
DRBD (Distributed Replicated Block Device) решает задачу, которую не закрывает обычный RAID: он зеркалит блочное устройство не на соседний диск, а на диск другого сервера через сеть. По сути это сетевой RAID-1 уровня ядра. Администратору это нужно там, где надо держать одни и те же данные синхронно на двух (а в DRBD 9 и больше) узлах, чтобы при падении одного второй мгновенно подхватил сервис без потери записей. В этом уроке разберём протоколы репликации A/B/C, настройку через drbdadm, первую синхронизацию и роли primary/secondary, связку с Pacemaker для автопереключения, управление парком ресурсов через LINSTOR и, главное, как выходить из split-brain.
Как это работает
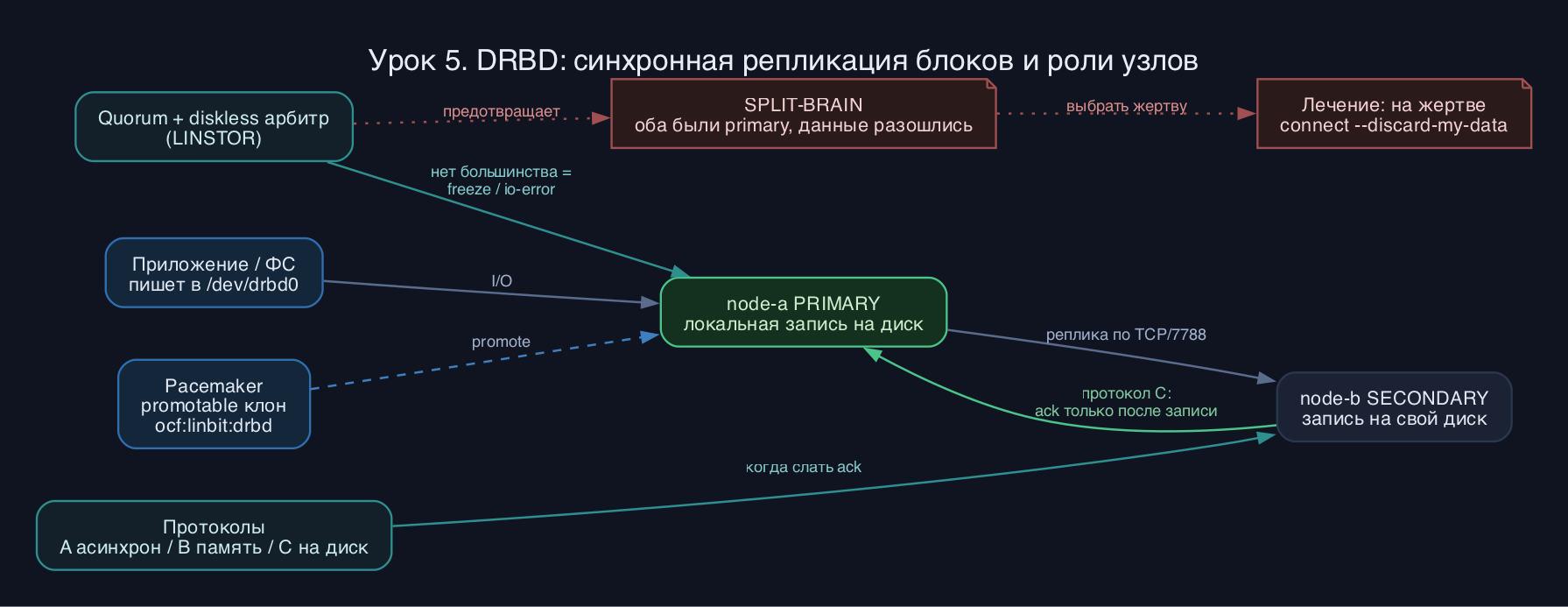
DRBD вклинивается между файловой системой и реальным диском. Приложение пишет в устройство /dev/drbd0, модуль ядра дублирует запись: одну копию на локальный backing device, вторую отправляет по TCP (или RDMA) на узел-партнёр. Когда удалённый узел подтвердил запись, DRBD сообщает приложению, что блок сохранён. Насколько рано приходит это подтверждение - и определяет протокол.
Протокол A (асинхронный): локальная запись завершена, как только данные ушли в TCP-буфер отправки. Быстро, но при падении узла данные из буфера теряются. Годится для репликации на дальние плечи, где задержка велика. Протокол B (полусинхронный, memory-synchronous): подтверждение приходит, когда пакет принят удалённым ядром, но ещё не лёг на его диск. Компромисс, используется редко. Протокол C (синхронный): запись считается завершённой только после того, как партнёр записал блок на свой диск. Это единственный режим с настоящей гарантией - данные есть на обоих узлах. В кластерах высокой доступности применяют почти исключительно C.
В DRBD 9 ушла главная боль восьмёрки: появился механизм quorum. Узел сам себя демонтирует из primary (замораживает или сбрасывает I/O), если теряет большинство голосов. Это убивает причину split-brain в зародыше, а не лечит последствия. LINSTOR при создании ресурса с двумя репликами по умолчанию доставляет третью бездисковую (diskless) реплику-арбитра, чтобы кворум был нечётным.
Split-brain - это ситуация, когда оба узла побывали primary независимо, у каждого свои изменения, и DRBD после восстановления связи отказывается сливать данные автоматически: он не знает, чьи записи важнее. Лечится выбором жертвы, чьи изменения выкидываются.
Команды и примеры
Установка. Debian 13 / Ubuntu 24.04:
Код: Выделить всё
apt install drbd-utils
modprobe drbdКод: Выделить всё
dnf install drbd-utils kmod-drbd
modprobe drbdКод: Выделить всё
resource r0 {
protocol C;
net {
verify-alg sha256;
# после split-brain в роли primary/secondary - откатить secondary
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
options {
quorum majority;
on-no-quorum io-error;
}
on node-a {
device /dev/drbd0;
disk /dev/vg0/lv_data;
address 10.0.0.1:7788;
meta-disk internal;
}
on node-b {
device /dev/drbd0;
disk /dev/vg0/lv_data;
address 10.0.0.2:7788;
meta-disk internal;
}
}Код: Выделить всё
drbdadm create-md r0
drbdadm up r0
drbdadm status r0Код: Выделить всё
drbdadm primary --force r0Код: Выделить всё
mkfs.ext4 /dev/drbd0
mount /dev/drbd0 /mnt/dataКод: Выделить всё
# на бывшем primary
umount /mnt/data
drbdadm secondary r0
# на втором узле
drbdadm primary r0
mount /dev/drbd0 /mnt/dataКод: Выделить всё
pcs resource create drbd_r0 ocf:linbit:drbd drbd_resource=r0 \
op monitor interval=20s role=Promoted \
op monitor interval=30s role=Unpromoted
pcs resource promotable drbd_r0 promoted-max=1 promoted-node-max=1 \
clone-max=2 clone-node-max=1 notify=trueLINSTOR. Когда ресурсов десятки, .res-файлы руками не ведут. LINSTOR - это управляющий слой: controller хранит описание, satellite на каждом узле дёргает drbdadm. Базовый поток:
Код: Выделить всё
linstor node create node-a 10.0.0.1
linstor storage-pool create lvm node-a pool0 vg0
linstor resource-definition create db
linstor volume-definition create db 50G
linstor resource create db --auto-place 2Код: Выделить всё
drbdadm secondary r0
drbdadm connect --discard-my-data r0Код: Выделить всё
drbdadm connect r0Частые грабли
- Запустить mkfs или mount на узле в роли secondary - устройство там read-only и недоступно, файловую систему монтируют только на primary.
- Дать обоим узлам primary --force в ходе первой синхронизации - получите искусственный split-brain на ровном месте. Эталон форсируют только на одном.
- Оставить drbd под управлением systemd при работе с Pacemaker - кластер и init подерутся за роли, ресурс будет флапать.
- Понадеяться на after-sb-* как на защиту. Это политики автослияния уже СЛУЧИВШЕГОСЯ split-brain, и они могут молча выкинуть нужные данные. Реальная защита - quorum и фенсинг.
- allow-two-primaries без кластерной ФС (GFS2/OCFS2) поверх - две обычные ext4-записи разнесут данные в труху.
- Несовпадающие .res-файлы на узлах или забытый firewall на порту 7788 - ресурс не соединится, висит в WFConnection.
- Внутренние метаданные (meta-disk internal) съедают место в конце backing-устройства. Если LV занят данными под завязку, create-md не разместит метаданные.
- Поднимите две ВМ (node-a, node-b), на каждой выделите LV одинакового размера в vg0.
- Установите drbd-utils, напишите идентичный /etc/drbd.d/r0.res с протоколом C и quorum majority.
- Выполните create-md и up на обоих, проверьте drbdadm status - должно быть Inconsistent/Inconsistent.
- На node-a сделайте primary --force, дождитесь UpToDate, создайте ext4 и запишите файл.
- Переключите роли вручную (secondary на A, primary на B), убедитесь, что файл виден на B.
- Спровоцируйте split-brain: оборвите сеть между узлами и сделайте обоих primary, затем верните сеть и разрулите через discard-my-data.
- Соберите Pacemaker-кластер с promotable-клоном drbd_r0 и проверьте автоперенос роли при standby узла.
- Чем гарантия протокола C отличается от A и B, и почему именно C берут в HA-кластеры?
- Что произойдёт с I/O на primary, если задан quorum majority и on-no-quorum io-error, а узел потерял связь с большинством?
- Какую роль играет diskless-реплика, которую LINSTOR добавляет по умолчанию к двум репликам?
- Почему drbd нужно убрать из автозапуска systemd при управлении через Pacemaker, и кто тогда меняет роли?
- Чем отличаются действия на узле-жертве и на узле-выжившем при ручном разрешении split-brain?
- Что делает promotable-клон ocf:linbit:drbd и зачем ему параметры promoted-max и notify=true?

