
Сервер тормозит, а пользователи пишут гневные тикеты - и задача администратора не угадать, а доказать цифрами, где именно затык: процессор, память, диск или сеть. В этом уроке мы разберём, какие метрики ядро Linux отдаёт наружу, как их читать инструментами из пакета sysstat и соседями (top, ss, lsof, iotop), и по какому алгоритму локализовать узкое место, не переустанавливая сервер наугад.
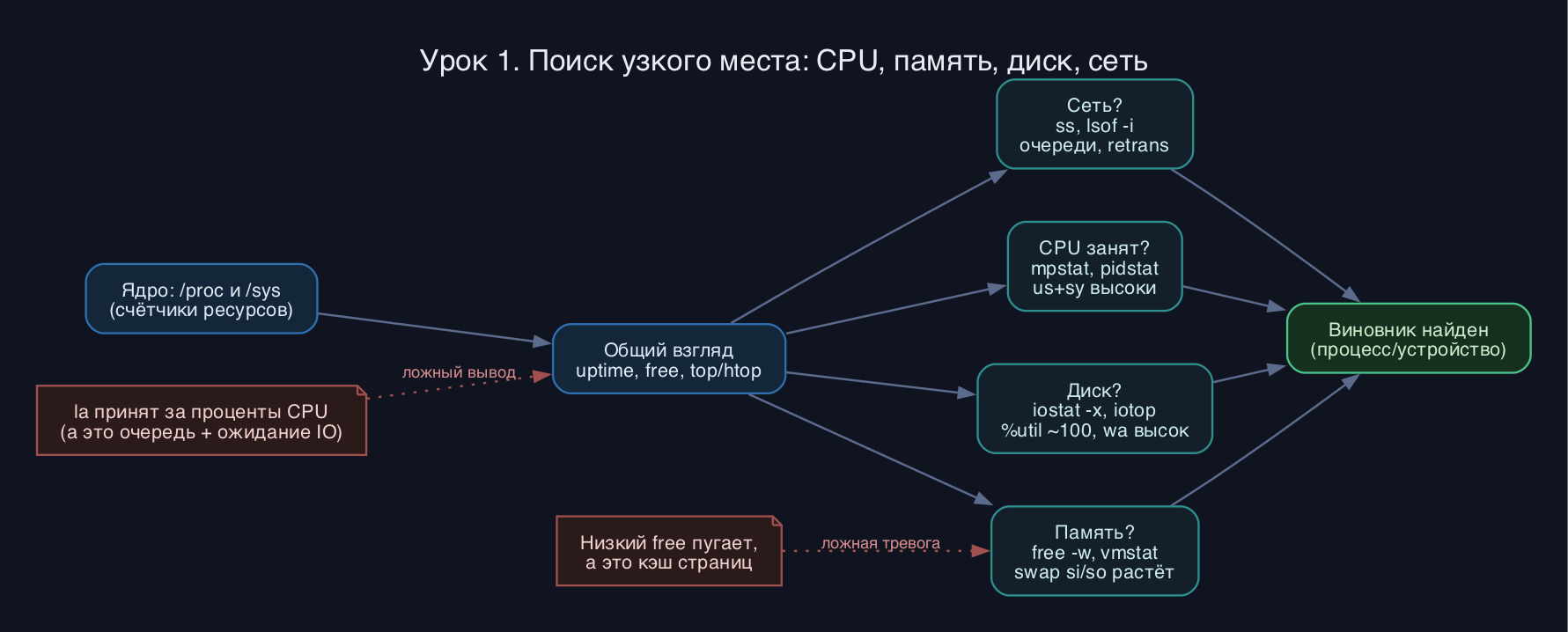
Как это работает
Ядро ведёт счётчики использования ресурсов и публикует их через виртуальные файловые системы /proc и /sys. Почти все утилиты мониторинга - это просто красивые читалки этих файлов. Например, load average берётся из /proc/loadavg, статистика по CPU - из /proc/stat, по памяти - из /proc/meminfo, а по конкретному процессу - из /proc/PID/. Понимание этого избавляет от магии: если утилита показала странное, можно пойти в первоисточник.
Ключевая идея диагностики - разделять моментальный снимок и динамику. top и free показывают состояние сейчас, а vmstat, iostat, mpstat с интервалом (например, каждые 2 секунды) показывают тренд. Первая строка вывода многих утилит sysstat - это среднее с момента загрузки, поэтому её почти всегда игнорируют и смотрят на последующие.
Load average - это не загрузка процессора в процентах, а среднее число процессов, которые работают или ждут (в Linux сюда входит и ожидание диска, состояние D - uninterruptible sleep). Три числа - среднее за 1, 5 и 15 минут. Если la выше числа ядер, очередь растёт. Но la=8 на 16-ядерной машине - это норма, а на 4-ядерной - перегрузка. Поэтому всегда делите la на nproc.
Для памяти важно не пугаться маленького свободного значения: Linux намеренно занимает свободную RAM под кэш страниц (buff/cache), чтобы ускорять чтение с диска. Реальный показатель нехватки памяти - это рост swap-активности (si/so в vmstat) и срабатывание OOM killer, а не низкий free.
Узкое место по вводу-выводу выдаёт колонка wa (iowait) в top/vmstat и параметр %util в iostat: если диск занят почти 100% времени и очередь к нему растёт, процессор простаивает в ожидании. Сетевой затык ищут через ss (состояния соединений, переполнение очередей accept) и счётчики ошибок интерфейсов.
Команды и примеры
Установка пакета sysstat - он даёт vmstat-соседей iostat, sar, mpstat, pidstat:
Код: Выделить всё
# Debian 13 / Ubuntu 24.04
sudo apt install sysstat
# RHEL 10 / Fedora 41+
sudo dnf install sysstat
# Включить фоновый сбор истории (sar)
sudo systemctl enable --now sysstat
Код: Выделить всё
uptime
free -h -w
Код: Выделить всё
vmstat 2 5
Код: Выделить всё
iostat -xh 2
Код: Выделить всё
mpstat -P ALL 2
Код: Выделить всё
pidstat 2 # CPU по процессам
pidstat -r 2 # память (minflt/majflt, RSS)
pidstat -d 2 # дисковый IO по процессам
Код: Выделить всё
sar -u 1 3 # CPU в реальном времени
sar -r -f /var/log/sysstat/sa13 # память за 13-е число месяца
Код: Выделить всё
ss -s # сводка по сокетам
ss -tlnp # TCP listen, без резолва, с процессами
ss -tin # детали TCP: rtt, cwnd, retrans
Код: Выделить всё
sudo lsof -i :443 # кто слушает/держит порт 443
sudo lsof /var/log/app.log # кто открыл файл
sudo iotop -oP # только активные, по процессам
Код: Выделить всё
htop
- Принимать load average за проценты загрузки CPU. Это длина очереди, и в неё входит ожидание диска - высокий la при простаивающем процессоре почти всегда означает проблему с IO, а не с CPU.
- Пугаться низкого free и докупать память, хотя её съел кэш страниц. Смотрите на колонку available в free, а не на free, и на swap-активность.
- Читать первую строку iostat/mpstat/pidstat как текущее значение - это среднее с момента загрузки. Реальные данные начинаются со второго интервала.
- Запускать iostat без -x и не видеть %util и await - без них невозможно отличить занятый диск от медленного.
- Забыть включить службу sysstat - тогда sar не накопит историю и разобрать ночной инцидент постфактум не выйдет.
- Путать iowait с нагрузкой на CPU: высокий %wa означает, что процессор простаивает в ожидании диска, а не работает.
- Использовать netstat по привычке - на минимальных образах его уже нет, нужен ss.
- Установите sysstat и включите службу сбора истории, проверьте, что появляются файлы в /var/log/sysstat (или /var/log/sa).
- Создайте искусственную нагрузку на CPU: запустите stress-ng --cpu 2 --timeout 30s (или yes > /dev/null в фоне на 2 терминала) и в другом окне смотрите mpstat -P ALL 2 - найдите загруженные ядра.
- Создайте нагрузку на диск: dd if=/dev/zero of=/tmp/testfile bs=1M count=2000 oflag=direct и параллельно смотрите iostat -xh 2 - зафиксируйте %util и await целевого устройства.
- Запустите pidstat -d 2 и убедитесь, что виновник записи - ваш процесс dd.
- Через ss -tlnp найдите все слушающие TCP-порты на стенде и через lsof -i :PORT определите процесс одного из них.
- Удалите тестовый файл, через sar -u и sar -b посмотрите, остался ли след нагрузки в истории.
- Из каких файлов /proc утилиты берут load average, статистику CPU и памяти?
- Чем колонка available в free принципиально отличается от free и почему именно её надо смотреть?
- Какие колонки vmstat и iostat указывают на узкое место по дисковому вводу-выводу?
- Почему первую строку вывода iostat и mpstat обычно игнорируют?
- Какой утилитой и как определить процесс, который генерирует основную дисковую запись?
- Чем ss лучше netstat и как через него увидеть переполнение accept-очереди сокета?

