
Задача администратора тут двойная: размазать клиентские запросы по пулу одинаковых серверов и сделать так, чтобы падение одного бэкенда или самого балансировщика никто не заметил. В этом уроке разберём два мира. Первый - ядерный балансировщик LVS/IPVS на четвёртом уровне (он не вникает в содержимое пакета, только в адреса и порты). Второй - HAProxy, который умеет и L4, и L7 (читает HTTP, маршрутизирует по URL и заголовкам). Между ними - keepalived с протоколом VRRP, который делает сам балансировщик отказоустойчивым через плавающий IP.
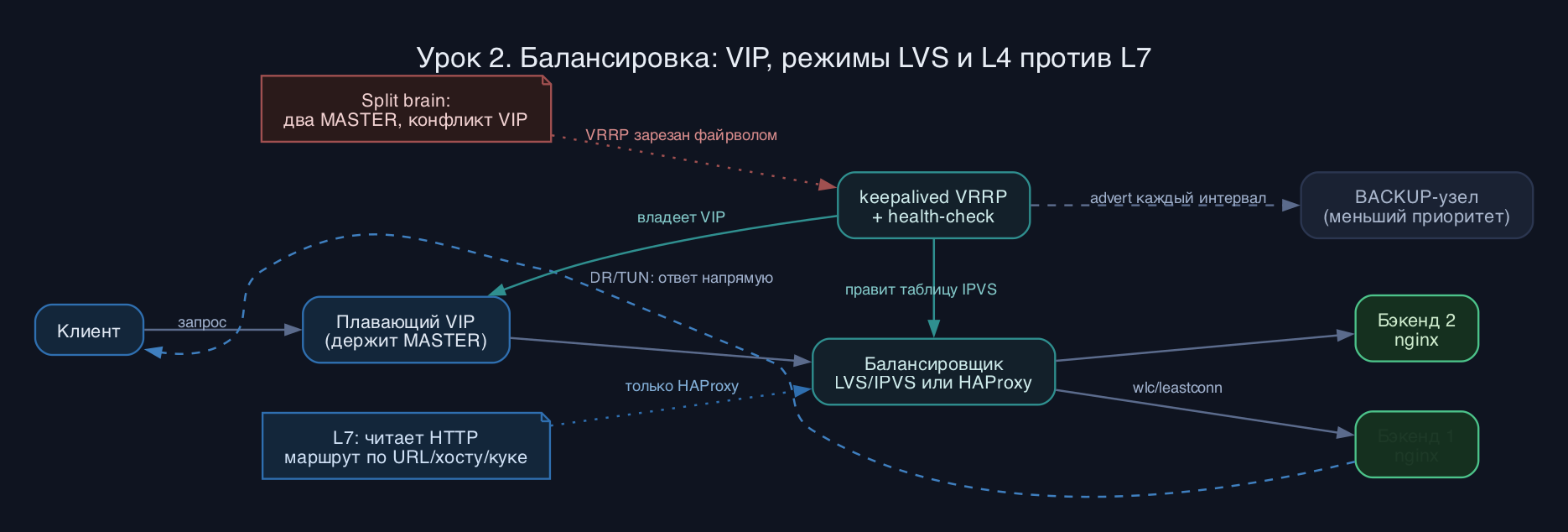
Как это работает
IPVS живёт внутри ядра Linux как часть netfilter. Вы описываете виртуальный сервис - пару "виртуальный IP плюс порт" (VIP) - и привязываете к нему набор реальных серверов. Дальше ядро само раскидывает соединения, держа таблицу состояний, чтобы пакеты одного TCP-потока шли на один и тот же бэкенд. Управляется это таблицей через утилиту ipvsadm, конфигурация чисто in-kernel, без своего демона.
Ключевое в LVS - три режима пересылки. NAT (masq): балансировщик подменяет адрес назначения, и ответный трафик обязан идти обратно через него, поэтому он становится шлюзом для бэкендов и узким горлом по пропускной способности. DR (direct routing): балансировщик меняет только MAC-адрес кадра, пакет уходит на реальный сервер в том же L2-сегменте, а ответ идёт клиенту НАПРЯМУЮ, минуя балансировщик. Это самый быстрый режим, но требует, чтобы VIP висел на loopback каждого бэкенда и тот не отвечал на ARP по нему. TUN (туннелирование): пакет заворачивается в IPIP, поэтому бэкенды могут стоять в другой подсети или даже другом ЦОДе, ответ тоже идёт напрямую клиенту.
Алгоритмы распределения: rr (по кругу), wrr (по кругу с весами), lc (наименьшее число соединений), wlc (то же с весами - дефолт на практике), а также sh (хэш по source IP для липкости без таблицы) и mh (maglev-хэш, консистентный, появился в современных ядрах). Сам IPVS не проверяет здоровье бэкендов - для этого нужен внешний демон: keepalived или ldirectord. Они опрашивают реальные серверы и вынимают мёртвый узел из таблицы IPVS, а потом возвращают.
keepalived делает две вещи. Во-первых, VRRP: несколько балансировщиков выбирают MASTER по приоритету, и тот держит плавающий VIP. Если MASTER молчит (нет VRRP-advert в течение трёх интервалов), BACKUP с наибольшим приоритетом забирает VIP за секунды. Во-вторых, healthcheck-модуль программирует IPVS и следит за бэкендами (TCP_CHECK, HTTP_GET, MISC_CHECK). ldirectord - более старый перловый демон только для второй задачи (мониторинг + правка IPVS), в 2026 это легаси: на новых стендах берут keepalived, ldirectord держат только для совместимости со старыми кластерами Pacemaker.
HAProxy работает в user space и принимает соединение на себя целиком. Вы описываете frontend (где слушать) и backend (куда слать), а между ними - правила. На L7 он терминирует TCP, читает HTTP и может балансировать по пути, хосту, куке, делать sticky-сессии, повторять запросы, вставлять заголовки. Алгоритмы: roundrobin, leastconn, source (хэш IP), uri, hdr. Health-checks активные (option httpchk) и пассивные (observe). Встроенная страница статистики показывает состояние каждого сервера в реальном времени.
L4 против L7 коротко: L4 (IPVS, режим tcp в HAProxy) быстрый, дёшев по CPU, но слеп к содержимому - не различит /api от /static. L7 видит запрос целиком, умна маршрутизация и TLS-терминация, но платит CPU за разбор каждого запроса.
Команды и примеры
Установка. Debian 13 / Ubuntu 24.04:
Код: Выделить всё
apt install ipvsadm keepalived haproxyКод: Выделить всё
dnf install ipvsadm keepalived haproxyКод: Выделить всё
ipvsadm -A -t 203.0.113.10:80 -s wlc
ipvsadm -a -t 203.0.113.10:80 -r 10.0.0.21:80 -g -w 3
ipvsadm -a -t 203.0.113.10:80 -r 10.0.0.22:80 -g -w 1
ipvsadm -L -n --statsКод: Выделить всё
ipvsadm-save -n > /etc/ipvsadm.rules
ipvsadm-restore < /etc/ipvsadm.rulesКод: Выделить всё
ip addr add 203.0.113.10/32 dev lo
sysctl -w net.ipv4.conf.all.arp_ignore=1
sysctl -w net.ipv4.conf.all.arp_announce=2Код: Выделить всё
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 150
advert_int 1
authentication { auth_type PASS; auth_pass s3cret }
virtual_ipaddress { 203.0.113.10/24 dev eth0 }
}
virtual_server 203.0.113.10 80 {
delay_loop 5
lb_algo wlc
lb_kind DR
protocol TCP
real_server 10.0.0.21 80 {
weight 3
HTTP_GET { url { path /health; status_code 200 } connect_timeout 2 }
}
real_server 10.0.0.22 80 {
weight 1
TCP_CHECK { connect_timeout 2 }
}
}Код: Выделить всё
systemctl enable --now keepalived
journalctl -u keepalived -f
ip -br addr show eth0Код: Выделить всё
frontend web
bind 203.0.113.10:80
default_backend app
backend app
balance leastconn
option httpchk GET /health
http-check expect status 200
server a 10.0.0.21:80 check weight 3
server b 10.0.0.22:80 check weight 1 backup
listen stats
bind 127.0.0.1:9000
stats enable
stats uri /haproxy?stats
stats refresh 5sКод: Выделить всё
haproxy -c -f /etc/haproxy/haproxy.cfg
systemctl reload haproxy- DR-режим не работает, пока на бэкендах не погашен ARP по VIP - иначе они начинают отвечать на ARP-запросы и крадут трафик у балансировщика.
- В NAT-режиме забыли назначить балансировщик шлюзом по умолчанию для бэкендов - ответный трафик уходит мимо, соединения зависают.
- Два MASTER одновременно (split brain): VRRP-адверты режутся файрволом или несовпадает virtual_router_id - оба узла поднимают VIP, в сети конфликт. Проверяйте, что nftables/firewalld пропускает протокол 112 (VRRP) и multicast 224.0.0.18.
- Сам IPVS не знает, жив ли бэкенд. Без keepalived или ldirectord мёртвый сервер остаётся в таблице, и часть запросов улетает в никуда.
- HAProxy без явного option httpchk делает только TCP-connect: процесс слушает порт, но приложение отдаёт 500 - балансировщик этого не заметит.
- Путаница restart и reload у HAProxy: restart рвёт все соединения, нужен reload (или master-worker режим) для бесшовной выкатки.
- Модуль ip_vs не загружен в ядре - ipvsadm выдаёт пустоту. Подгрузите modprobe ip_vs и нужный алгоритм (ip_vs_wlc).
- Поднимите три ВМ: один балансировщик (LB1) и два бэкенда с nginx, отдающим разный текст на /health и на /.
- На LB1 настройте IPVS в режиме NAT через ipvsadm, бэкенды переведите шлюзом на LB1. Проверьте балансировку через curl в цикле.
- Снесите ручные правила и поднимите keepalived с тем же virtual_server, но healthcheck HTTP_GET на /health. Погасите nginx на одном бэкенде и убедитесь, что keepalived вынул его из ipvsadm -L -n.
- Добавьте LB2 как BACKUP с меньшим приоритетом. Остановите keepalived на LB1 и засеките, за сколько VIP переедет на LB2 (смотрите ip addr и journalctl).
- Отдельно поднимите HAProxy на L7: frontend на 80 порту, backend с option httpchk, один сервер пометьте backup.
- Откройте страницу статистики и понаблюдайте, как сервер переходит в DOWN при остановке приложения и обратно в UP.
- Сравните в выводе ipvsadm и в статистике HAProxy, чем отличается распределение при leastconn и при roundrobin под нагрузкой ab или wrk.
- Чем DR-режим LVS отличается от NAT по пути ответного трафика и какие требования к сети накладывает каждый?
- Какой компонент в связке LVS отвечает за проверку здоровья реальных серверов и почему сам IPVS этого не делает?
- Как VRRP в keepalived определяет, что MASTER упал, и за счёт чего происходит переезд плавающего IP?
- В каких ситуациях L7-балансировка HAProxy оправдывает дополнительную нагрузку на CPU по сравнению с L4?
- Чем грозит и из-за чего возникает ситуация split brain при работе двух балансировщиков на VRRP?
- Чем отличается алгоритм sh (source hashing) в IPVS от wlc и когда выбирают первый?

