
Движок memtx держит все данные в оперативной памяти, и от того, как устроено управление этой памятью, зависят пределы по объёму, фрагментация и стабильность под нагрузкой. В этом уроке мы разберём память memtx сверху вниз: общий quota и arena, slab-аллокатор для нарезки крупных блоков, small-аллокатор для кортежей и отдельный аллокатор matras для индексов. Цель - чтобы вы понимали, куда уходит каждый байт и что показывают цифры в box.slab.info().
Иерархия памяти memtxКлючевая мысль: в memtx есть НЕ один аллокатор, а целая иерархия. Кортежи и индексы живут в разной памяти, и считаются они тоже по-разному.
Память выделяется уровнями, каждый следующий нарезает блоки предыдущего на более мелкие куски.
1. Quota - это глобальный лимит на память под данные memtx. Задаётся параметром memtx_memory (по умолчанию 256 МБ = 268435456 байт, минимум 32 МБ). Quota реализована как lock-free счётчик: ни один нижележащий аллокатор не получит память, если упрётся в этот потолок. Когда лимит достигнут, INSERT/UPDATE начинают падать с ошибкой ER_MEMORY_ISSUE. Лимит можно поднять на лету, но НЕ уменьшить.
2. Slab arena - выделяет у ОС крупные выровненные блоки (слабы) фиксированного размера. В memtx размер слаба MEMTX_SLAB_SIZE = 4 МБ. Arena предвыделяет память кусками в рамках quota, кэширует освобождённые слабы в lock-free LIFO-стеке и переиспользует их.
3. Slab cache - надстройка над arena, которая умеет резать 4-мегабайтный слаб на слабы меньшего размера степенями двойки (buddy-система). Из него питаются small-аллокатор (кортежи) и mempool (индексы).Важно: arena НИКОГДА не возвращает память операционной системе. Освобождённый слаб остаётся в кэше arena до перезапуска процесса. Поэтому RSS процесса после пиковой нагрузки не уменьшится - это не утечка, это дизайн.
4. Small allocator - аллокатор кортежей. Это и есть значение small у параметра memtx_allocator (по умолчанию). Внутри он держит набор пулов (mempool), каждый под свой класс размера. Запрос на N байт округляется вверх до ближайшего класса, объект берётся из соответствующего пула. Один слаб пула нарезан на ячейки одного размера - отсюда название slab allocator.
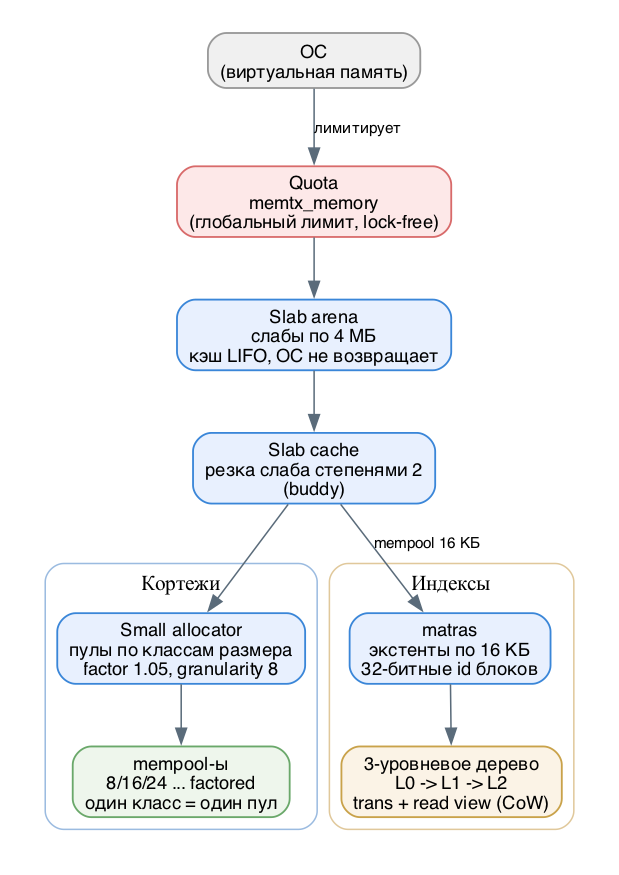
Иерархия памяти memtx: quota, arena, small и matras
Как small подбирает класс размера
Маленькие классы идут с шагом slab_alloc_granularity (по умолчанию 8 байт, должен быть степенью двойки и >= 4): 8, 16, 24, 32 ... Это stepped-пулы. Дальше, чтобы не плодить тысячи классов, размеры растут геометрически с множителем slab_alloc_factor (по умолчанию 1.05, диапазон 1..2): это factored-пулы. Множитель 1.05 значит, что каждый следующий класс примерно на 5 процентов больше предыдущего.
Код: Выделить всё
Запрос 40 байт -> класс 40 -> пул A (шаг 8)
Запрос 41 байт -> класс 48 -> пул B (7 байт overhead)
Запрос 1000 байт -> класс ~1024 -> пул из factored-зоны
Запрос 1100 байт -> класс ~1075..1129 (следующий по factor 1.05)
Matras: память под индексы
Индексы (деревья TREE, хэши HASH) живут в ОТДЕЛЬНОЙ памяти, выделяемой через matras (Memory Address TRAnSlation). Это аллокатор фиксированных блоков-экстентов размером MEMTX_EXTENT_SIZE = 16 КБ. Экстенты он берёт из mempool поверх того же slab cache, так что общая arena у кортежей и индексов одна.
Зачем нужен отдельный механизм. Matras выдаёт не просто указатель, а 32-битный целочисленный идентификатор блока, а сам адрес транслирует через трёхуровневое дерево (своего рода TLB в userspace): корневой блок L0 хранит указатели на экстенты L1, те - на L2, а уже L2 содержит сами блоки данных. Это даёт две вещи:
- Стабильные id вместо абсолютных адресов - удобно для компактных ссылок внутри индекса.
- Версионирование (read views). При создании снапшота индекс вызывает matras_create_read_view(). Дальше работает copy-on-write: пока фоновый поток пишет снапшот по согласованному снимку, изменённые экстенты копируются, а старые версии остаются видны read view. Поэтому во время box.snapshot() потребление памяти под индексы может временно вырасти.
Команды и наблюдаемость
Код: Выделить всё
-- агрегированный отчёт по всей arena
box.slab.info()
--[[ ключевые поля:
quota_size лимит = memtx_memory
quota_used занято под slab cache
arena_size выделено под кортежи + индексы
arena_used реально используется
items_size выделено только под кортежи
items_used используется только кортежами
*_ratio три коэффициента заполнения
]]
-- разбивка по классам размера (пулам)
box.slab.stats()
-- mem_used/mem_free/item_size/slab_count по каждому классу
-- сколько памяти под индексы конкретного спейса
box.space.my_space.index[0]:bsize()
box.space.my_space:bsize() -- под кортежи спейса
Код: Выделить всё
groups:
default:
replicasets:
rs-1:
instances:
storage-1: {}
memtx:
memory: 1073741824 # quota, 1 GB
allocator: small # small | system
slab_alloc_factor: 1.05
slab_alloc_granularity: 8
min_tuple_size: 16
max_tuple_size: 1048576
Код: Выделить всё
box.cfg{
memtx_memory = 1073741824,
memtx_allocator = 'small',
slab_alloc_factor = 1.05,
slab_alloc_granularity = 8,
}
- memtx_memory ограничивает всю память Tarantool - нет. Это лимит ТОЛЬКО на arena (кортежи + индексы). Сетевые буферы, fiber-стеки, Lua-heap, метаданные живут вне quota. Реальный RSS процесса всегда заметно больше memtx_memory.
- Высокий quota_used_ratio = пора паниковать - не обязательно. Опасно, когда ОДНОВРЕМЕННО высоки и quota_used_ratio, и arena_used_ratio, и items_used_ratio. Если items_used_ratio в районе 0.5..0.9 при высоком quota - это фрагментация: много классов размера, в каждом слабе мало занятых ячеек.
- Уменьшил memtx_memory - освободил память - параметр динамический только в сторону увеличения. Уменьшить нельзя, и arena всё равно не отдаст слабы ОС.
- Small всегда лучше - на нагрузках с дрейфом размеров (кортежи постепенно растут, миграция между классами) small подвержен неустранимой фрагментации: старые пулы держат пустые слабы, которые нельзя переиспользовать под другой класс. В таких случаях помогает memtx_allocator = system (на базе malloc) - он гибче по фрагментации, но без преимуществ пулов.
- Снапшот не ест память - ест. Read view + copy-on-write в matras на время box.snapshot() увеличивают потребление под индексы.
- Память кончилась внезапно при свободной quota - классический эффект фрагментации: новый кортеж требует слаб нового класса, свободных слабов в arena нет, попытка добрать quota упирается в потолок -> ER_MEMORY_ISSUE.
Поднимите инстанс с небольшим лимитом и понаблюдайте за работой пулов.
Код: Выделить всё
box.cfg{ memtx_memory = 64 * 1024 * 1024 }
box.schema.space.create('t')
box.space.t:create_index('pk')
-- снимем базовую картину
local before = box.slab.info()
-- зальём 50k кортежей разного размера
for i = 1, 50000 do
box.space.t:insert{ i, string.rep('x', i % 200 + 10) }
end
print('arena_used MB:', box.slab.info().arena_used / 1024 / 1024)
print('items_used_ratio:', box.slab.info().items_used_ratio)
-- сколько классов размера задействовано
print('число пулов:', #box.slab.stats())
Контрольные вопросы
- Почему RSS процесса Tarantool не падает после того, как вы удалили половину кортежей и вызвали сборку? Какой уровень иерархии за это отвечает?
- Чем выделение кортежа (small) отличается от выделения узла индекса (matras) - по размеру блока, по способу адресации и по поддержке read view?
- items_used_ratio = 0.6, quota_used_ratio = 0.95. Что это означает и какое действие корректно: поднять memtx_memory, сменить аллокатор или ничего не делать?
- Как slab_alloc_factor и slab_alloc_granularity влияют на число классов размера и на overhead на кортеж? В какую сторону их крутить, если все кортежи примерно одного небольшого размера?