
Когда один инстанс Tarantool перестаёт справляться с объёмом данных или нагрузкой, его данные нужно размазать по нескольким машинам - это горизонтальное масштабирование (шардирование). Официальный модуль для этого - vshard. Он не встроен в ядро, ставится отдельно (минимальная версия 0.1.25):
Код: Выделить всё
tt rocks install vshardТри компонента архитектуры
Storage (хранилище) - узел, который держит часть данных. Несколько реплик одного и того же подмножества данных образуют replica set (он же shard). Внутри replica set один инстанс - master (читает и пишет), остальные - replica (только чтение). Рекомендуется минимум 2, а для отказоустойчивости 3+ инстанса на шард.
Router (маршрутизатор) - прокси без персистентного состояния. Все запросы приложения идут через router. Он скрывает от приложения топологию: сколько шардов, где они, идёт ли сейчас ребалансировка, случился ли failover. Router держит постоянный пул соединений ко всем storage (создаётся на старте, чтобы сразу отловить ошибки конфигурации) и кэширует таблицу маршрутизации.
Rebalancer (ребалансировщик) - фоновый процесс, который выравнивает число бакетов по шардам. В 3.x его можно не указывать явно: он автоматически выбирается из мастеров.
Виртуальные бакеты: как это устроено внутри
Весь датасет логически разбит на N бакетов с номерами от 1 до N. N задаётся один раз при бутстрапе кластера через sharding.bucket_count и не меняется после старта. Каждый бакет целиком принадлежит ровно одному replica set - бакет не может лежать на двух шардах сразу.
Bucket id хранится в двух местах одновременно, и это ключ к консистентности:
- В отдельном поле каждого тапла каждой шардируемой спейс.
- В системном спейсе _bucket на storage - там лежит сам факт "этот бакет тут и в таком состоянии".
Router не знает соответствия bucket id -> primary key. Он знает только bucket id -> replica set (таблица маршрутизации). Чтобы найти бакет, приложение либо передаёт bucket id явно, либо router вычисляет его сам по данным запроса хэш-функцией.
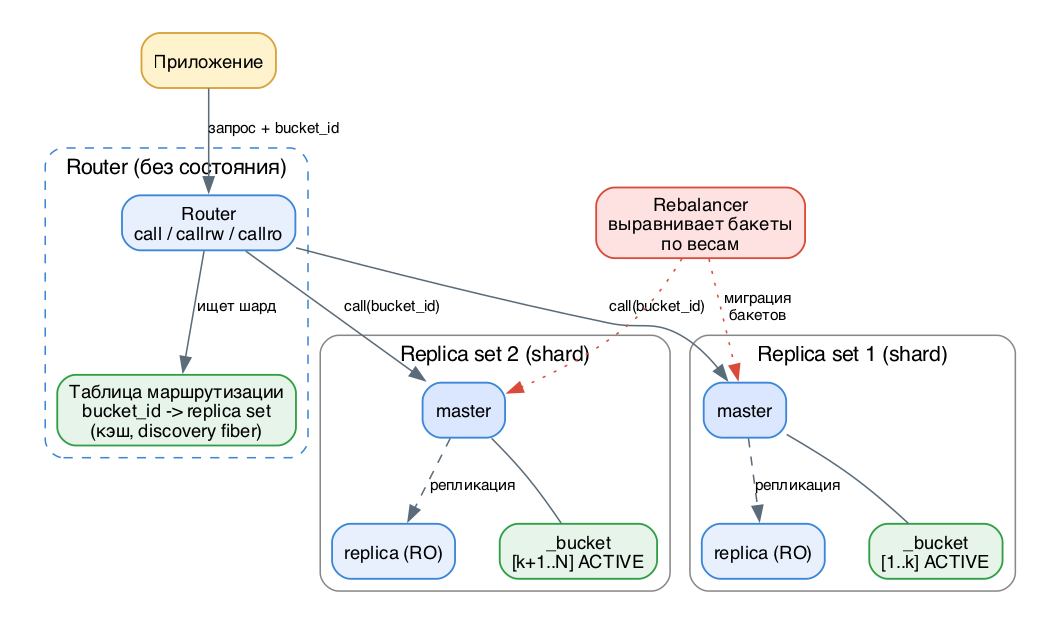
Архитектура vshard: router, бакеты, шарды
Жизненный цикл запроса
Единственная операция, которую понимает router, - это call. Всё DML идёт через него:
Код: Выделить всё
result = vshard.router.call(bucket_id, mode, func_name, {args}, {opts})
-- mode: 'read' или 'write'
-- удобные обёртки:
vshard.router.callrw(bucket_id, 'insert_band', {id, bucket_id, ...})
vshard.router.callro(bucket_id, 'get_band', {id})
- Router берёт bucket_id и ищет в таблице маршрутизации нужный replica set. Если маппинг ещё не известен (discovery fiber не успел заполнить таблицу), router опрашивает все storage, чтобы найти бакет.
- Storage проверяет: лежит ли бакет в его _bucket и в каком он состоянии. Для записи бакет должен быть ACTIVE или PINNED, для чтения допустим ещё SENDING.
- Если проверки прошли - функция выполняется. Иначе запрос падает с ошибкой "wrong bucket".
Код: Выделить всё
-- старая, по строковому представлению; неконсистентна для cdata-чисел
local b = vshard.router.bucket_id_strcrc32(key)
-- рекомендуемая: CRC32 от MessagePack-представления,
-- bucket_id не зависит от Lua-типа числа (123 и 123ULL дадут одно и то же)
local b = vshard.router.bucket_id_mpcrc32(key)
Код: Выделить всё
box.once('schema', function()
box.schema.space.create('bands')
box.space.bands:format({
{name = 'id', type = 'unsigned'},
{name = 'bucket_id', type = 'unsigned'},
{name = 'band_name', type = 'string'},
})
box.space.bands:create_index('id', {parts = {'id'}})
box.space.bands:create_index('bucket_id',
{parts = {'bucket_id'}, unique = false})
end)
При миграции бакет проходит через состояния: ACTIVE (доступен на чтение/запись), PINNED (как ACTIVE, но запрещён к переезду), SENDING (копируется, источник ещё отдаёт чтения), RECEIVING (наполняется, все запросы отвергаются), SENT (уехал; router по нему вычисляет новое место; через 0.5 c уходит в GARBAGE), GARBAGE (удаляется сборщиком).
Ребалансировщик считает для каждого шарда эталонное (идеальное) число бакетов исходя из bucket_count и весов. Запуск происходит, когда дисбаланс превышает порог:
Код: Выделить всё
|etalon - real| / etalon * 100 > rebalancer_disbalance_threshold
Частые заблуждения и грабли
bucket_count нельзя поменять после бутстрапа. Заложите запас сразу: люди ставят 3k бакетов, а потом каждый бакет распухает до гигабайта, и ребалансировать становится невозможно нормально.
- Router на каждом storage-узле - технически можно, но на проде категорически не рекомендуется: это разные по профилю нагрузки роли, селите их раздельно.
- bucket_id_strcrc32 для чисел из FFI - вернёт разные бакеты для 123, 123LL, 123ULL. Берите bucket_id_mpcrc32. И не передавайте cdata как bucket_id в call (в свежих версиях это вообще запрещено).
- Уникальность вторичного индекса в шардируемом спейсе гарантируется только в пределах одного шарда, не глобально.
- SELECT в хранимке выполняется локально: storage не знает маппинга bucket_id -> primary key, поэтому распределённые выборки без bucket_id - это map-reduce по всем шардам (за этим обычно идут в модуль crud).
- TRANSFER_IS_IN_PROGRESS - не баг: бакет переезжает, запрос надо просто повторить.
- pin != lock: lock прячет весь replica set от ребалансировщика; pin фиксирует один бакет. Запинить все бакеты не равно залочить шард - незалоченный шард всё равно может принимать новые бакеты.
На любом запущенном инстансе с установленным vshard выполните в консоли и сравните результаты:
Код: Выделить всё
local vshard = require('vshard')
print(vshard.router.bucket_id_mpcrc32(123))
print(vshard.router.bucket_id_mpcrc32(123ULL))
print(vshard.router.bucket_id_strcrc32(123))
print(vshard.router.bucket_id_strcrc32(123ULL))
Контрольные вопросы
- Зачем vshard вводит слой виртуальных бакетов вместо прямого hash(key) % число_узлов? Что это даёт при добавлении шарда?
- В каких двух местах хранится bucket id и как это обеспечивает консистентность при ребалансировке и failover?
- Что произойдёт, если выставить вес replica set в 0? А если число бакетов выбрали слишком маленьким?
- Почему распределённый SELECT без bucket_id превращается в опрос всех шардов, а DML через vshard.router.call - нет?