
В первой части вы подняли кластер Corosync и убедились, что узлы видят друг друга и держат кворум. Теперь надо заставить кластер делать полезную работу: запускать сервисы, держать их ровно на одном узле, переносить при сбое и не разорвать данные надвое. Этот урок про то, как Pacemaker описывает ресурсы, как ограничениями вы навязываете кластеру нужную топологию, и почему без рабочего fencing (STONITH) production-кластер собирать опасно. Разберём группы, клоны, multi-state, четыре типа ограничений, настройку STONITH и обслуживание без простоя.
Как это работает
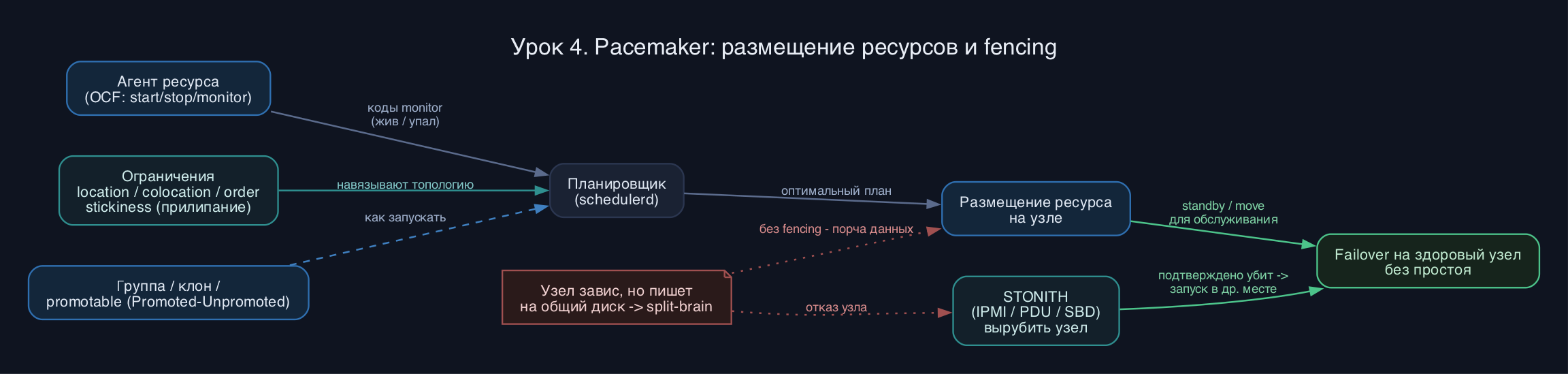
Ресурс в Pacemaker - это не сам демон, а описание того, как кластеру им управлять. За управление отвечает агент ресурса (resource agent): чаще OCF-скрипт, который умеет start, stop, monitor и возвращает строго определённые коды возврата. Pacemaker периодически дёргает monitor и по коду понимает, жив ресурс или упал. Поверх агентов планировщик (pacemaker-schedulerd) берёт текущее и желаемое состояние плюс ограничения, считает оптимальное размещение и выдаёт действия контроллеру.
Примитив (primitive) - один экземпляр сервиса. Но реальные сервисы состоят из частей, которые должны жить вместе и в правильном порядке: ФС, потом IP, потом демон. Чтобы не описывать связи руками, есть группа (group): ресурсы в ней стартуют слева направо, останавливаются справа налево и всегда колоцируются на одном узле. Группа - это сахар над colocation плюс order.
Клон (clone) запускает один и тот же ресурс на нескольких узлах сразу - так работают активные-активные сервисы, кластерные ФС, демоны блокировок. Multi-state (в современном Pacemaker это clone с метаатрибутом promotable) - клон, у экземпляров которого две роли: Promoted и Unpromoted (бывшие Master/Slave, термины сменили с Pacemaker 2.0). Так описывают репликацию: одна копия ведущая на запись, остальные ведомые, а агент сам умеет promote и demote.
Размещением рулят четыре ограничения. Location привязывает ресурс к узлам через очки (score): чем выше score, тем сильнее желание там запуститься; -INFINITY жёсткий запрет, +INFINITY жёсткое требование. Colocation говорит "держи A там же, где B" (минус - наоборот, anti-colocation). Order задаёт порядок "сначала B, потом A". Отдельно stickiness (resource-stickiness) - очки прилипания к текущему узлу: они гасят бессмысленные переезды обратно после возврата упавшего узла. Без stickiness ресурс скачет туда-сюда - классический источник флаппинга.
И отдельно - fencing. Если узел перестал отвечать, кластер не знает, он мёртв или просто потерял сеть и продолжает писать на общий диск. Запустить тот же ресурс на втором узле - это split-brain и порча данных. STONITH (Shoot The Other Node In The Head) физически вырубает подозрительный узел через IPMI, iLO/iDRAC, управляемый PDU или fence_sbd на разделяемом диске. Только получив подтверждение, что узел убит, кластер запускает ресурсы в другом месте. Правило простое: production без STONITH не бывает.
Команды и примеры
Инструмент управления различается: в RHEL/Fedora это pcs, в SUSE и Debian/Ubuntu чаще crmsh (crm).
Код: Выделить всё
# RHEL 10 / Fedora 41+
dnf install pcs pacemaker fence-agents-all resource-agents
# Debian 13 / Ubuntu 24.04
apt install pacemaker pcs crmsh fence-agents resource-agents
Код: Выделить всё
# pcs (RHEL): примитив
pcs resource create vip ocf:heartbeat:IPaddr2 ip=10.0.0.50 cidr_netmask=24 op monitor interval=20s
# группа web: порядок и колокация заданы автоматически
pcs resource group add web fs vip httpd
Код: Выделить всё
crm configure primitive vip ocf:heartbeat:IPaddr2 params ip=10.0.0.50 cidr_netmask=24 op monitor interval=20s
crm configure group web fs vip httpd
Код: Выделить всё
# pcs: клон на всех узлах
pcs resource clone dlm
# promotable multi-state
pcs resource promotable pgsql promoted-max=1 promoted-node-max=1 clone-max=2
Код: Выделить всё
pcs constraint location vip prefers node1=200
pcs constraint colocation add httpd with vip INFINITY
pcs constraint order fs then vip then httpd
pcs resource defaults update resource-stickiness=100
Код: Выделить всё
pcs stonith create fence-node1 fence_ipmilan \
pcmk_host_list=node1 ip=10.0.1.11 username=admin password=secret lanplus=1 \
op monitor interval=60s
pcs property set stonith-enabled=true
pcs stonith fence node1 # проверка: реально убить узел
Код: Выделить всё
pcs node standby node2 # эвакуировать ресурсы
pcs node unstandby node2
pcs resource move web node1 # ручная миграция (ставит location -INFINITY!)
pcs resource clear web # снять временное ограничение после move
pcs property set maintenance-mode=true # весь кластер на паузу мониторинга
Частые грабли
- stonith-enabled=true стоит, но устройство не настроено - ресурсы при сбое зависают в "ожидании fencing" навсегда. Сначала устройство, потом включение.
- pcs resource move незаметно создаёт постоянное location-ограничение с -INFINITY. Забыли pcs resource clear - ресурс больше не вернётся на узел, и будете долго гадать почему.
- Нулевой stickiness: упавший узел вернулся, ресурс переехал обратно и оборвал сессии на пустом месте. Ставьте resource-stickiness осмысленно.
- Термины Master/Slave устарели. В Pacemaker 2.x роли Promoted/Unpromoted, метаатрибут promotable, а не master. Старые мануалы сбивают с толку.
- Fencing через IPMI на том же блоке питания, что и узел: пропало питание - узел не убить. Нужен внешний PDU или SBD.
- Группа диктует и порядок, и колокацию разом. Нужна колокация без жёсткого порядка - группа не подходит, описывайте ограничения раздельно.
- На двухузловом кластере создайте vip (IPaddr2) и проверьте через pcs status, где он поднялся.
- Соберите группу web из ФС, vip и веб-сервера; убедитесь, что все три на одном узле и стартуют по порядку.
- Задайте location vip к node1 и resource-stickiness=100; погасите node1, посмотрите failover, верните node1 и убедитесь, что переезда обратно нет.
- Настройте STONITH (fence_ipmilan или учебный fence_xvm для виртуалок) и включите stonith-enabled.
- Оборвите сеть на node2 и проследите по логам, как кластер делает fencing и переносит ресурсы.
- Переведите node1 в standby и обратно; затем включите maintenance-mode на весь кластер и проверьте, что monitor не реагирует.
- Сделайте pcs resource move web и сразу pcs resource clear; через pcs constraint убедитесь, что ограничение исчезло.
- Чем группа отличается от пары colocation + order и когда группа неуместна?
- Какие роли у экземпляров promotable-клона и какими операциями агент их меняет?
- Что будет с ресурсами при отказе узла, если stonith-enabled=true, но устройство не настроено?
- Чем score -INFINITY отличается от просто низкого отрицательного значения в location?
- Зачем нужен resource-stickiness и какой симптом при нулевом stickiness после возврата узла?
- В чём разница между standby узла и maintenance-mode всего кластера?

