrap) - аварийное повторное скачивание снапшота, когда обычное восстановление невозможно. Всё это управляется одним вызовом box.cfg{} (в треке 1.x/2.x) или применением декларативного YAML-конфига (в треке 3.x).bootstrap -> join -> follow, а при сбое восстановления -> rejoin (он же rebootstrap)
Механика и архитектура
Любому экземпляру для работы нужен начальный набор чекпойнт-файлов: .snap для memtx и .run для vinyl, плюс .xlog с последующими изменениями. Откуда узел берёт это начальное состояние при первом старте - и определяет его судьбу. Логика внутри box.cfg{} ветвится по двум признакам: есть ли локальный .snap и пуст ли параметр replication.
1. Bootstrap набора (первый старт всего кластера)
Нет .snap, replication указывает на соседей, в _cluster пусто у всех. Узлы соединяются друг с другом и по стратегии bootstrap_strategy выбирают лидера. Критерии выбора лидера: наибольший vclock и приоритет read-write над read-only. Лидер генерирует UUID набора (хранится в _schema), делает самый первый .snap и раздаёт его остальным. Это и есть automatic bootstrap. Если у одинокого узла нет .snap, replication пуст и read_only=true, он не может стать первым мастером - получите ER_BOOTSTRAP_READONLY.
2. Join нового узла
Нет локального .snap, но replication указывает на работающий мастер, а в его _cluster нашего UUID ещё нет. Узел шлёт мастеру join-запрос со своим instance UUID. Мастер в ответ отдаёт UUID набора и содержимое своего .snap (под капотом это IPROTO_JOIN, а для анонимной реплики - IPROTO_FETCH_SNAPSHOT). Узел сохраняет UUID набора в _schema, пишет себя и мастера в _cluster и собирает собственный снапшот из полученных данных. В этот момент мастер выдаёт реплике короткий целочисленный instance id (1, 2, 3...) - он экономнее UUID и попадает в каждую строку WAL и в vclock.
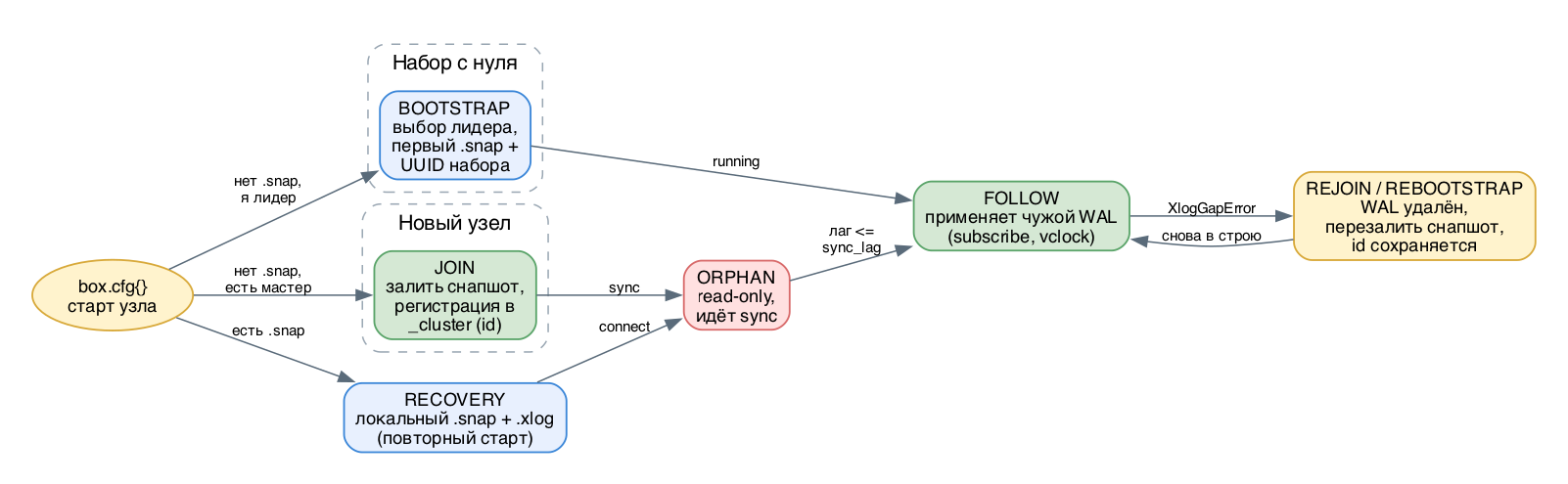
Состояния узла: bootstrap, join, follow, rejoin
3. Follow (штатная работа)
После join (или после bootstrap у лидера) узел шлёт subscribe-запрос со своим vector clock (vclock) - набором пар instance_id -> lsn. Каждый сосед отдаёт только те строки WAL, чей lsn больше, чем в присланном vclock. Так узел догоняет набор без повторной заливки снапшота, после чего просто продолжает применять входящий поток. Это состояние видно как upstream.status = follow.
Recovery и orphan
Если .snap уже есть (повторный старт), box.cfg{} сначала проводит локальное восстановление из своих .snap и .xlog, затем подключается к соседям и синхронизируется. Пока узел подключается и догоняет нужное число узлов (определяется bootstrap_strategy), он находится в состоянии orphan - это read-only. Узел покидает orphan, когда его лаг становится не больше replication_sync_lag. Если replication_sync_lag не задан, фаза sync пропускается и узел сразу уходит в follow.
4. Rejoin / rebootstrap
Самый тонкий случай. Узел уже был в наборе, но отстал так сильно, что на мастере garbage collector успел удалить нужные ему .xlog. Обычное восстановление по vclock невозможно - возникает XlogGapError (дыра в логе). Tarantool это умеет лечить автоматически: узел выбрасывает старое состояние и заново тянет свежий снапшот мастера - как при join, но с одним отличием. Его instance id СОХРАНЯЕТСЯ. Если бы id сменился, мастер счёл бы реплику новым узлом и навсегда держал бы в _cluster запись о мёртвом id (а их всего 32 на набор). Rebootstrap полностью автоматический начиная с 1.10.2.
Ключевые команды и код
Трек 1.x/2.x, классический box.cfg{}. Первый мастер набора:
Код: Выделить всё
-- мастер: пустой replication, read-write
box.cfg{ listen = 3301 }
box.schema.user.grant('guest', 'replication')
Код: Выделить всё
box.cfg{
listen = 3302,
replication = { '127.0.0.1:3301', '127.0.0.1:3302' },
read_only = true,
}
Код: Выделить всё
replication:
bootstrap_strategy: auto # auto | config | supervised | native | legacy(deprecated)
failover: off
groups:
group-001:
replicasets:
rs-001:
instances:
master: { iproto: { listen: [{uri: '127.0.0.1:3301'}] } }
replica: { iproto: { listen: [{uri: '127.0.0.1:3302'}] }, database: { mode: ro } }
Код: Выделить всё
-- выполнить через admin-консоль на нужном узле
box.ctl.make_bootstrap_leader()
Код: Выделить всё
box.info.status -- running | orphan | ...
box.info.id -- 0 у анонимной реплики
box.info.replication[2].upstream.status -- connecting | sync | follow | disconnected
box.info.vclock -- {1: 827, 2: 584}
box.space._cluster:select{} -- кто зарегистрирован в наборе
Код: Выделить всё
Состояние upstream.status смысл
bootstrap - рождение набора, делается первый .snap
join connecting/sync новый узел тянет снапшот мастера
orphan sync read-only, догоняем нужное число узлов
follow follow штатно применяем чужой WAL
rejoin connecting WAL пропал, повторная заливка снапшота
- bootstrap и join - не одно и то же. Bootstrap происходит один раз на весь набор, join - на каждый новый узел. В логах легко спутать.
- Orphan - это не ошибка, а нормальная переходная фаза read-only. Узел сам выйдет из неё, когда догонит соседей. Застревает он, если соседи недоступны или лаг не падает ниже replication_sync_lag.
- Чтобы новый узел смог сделать join, у мастера должна быть выдана привилегия replication пользователю, под которым реплика подключается (по умолчанию guest). Забыли grant - получите ER_ACCESS_DENIED.
- XlogGapError у нового узла в свежем наборе часто значит, что мастер успел удалить .xlog раньше, чем реплика их забрала. Лечится принудительным box.snapshot() на мастере перед добавлением реплики.
- Лимит _cluster - 32 узла, и записи мёртвых id автоматически не переиспользуются. Сменили instance UUID при пересоздании узла - получили лишний мёртвый id. Именно поэтому rebootstrap бережно сохраняет старый id.
- Анонимная реплика (replication_anon=true вместе с read_only=true) делает fetch снапшота, но НЕ регистрируется в _cluster, её box.info.id = 0, и лимит в 32 на неё не распространяется. Чтобы стать обычной, она шлёт IPROTO_REGISTER.
Соберите набор из двух узлов на одной машине (мастер 3301, реплика 3302). На мастере выдайте guest право replication и запишите пару строк в любой спейс. Запустите реплику и поймайте момент join: проверьте box.info.status (должен быть running после короткого orphan) и box.space._cluster:select{} - там должно появиться ДВЕ записи с instance id 1 и 2. Затем на реплике сравните box.info.vclock с мастерским: после догона lsn по id мастера должны совпасть, а upstream.status стать follow.
Контрольные вопросы
- Чем bootstrap набора отличается от join отдельного узла, и какой из них происходит один раз на весь кластер?
- Что узел получает от мастера на стадии join, и почему ему выдают короткий instance id, а не только UUID?
- Почему при rejoin (rebootstrap) обязательно сохраняется прежний instance id, а не выдаётся новый?
- Что означает состояние orphan, является ли оно ошибкой и при каком условии узел из него выходит в follow?