
В прошлой части вы собрали кластер и поняли, что снизу всё держится на RADOS - объектном хранилище с OSD, мониторами и алгоритмом CRUSH. Теперь задача администратора - выдать это хранилище потребителям в привычном им виде и научиться кластер обслуживать. В этом уроке разберём три интерфейса доступа: RBD (блочные устройства для виртуалок и баз), CephFS (POSIX файловая система с метаданными) и RADOS Gateway (S3 и Swift поверх RADOS). Дальше - как cephadm разворачивает и масштабирует кластер контейнерами, как добавить OSD на новый диск, как читать ceph status и health, и как работают балансировка размещения и восстановление после потери диска. Актуально на лето 2026: текущий стабильный релиз - Tentacle (20.x), предыдущий - Squid (19.x), оба ставятся через cephadm на systemd и контейнеры (podman или docker).
Как это работает
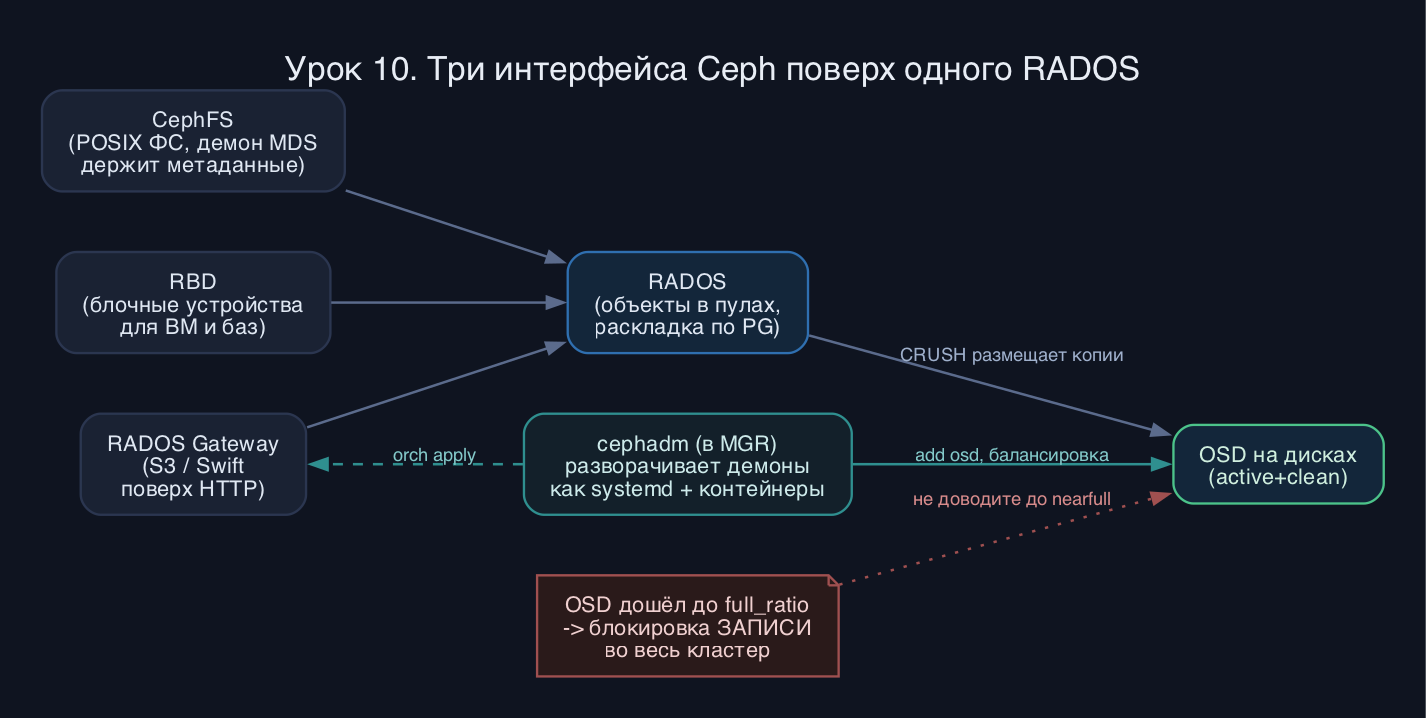
RADOS хранит объекты, но приложениям нужны блоки, файлы и бакеты. Поэтому над RADOS живут три библиотеки-трансляторы, и все три по сути нарезают данные на объекты внутри пулов.
RBD режет виртуальный диск на куски (по умолчанию 4 МБ) и раскладывает их объектами по PG, которые CRUSH распределяет по OSD. Образ - это просто набор объектов плюс заголовок. Снапшоты и клоны делаются через copy-on-write: клон ссылается на родителя и пишет только изменённые объекты. Отсюда мгновенное создание тысячи виртуалок из одного золотого образа.
CephFS добавляет к данным слой метаданных. Содержимое файлов лежит в пуле данных как объекты, а дерево каталогов, права и имена обслуживает отдельный демон MDS, который держит горячие метаданные в памяти и журналирует их в свой пул. MDS может масштабироваться: несколько активных демонов делят дерево на поддеревья. Клиент монтирует ФС родным модулем ядра или через FUSE и держит capabilities - что-то вроде распределённых блокировок на чтение и запись.
RADOS Gateway (RGW, демон radosgw) - это HTTP-сервер, говорящий на диалектах S3 и Swift. Он раскладывает пользователей, бакеты и объекты по служебным пулам, а большие объекты бьёт на части. Поверх можно строить мультисайт - асинхронную репликацию бакетов между географически разнесёнными зонами.
Связывает всё cephadm. Это менеджер-оркестратор внутри демона MGR: он по SSH ходит на хосты, тянет образ контейнера и поднимает каждый демон как отдельный systemd-юнит. Вы описываете желаемое состояние через сервис-спеки, а cephadm приводит кластер к нему. Это и есть современный путь развёртывания в 2026 - ручная раскладка через ceph-deploy осталась в прошлом и для экзамена упоминается как легаси.
Команды и примеры
Bootstrap первого узла. Пакет cephadm ставится из репозитория дистрибутива или curl-ом с adddistro:
Код: Выделить всё
# Debian 13 / Ubuntu 24.04
apt install -y cephadm ceph-common
# RHEL 10 / Fedora 41+
dnf install -y cephadm ceph-common
cephadm bootstrap --mon-ip 10.0.0.11
# поднимает MON, MGR, дашборд и выдаёт логин; дальше работаем через ceph orch
Код: Выделить всё
ceph orch host add ceph-node2 10.0.0.12
ceph orch device ls # какие диски видит оркестратор
ceph orch daemon add osd ceph-node2:/dev/sdb # один диск явно
ceph orch apply osd --all-available-devices # забрать все чистые диски автоматом
Код: Выделить всё
ceph osd pool create rbdpool 128
rbd pool init rbdpool
rbd create rbdpool/disk1 --size 20G
rbd ls -l rbdpool
rbd map rbdpool/disk1 # появится /dev/rbd0
mkfs.ext4 /dev/rbd0 && mount /dev/rbd0 /mnt/vol
rbd snap create rbdpool/disk1@before-upgrade
Код: Выделить всё
ceph fs volume create shared # создаст пулы cephfs.shared.data/.meta и MDS
ceph fs status shared
mount -t ceph admin@.shared=/ /mnt/cephfs -o secret=AQ... # ядерный клиент
# или: ceph-fuse /mnt/cephfs --client_mds_namespace=shared
Код: Выделить всё
ceph orch apply rgw mysite --placement="2 ceph-node1 ceph-node2"
radosgw-admin user create --uid=alice --display-name="Alice" \
--access-key=AKIA... --secret-key=secret...
radosgw-admin bucket list
Код: Выделить всё
ceph status # сводка: health, мониторы, OSD, PG, ёмкость
ceph health detail # расшифровка каждого WARN/ERR
ceph osd tree # дерево CRUSH: какие OSD на каких хостах, веса
ceph osd df # заполнение по OSD, перекосы
ceph -w # живой поток событий кластера
ceph balancer status # режим автобалансировки размещения PG
ceph balancer mode upmap # точечный режим (по умолчанию в Tentacle/Squid)
Частые грабли
- ceph osd pool create без расчёта PG. Слишком мало PG - перекос заполнения OSD, слишком много - лишняя нагрузка на память и CPU мониторов. В современных релизах включайте autoscaler (ceph osd pool set pool pg_autoscale_mode on) и задавайте target_size, а не подбирайте число руками.
- rbd map старого образа на свежем ядре падает на feature mismatch. Ядерный клиент не тянет некоторые фичи RBD (например object-map). Либо отключите их при создании, либо мапьте через rbd-nbd или krbd новее.
- CephFS с одним MDS без standby. Упал активный MDS - ФС встала. Всегда держите хотя бы один standby (ceph orch apply mds shared 2) или standby-replay.
- nearfull/full. Когда OSD доходит до full_ratio, кластер блокирует запись целиком, а не только на переполненном диске - это защита от потери данных. Реагируйте уже на nearfull, не дожидаясь stop.
- Убрать OSD выдёргиванием диска. Правильно - ceph orch osd rm с дренажом, чтобы данные ушли заранее. Резкое out на нескольких OSD сразу запускает массовый бэкфилл и может уронить производительность.
- Дисбаланс из-за разных весов. После добавления диска другого объёма CRUSH-веса разъезжаются. Проверяйте ceph osd df и доверяйте балансировщику в режиме upmap, а не правьте reweight вручную без нужды.
- Перепутать пулы реплик и erasure coding. EC экономит место, но дороже по CPU и хуже на мелких случайных записях - под базы и RBD чаще берут реплику 3, под холодные бакеты RGW - EC.
- На собранном в прошлом уроке кластере добавьте второй хост через ceph orch host add и заберите его чистый диск под OSD командой ceph orch daemon add osd.
- Проверьте, что новый OSD виден в ceph osd tree, и понаблюдайте через ceph -w, как кластер ребалансит PG (состояния backfilling/remapped).
- Создайте пул rbdpool, в нём образ на 10G, смапьте его, сделайте ext4, смонтируйте и запишите файл; затем снимите снапшот rbd snap create.
- Создайте CephFS через ceph fs volume create, поднимите второй MDS как standby и смонтируйте ФС ядерным клиентом.
- Разверните RGW через ceph orch apply rgw, заведите S3-пользователя radosgw-admin и проверьте доступ любым S3-клиентом (s3cmd или aws cli с endpoint-url).
- Сымитируйте отказ: остановите один OSD (ceph orch daemon stop osd.N), посмотрите HEALTH_WARN и ceph health detail, дождитесь recovery, затем верните демон и убедитесь в active+clean.
- Чем принципиально отличается путь данных RBD, CephFS и RGW, если все они в итоге пишут объекты в один и тот же RADOS?
- Зачем CephFS нужен отдельный демон MDS и почему его метаданные хранятся в собственном пуле, а не вместе с данными файлов?
- Как cephadm понимает, какие демоны должны работать на хостах, и через какой механизм он их запускает на каждом узле?
- Что показывают состояния PG active+clean, degraded и backfilling, и какое из них означает идущее восстановление, а какое - переезд данных?
- Почему достижение full_ratio на одном OSD блокирует запись во весь кластер, и как этого избежать заранее?
- В каких сценариях вы выберете пул с erasure coding, а в каких - реплику 3, и какой ценой даётся экономия места у EC?

