
Диски умирают, и это не вопрос если, а вопрос когда. Программный RAID на Linux (подсистема md, multiple devices, управляемая утилитой mdadm) решает задачу администратора: пережить отказ одного или нескольких накопителей без простоя и потери данных, а заодно иногда выжать больше скорости. В этом уроке разберем, чем уровни RAID отличаются по надежности и цене, как собрать массив через mdadm, как читать его состояние через /proc/mdstat, как закрепить конфигурацию в mdadm.conf, и главное - что делать руками, когда диск отвалился среди ночи.
Как это работает
RAID объединяет несколько блочных устройств в одно логическое /dev/mdN. Дальше поверх него вы делаете файловую систему, LVM или раздел подкачки - md прозрачен для вышестоящих слоев. Вся логика распределения данных живет в ядре, а mdadm только отдает ядру команды и читает метаданные.
Уровни различаются тем, как md раскладывает данные. RAID 0 (striping) режет запись на полосы и пишет их по очереди на все диски: емкость суммируется, скорость растет, но отказоустойчивости ноль - умер один диск, потеряно все. RAID 1 (mirror) пишет одинаковые данные на каждый диск: переживает отказ всех дисков кроме одного, чтение можно параллелить, но полезная емкость равна размеру одного диска.
RAID 5 хранит данные плюс одну контрольную сумму (parity), размазанную по всем дискам: теряете емкость одного диска, переживаете отказ одного. RAID 6 держит две независимые суммы и переживает отказ сразу двух дисков ценой емкости двух. RAID 10 это зеркала, собранные в страйп: быстрый и надежный, но отдаете под избыточность половину емкости. Минимум дисков: 0 и 1 - два, 5 - три, 6 - четыре, 10 - четыре.
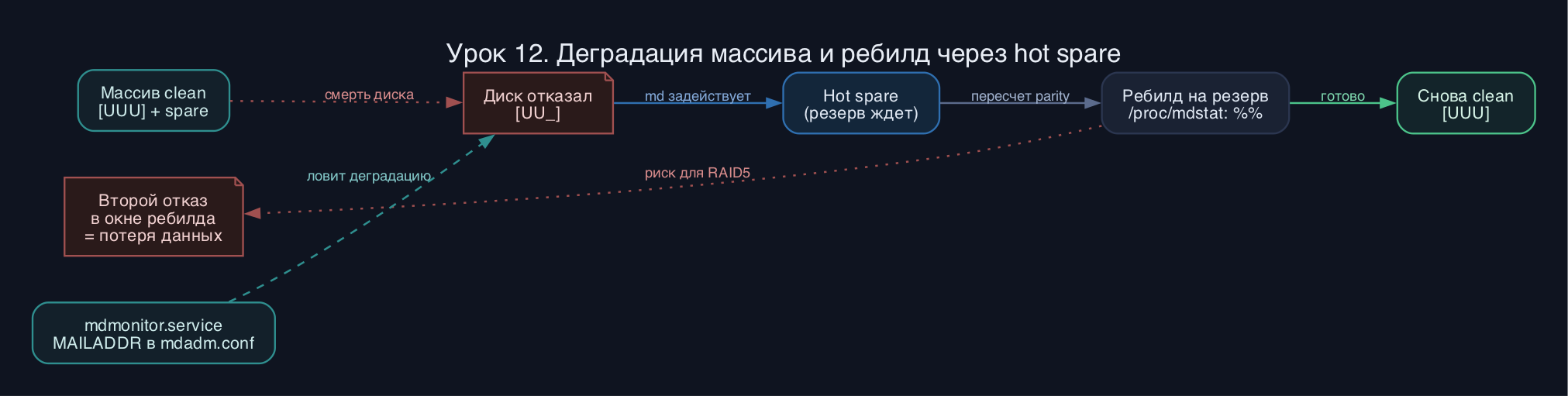
Ключевая опасность parity-массивов - окно ребилда. Пока RAID 5 после замены диска пересчитывает данные (часы на больших дисках), он не имеет избыточности, и второй отказ убьет массив. Поэтому на дисках от нескольких терабайт в 2026 берут RAID 6 или RAID 10, а не RAID 5.
Метаданные (суперблок) лежат на самих дисках в формате 1.2 по умолчанию - он пишется со смещением от начала, чтобы массив можно было собрать на любой машине просто по UUID, без привязки к именам устройств. Это важно: имена вроде /dev/sdb плавают между загрузками, а UUID массива постоянен.
Команды и примеры
Создание массива RAID 5 из трех дисков плюс горячий резерв:
Код: Выделить всё
mdadm --create /dev/md0 --level=5 --raid-devices=3 \
--spare-devices=1 /dev/sd[b-e]
Код: Выделить всё
cat /proc/mdstat
mdadm --detail /dev/md0
Сохраняем конфигурацию, иначе после перезагрузки массив может собраться под другим номером. Внимание на путь, он разный в двух семействах:
Код: Выделить всё
# Debian / Ubuntu
mdadm --detail --scan >> /etc/mdadm/mdadm.conf
update-initramfs -u
# RHEL / Fedora
mdadm --detail --scan >> /etc/mdadm.conf
dracut -f
Сборка существующего массива (после переноса дисков или ручной разборки):
Код: Выделить всё
mdadm --assemble --scan # по mdadm.conf
mdadm --assemble /dev/md0 /dev/sd[b-d]1 # вручную
mdadm --stop /dev/md0 # разобрать
Код: Выделить всё
mdadm --manage /dev/md0 --fail /dev/sdb
mdadm --manage /dev/md0 --remove /dev/sdb
# физически меняем диск, затем
mdadm --manage /dev/md0 --add /dev/sdf
Современный способ заменить диск, который еще жив, но сыпет ошибками, без потери избыточности на время ребилда:
Код: Выделить всё
mdadm /dev/md0 --add /dev/sdf
mdadm /dev/md0 --replace /dev/sdb --with /dev/sdf
Код: Выделить всё
mdadm --monitor --scan --test --oneshot
Код: Выделить всё
mdadm --grow /dev/md0 --bitmap=internal
- Забыли --detail --scan в mdadm.conf и регенерацию initramfs - после перезагрузки массив всплывает как /dev/md127, а fstab по старому имени отправляет систему в emergency shell.
- RAID не бэкап. Зеркало честно продублирует ваш rm -rf и поврежденную файловую систему на оба диска. Снапшоты и резервные копии все равно нужны.
- RAID 0 называют RAID, но избыточности там нет вообще. Один диск - и массив мертв целиком.
- Diski в массиве разного размера: md возьмет от каждого объем самого маленького, остальное пропадет.
- Hot spare есть, но почту никто не настроил. Диск отказал, резерв подхватился, второй отказал - и тишина, узнали только когда массив встал.
- Перепутали --assemble и --create. Повторный --create на живых дисках перепишет суперблоки и может уничтожить данные. Собирают только через --assemble.
- Ребилд RAID 5 на больших дисках длится часами под нагрузкой, и второй отказ в это окно фатален. Для крупных дисков выбирайте RAID 6 или 10.
- Создайте четыре loop-устройства по 512 МБ: dd if=/dev/zero of=/disk1.img bs=1M count=512 (повторите для 1..4), затем losetup -f --show /disk1.img на каждый.
- Соберите RAID 5 из трех loop-устройств с одним spare через mdadm --create, дождитесь окончания ресинка в /proc/mdstat.
- Создайте на /dev/md0 файловую систему, смонтируйте и запишите туда контрольный файл с известным содержимым.
- Запишите конфигурацию через mdadm --detail --scan в mdadm.conf вашего дистрибутива.
- Сымитируйте отказ: mdadm --fail на одно из устройств, посмотрите, как spare автоматически вступает в ребилд, и проверьте, что контрольный файл читается.
- Удалите сбойное устройство через --remove и добавьте обратно через --add, пронаблюдайте повторный ребилд.
- Остановите массив через --stop, затем соберите заново через --assemble --scan и убедитесь, что данные на месте.
- Сколько дисков минимум нужно для RAID 6 и сколько отказов он переживает одновременно?
- Чем --create принципиально опасен по сравнению с --assemble при работе с существующим массивом?
- В каком файле и какой строкой задается адрес для уведомлений о деградации, и какой демон их шлет?
- Что означает [UU_U] в выводе /proc/mdstat и где смотреть прогресс восстановления?
- Почему для дисков на несколько терабайт RAID 6 или 10 предпочтительнее RAID 5?
- Зачем после правки mdadm.conf нужно перегенерировать initramfs и какой командой это делают в Debian и в RHEL?

