
В реальном кластере приложение редко работает с одним инстансом. Узлов много (реплики, шарды, разные дата-центры), они то падают, то возвращаются, а запросы надо раскидывать так, чтобы чтение шло на реплики, запись - на мастер, и при этом обрыв сети не валил бизнес-логику. За это в Tarantool отвечают три тесно связанных механизма: net.box (одно сетевое соединение с авто-реконнектом), пул соединений (набор живых net.box-соединений ко всем инстансам конфигурации) и балансировка (правило, на какой из подходящих инстансов отправить конкретный запрос).
Важно сразу разделить уровни. net.box - это транспорт к ОДНОМУ инстансу. Пул - это уже знание о ВСЕХ инстансах кластера и умение выбрать нужный. В Tarantool 3.x официальный декларативный пул - это модуль experimental.connpool: он читает топологию прямо из конфигурации кластера (имена инстансов, replicaset-ы, группы, роли, метки) и поэтому не требует руками прописывать список адресов.
Механика: как устроено внутриКлючевая идея урока: net.box даёт надёжный канал к узлу, а connpool поверх него превращает "набор узлов из конфига" в адресуемый по критериям пул, где выбор инстанса - это фильтрация по roles/labels/mode, а не хардкод адреса.
net.box: соединение как конечный автомат
net_box.connect() не открывает сокет немедленно. Он порождает worker-фибер, который запускает машину состояний: initial -> auth -> fetch_schema -> active. Само физическое соединение устанавливается лениво, при первом запросе. Все методам net.box - fiber-safe: десятки фиберов могут слать запросы через ОДНО соединение, и они пайплайнятся в один TCP-сокет, а каждый фибер получает именно свой ответ по sync-идентификатору запроса в протоколе IPROTO. Это снижает число сокетов и системных вызовов - поэтому "одно соединение на много фиберов" в Tarantool обычно лучше, чем пул из десятков сокетов к одному узлу.
Реконнект
Если сервер закрыл соединение, автомат уходит в состояние error. Если задан reconnect_after > 0, вместо error он попадает в error_reconnect и фоново пытается переподключиться через указанный интервал, бесконечно. Это делает кратковременные сетевые сбои прозрачными для приложения. Watcher-ы (conn:watch) переживают реконнект - после восстановления соединения подписки авто-восстанавливаются. Реконнект прекращается только при явном conn:close() или когда сборщик мусора удалил объект соединения.
Пул: connpool поверх net.box
connpool не хранит хитрых собственных сокетов - под капотом он создаёт обычные net.box-соединения к инстансам, но решает за вас, к КОМУ подключаться. connpool.connect(name, opts) даёт активное net.box-соединение к инстансу по имени. connpool.filter(opts) возвращает имена инстансов, подходящих под условия. connpool.call(func, args, opts) - выбирает кандидата по тем же условиям и выполняет на нём функцию.
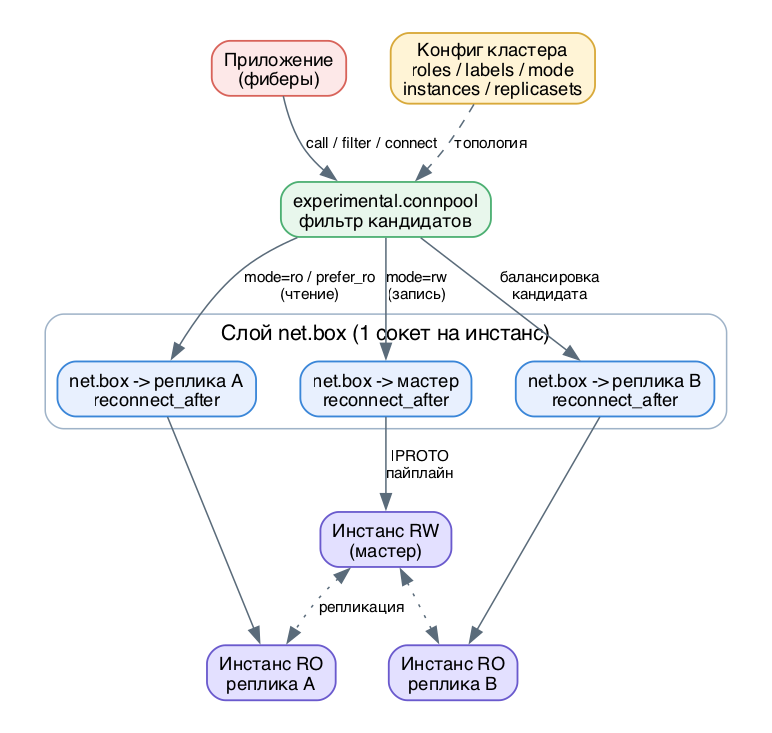
Пул connpool выбирает инстанс и шлёт запрос через net.box
Балансировка: как выбирается кандидат
Выбор инстанса в connpool.call - это последовательная фильтрация множества инстансов из конфига по опциям:
- instances / replicasets / groups - сузить кандидатов по топологии;
- roles - инстанс должен иметь указанную роль (например roles.crud-storage);
- labels - совпадение пользовательских меток (например dc = east);
- mode - фильтр по read-only статусу: ro, rw, prefer_ro, prefer_rw или nil (не проверять);
- prefer_local - по умолчанию true, пробует локальный инстанс; при false идёт на случайного кандидата.
Команды и короткие примеры
Одно соединение с авто-реконнектом (классический net.box, работает и в 1.x/2.x/3.x):
Код: Выделить всё
local net_box = require('net.box')
-- ленивое соединение, реконнект каждые 5 с, ждать не дольше 1 с
local conn = net_box.connect('127.0.0.1:3301', {
user = 'sampleuser', password = 'secret',
reconnect_after = 5, -- фоновый бесконечный реконнект
connect_timeout = 1, -- предел ожидания установки
wait_connected = false, -- вернуть conn сразу, не блокируясь
fetch_schema = true, -- нужно для conn.space.<name>
})
conn:ping({timeout = 0.5}) -- true/false, не кидает
print(conn:is_connected()) -- состояние сейчас
conn:wait_connected(2) -- подождать active до 2 с
conn.space.bands:select({1}) -- запрос идёт через сокет
conn:call('get_bands_older_than', {2000})
conn:close() -- останавливает реконнект
Код: Выделить всё
local connpool = require('experimental.connpool')
-- 1) соединение к конкретному инстансу по ИМЕНИ из конфига
local conn = connpool.connect('storage-b-002', { fetch_schema = true })
-- 2) кто подходит под условия (имена инстансов)
local names = connpool.filter({
roles = { 'roles.crud-storage' },
labels = { dc = 'east' },
})
-- 3) выполнить функцию на подходящем read-only инстансе
local cnt = connpool.call('vshard.storage.buckets_count', nil, {
roles = { 'roles.crud-storage' },
labels = { dc = 'east' },
mode = 'ro', -- только реплики
timeout = 1,
})
Код: Выделить всё
mode кого рассматриваем
----------- -----------------------------------------
nil любой (ro-статус не проверяется)
ro только read-only (реплики)
rw только read-write (мастер)
prefer_ro сначала реплики, иначе мастер
prefer_rw сначала мастер, иначе реплики
- "net.box - это пул". Нет. Один net.box - это одно соединение к одному узлу. Пул (connpool) - слой выше, который знает топологию и выбирает узел.
- "Открою по соединению на фибер для скорости". Обычно вредно: net.box fiber-safe и пайплайнит запросы в один сокет. Лишние соединения = лишние сокеты, дескрипторы и риск "too many open files". Несколько соединений к одному узлу оправданы лишь для приоритизации или разных auth-ID.
- "reconnect_after сам всё ретраит". Он переустанавливает СОЕДИНЕНИЕ, но запрос, попавший в момент обрыва, всё равно вернёт ошибку - ретрай конкретного запроса делает приложение. Плюс при reconnect_after > 0 опция wait_connected игнорирует временные сбои и ждёт до явного active или close.
- "connpool можно брать в продакшен как есть". Модуль experimental.connpool помечен как experimental (с 3.1.0) и API может меняться - закладывайте это в риски.
- "connpool сам балансирует чтения round-robin". Нет, он лишь выбирает подходящего кандидата (с prefer_local). Полноценная нагрузочная балансировка чтений по репликам - это vshard.router, отдельный слой.
- "fetch_schema не важен". Без него (false) недоступны conn.space.<name> и не работают триггеры on_schema_reload. Зато для чистых call/eval его выгодно выключить - меньше трафика.
- "Долгий connect_timeout безопасен". connpool опрашивает инстансы по очереди, и его время работы зависит от числа узлов и времени коннекта к каждому - большой таймаут на недоступном узле затормозит весь вызов.
Запустите локальный инстанс на 127.0.0.1:3301. В консоли tt создайте соединение с reconnect_after = 3 и wait_connected = false. Проверьте conn:is_connected() сразу после connect (увидите, что ещё не active), затем conn:wait_connected(2). Сделайте conn:ping(). Теперь остановите инстанс (tt stop), повторите ping - получите false, но соединение не закроется. Запустите инстанс снова, через несколько секунд снова ping и убедитесь, что connpool/net.box сам переподключился без повторного connect. Зафиксируйте, сколько секунд занял реконнект и совпало ли это с reconnect_after.
Контрольные вопросы
- Чем уровень net.box отличается от уровня connpool, и почему "одно соединение на много фиберов" обычно эффективнее пула сокетов к одному узлу?
- Что произойдёт с запросом, который выполнялся в момент обрыва, если задан reconnect_after = 5? Кто отвечает за повтор именно этого запроса?
- Как с помощью connpool.call отправить запись только на мастер, а чтение - предпочтительно на реплику? Какие значения mode для этого нужны?
- Почему большое значение connect_timeout вместе с недоступным узлом может замедлить весь вызов connpool, и как это связано с тем, как пул перебирает кандидатов?