
Ядро Tarantool даёт примитивы: спейсы, индексы, транзакции, файберы, репликацию, vshard. Но в реальном проекте поверх этих примитивов постоянно повторяются одни и те же задачи: писать в шардированный кластер, не думая о bucket_id; отдавать метрики в Prometheus; держать отложенную обработку задач; чистить протухшие записи. Чтобы не изобретать это в каждом проекте, команда Tarantool сопровождает набор официальных Lua-модулей (rocks), которые ставятся через tt rocks и являются такими же первоклассными компонентами платформы, как box. В этом уроке разбираем четвёрку самых ходовых: crud, metrics, queue, expirationd (и кратко migrations).
Важно понимать общий принцип: rocks - это чистый Lua поверх публичного API box. У них нет магии в ядре. crud дёргает vshard.router, metrics читает box.stat и считает свои коллекторы в памяти, queue хранит задачи в обычном спейсе, expirationd - это просто файбер с pairs по индексу. Понимание этого снимает 90% вопросов про их поведение.
Как это устроено внутри
crud - это слой доступа к данным в шардированном (vshard) кластере. Без crud, чтобы вставить тапл, вы должны сами посчитать bucket_id (обычно от хеша ключа шардирования), записать его в специальное поле тапла и направить запрос через vshard.router.callrw на нужный storage. crud прячет это: его функции работают с точки зрения роутера, сами вычисляют bucket_id и маршрутизируют запрос. Точечные операции (insert, get, replace, update, delete, upsert) идут на один storage - тот, где живёт бакет. А вот select/pairs/count без указания ключа шардирования превращаются в map-reduce: роутер рассылает подзапрос на все storages (map), каждый отдаёт частичный результат, роутер их сливает и сортирует (reduce). Отсюда главное свойство: crud.select по вторичному индексу без условия на ключ шардирования - дорогая операция, потому что опрашивает весь кластер.
metrics - реестр коллекторов в памяти процесса. Четыре типа по модели Prometheus: counter (только растёт), gauge (любое число вверх/вниз), histogram (раскладка по бакетам le), summary (квантили в скользящем окне). Каждый коллектор хранит наблюдения, разрезанные по labels (ключ-значение). Дефолтные метрики (network, memory, slab, fibers, operations, vinyl и т.д.) включаются одной строкой и под капотом читают box.stat/box.info. Экспорт - через плагины (prometheus, json, graphite): плагин зовёт register-колбэки, обходит метрики.collectors() и сериализует. С версии 2.11.1 metrics встроен в Tarantool, а в 3.x его настраивают прямо в конфиге секцией metrics.
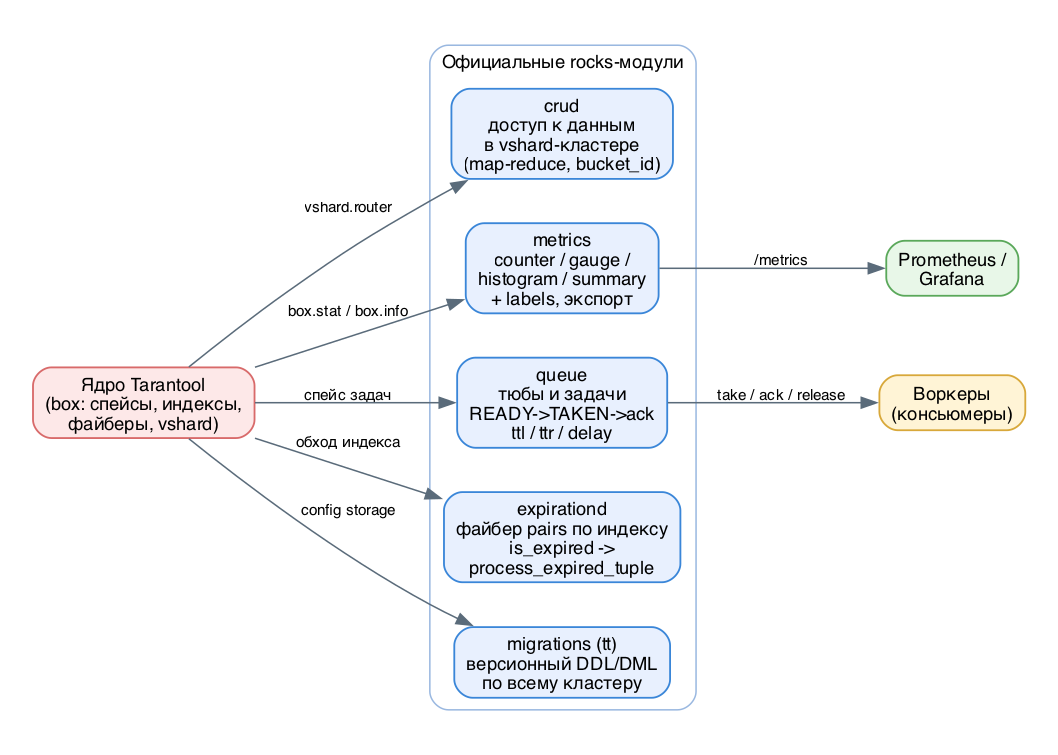
Экосистема ключевых rocks-модулей поверх ядра
queue - персистентная очередь задач поверх обычного спейса. Каждая задача имеет состояние и движется по конечному автомату: READY (готова к взятию) -> TAKEN (взята воркером) -> DONE/удалена (после ack) либо назад в READY (после release). Воркер вызывает take() - получает задачу и переходит её в TAKEN, держа её эксклюзивно. После успешной обработки - ack() (удаляет задачу), при сбое - release() (возвращает в READY). Типы тюбов (tube): fifo (без персистентности TTL), fifottl (с delay/ttl/ttr/pri), utube/utubettl (с гарантией порядка по подочередям). Ключевой механизм надёжности - ttr (time to run): если воркер взял задачу и упал, не сделав ack, по истечении ttr задача автоматически возвращается в READY и достаётся другому. ttl - срок жизни задачи целиком, delay - отложенный старт.
expirationd - демон протухания. Он создаёт фоновый файбер, который бесконечно идёт по индексу спейса через pairs, на каждом тапле зовёт вашу функцию is_expired(args, tuple); если она вернула true - зовёт process_expired_tuple (по умолчанию delete, но можно архивировать). Файбер кооперативно засыпает, чтобы не блокировать другие транзакции, и регулирует темп: за один проход обрабатывает tuples_per_iteration таплов и растягивает полный скан на full_scan_time. Это не TTL-индекс в ядре - это прикладной обход, поэтому удаление протухших записей всегда отстаёт на величину периода скана.
Команды и короткие примеры
Установка модулей в окружение приложения:
Код: Выделить всё
tt rocks install crud
tt rocks install metrics
tt rocks install queue
tt rocks install expirationd
Код: Выделить всё
local crud = require('crud')
crud.insert('users', {1, box.NULL, 'alice', 30})
-- точечное чтение по первичному ключу -> один storage
crud.get('users', 1)
-- select с условиями; без ключа шардирования это map-reduce по всем storage
crud.select('users', {{'>=', 'age', 18}}, {first = 100})
crud.count('users', {{'==', 'name', 'alice'}})
Код: Выделить всё
local metrics = require('metrics')
metrics.cfg{labels = {alias = 'router-1'}}
metrics.enable_default_metrics()
local logins = metrics.counter('app_logins_total', 'Число логинов')
logins:inc(1, {status = 'ok'})
local prometheus = require('metrics.plugins.prometheus')
-- prometheus.collect_http() отдаёт тело для эндпоинта /metrics
Код: Выделить всё
local queue = require('queue')
queue.create_tube('emails', 'fifottl', {temporary = false})
-- продюсер: задача стартует через 5 c, живёт 3600 c, на обработку 30 c
queue.tube.emails:put({to = 'a@b.c'}, {delay = 5, ttl = 3600, ttr = 30})
-- консьюмер
local task = queue.tube.emails:take(1) -- ждать до 1 c
if task then
local id, status, data = task[1], task[2], task[3]
-- ... обработка ...
queue.tube.emails:ack(id) -- успех; при ошибке :release(id)
end
Код: Выделить всё
local expirationd = require('expirationd')
local function is_expired(args, tuple)
return tuple[2] < os.time() - 86400
end
expirationd.start('clean_sessions', box.space.sessions.id, is_expired, {
tuples_per_iteration = 1000,
full_scan_time = 3600, -- полный проход за час
force = false, -- только на мастере
})
Код: Выделить всё
tt migrations publish
tt migrations apply
tt migrations status
Код: Выделить всё
модуль слой где работает главная сущность
crud доступ router map-reduce + bucket_id
metrics observ. каждый instance collector + labels
queue workflow storage (мастер) tube + FSM задачи
expirationd обслуживание мастер спейса fiber + pairs
migrations эволюция центр. config версионный DDL
"crud.select быстрый, это же просто select". Нет: без условия на ключ шардирования это map-reduce по всем storage с слиянием на роутере. Дорого по сети и CPU. Фильтруйте по ключу шардирования или по первому полю первичного индекса; ставьте first/after для пагинации, не вычитывайте миллионы таплов разом.
- crud не равно box. crud.insert на роутере не вызывает box.space:insert локально - он маршрутизирует на storage. На самом storage спейс должен иметь поле bucket_id и индекс по нему.
- metrics labels с высокой кардинальностью (user_id, url с параметрами) ведут к комбинаторному взрыву временных рядов и могут уронить вашу TSDB. Лейблами делают alias инстанса, метод, шаблон роута - но не уникальные идентификаторы.
- queue: если воркер не вызвал ack и не упал, а просто завис дольше ttr - задача уйдёт второму воркеру, и вы получите двойную обработку. Делайте обработчики идемпотентными. И помните: задачи живут на мастере; после смены лидера очередь должна продолжиться на новом мастере (нужны временные тюбы false и корректная репликация).
- expirationd удаляет не мгновенно, а в темпе скана: при большом full_scan_time протухшие записи лежат ещё долго. is_expired зовётся на каждом тапле - тяжёлая логика там бьёт по производительности. По умолчанию задача крутится только на писателе; на реплике стартовать её бессмысленно.
- Версии: rocks обновляются независимо от ядра. Связка crud + vshort + Tarantool 3.x требует совместимых версий (старые crud не знают про auto-discovery мастера в vshard). Фиксируйте версии в rockspec.
Поднимите одиночный инстанс (box.cfg на vinyl или memtx). Установите queue и expirationd. Создайте тюб fifottl emails и спейс sessions(id, created_at). Положите 3 задачи в очередь с разными ttr, возьмите одну через take, не делайте ack и подождите дольше ttr - убедитесь, что задача снова стала READY (проверьте queue.statistics или повторный take). Затем запустите expirationd на sessions с is_expired по created_at старше 10 секунд и tuples_per_iteration = 100; вставьте пару записей с прошлым временем и убедитесь, что они исчезают после прохода файбера. Запишите, через сколько секунд реально удалились (это и есть лаг скана).
Контрольные вопросы
- Почему crud.select без условия на ключ шардирования - это map-reduce, и что именно делает роутер на фазе reduce?
- В чём разница между ttl, ttr и delay у задачи в тюбе fifottl, и какой из них спасает от зависшего воркера?
- Почему expirationd не гарантирует мгновенное удаление протухшего тапла и от каких параметров зависит лаг?
- Какой тип коллектора metrics выберете для "текущее число активных соединений" и почему не counter?