
Tarantool держит данные memtx целиком в оперативной памяти. Память исчезает при перезапуске или сбое, поэтому одной её мало - нужен способ переживать рестарты. Эту задачу решают два артефакта на диске: write-ahead log (WAL, файлы .xlog) и снапшоты (файлы .snap). Правило, которое надо унести из урока:
WAL пишется ДО подтверждения клиенту (отсюда write-ahead). Снапшот - это оптимизация: без него восстановление пришлось бы проигрывать весь журнал с самого первого дня, что долго.Снапшот - это полный слепок состояния на момент времени T. WAL - это журнал всех изменений после T. Снапшот плюс хвост WAL дают точное состояние базы на момент последней успешной записи. Recovery = загрузить снапшот, потом доиграть WAL.
Как устроена запись внутри
Транзакции и сеть обслуживает один поток - TX (transaction processor). Запись на диск выполняет отдельный поток - WAL writer. Они общаются асинхронными, но надёжными сообщениями. Это ключ к производительности: TX не блокируется на диске.
Путь одной операции изменения (insert/replace/update/delete/upsert):
- TX находит старый кортеж по первичному ключу (если есть), валидирует новый, применяет изменение к индексам в памяти.
- Каждой записи присваивается LSN - непрерывно растущий 64-битный номер (log sequence number). Набор LSN по инстансам образует vclock.
- TX формирует journal entry и шлёт сообщение WAL writer-у, после чего сразу берёт следующий запрос (полный пайплайнинг, даже по одному и тому же ключу).
- WAL writer дописывает строку в текущий .xlog. Каждая строка: магический маркер 0xd5ba0bab, длина, CRC32, заголовок (тип запроса, server id, LSN, timestamp) и тело в формате MessagePack.
- Только ПОСЛЕ успешной записи на диск клиенту уходит подтверждение коммита.
В WAL всегда лежит изменение по ПЕРВИЧНОМУ ключу, даже если клиент удалял/обновлял по вторичному. Новый .xlog создаётся, когда текущий дорастает до wal.max_size; имя файла - это LSN первой записи в нём.
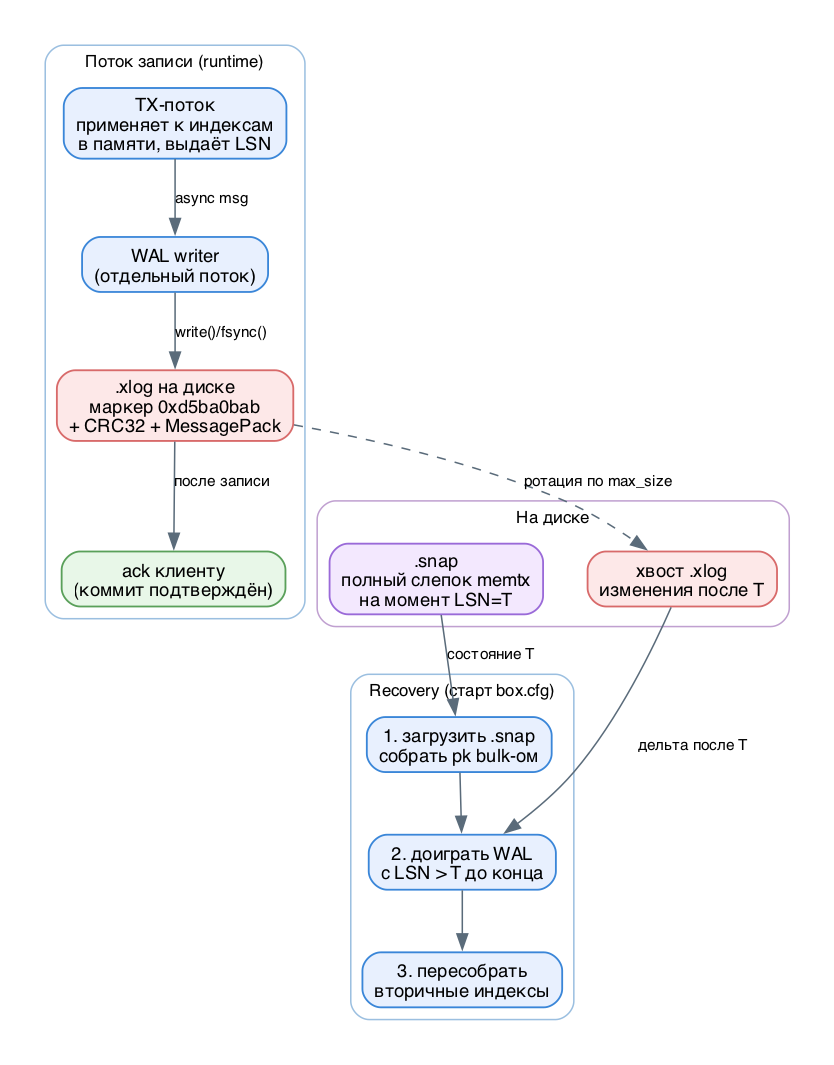
Поток записи TX-WAL-диск и recovery из снапшота с WAL
Режимы долговечности (wal.mode)
Поведение WAL writer задаёт один параметр. Внутри это всего лишь выбор: ждать ли write(), и звать ли fsync() после каждой записи.
Код: Выделить всё
mode смысл цена
------ -------------------------------------------- ------------
write файбер ждёт write() в WAL (default) быстро
fsync write() + fsync() после каждой записи медленно
none WAL не ведётся вообще, только снапшоты макс. скорость
Снапшоты и чекпоинты
Снапшот запускается вручную через box.snapshot() или автоматически checkpoint-демоном. В .snap пишутся только INSERT-записи memtx-спейсов (полное согласованное состояние), отсортированные по id спейса, затем по первичному ключу. Системные спейсы (id 256..511) идут первыми. Для vinyl box.snapshot() инициирует checkpoint движка; если что-то пошло не так, операция откатывается, поэтому checkpoint vinyl всегда не старше .snap.
Код: Выделить всё
-- классический трек (box.cfg, 1.x/2.x/3.x)
box.snapshot() -- сделать снапшот прямо сейчас
box.cfg{
wal_mode = 'write',
checkpoint_interval = 3600, -- сек между авто-снапшотами
checkpoint_count = 2, -- сколько снапшотов хранить
}
box.info.lsn -- текущий LSN инстанса
box.info.vclock -- vclock (LSN по server id)
Код: Выделить всё
# декларативный трек 3.x (config.yaml)
wal:
mode: write
max_size: 268435456 # ротация .xlog при этом размере
snapshot:
by:
interval: 3600 # авто-снапшот по времени
wal_size: 1000000000 # ...или по объёму WAL с прошлого чекпоинта
count: 2 # хранить 2 снапшота
Процесс recovery (по шагам)
Восстановление стартует при первом box.cfg{} после запуска инстанса.
- Шаг 1. Прочитать пути: wal_dir, memtx_dir, vinyl_dir и флаг force_recovery.
- Шаг 2. Найти свежайший .snap, восстановить memtx из него, сказать vinyl восстановиться до его checkpoint. По умолчанию (force_recovery=false) кортежи грузятся с выключенными индексами, потом первичный ключ строится bulk-ом - данные уже отсортированы, это быстро.
- Шаг 3. Найти .xlog, относящийся к моменту снапшота, и пропустить записи с LSN не больше LSN снапшота - это "стартовая позиция".
- Шаг 4. Доиграть (redo) все записи WAL от стартовой позиции до конца журнала. Движок пропускает запись, если она старше его checkpoint.
- Шаг 5. Для memtx пересобрать все вторичные индексы.
Частые заблуждения и грабли
- "wal_mode write = данные гарантированно на диске." Нет, write только доводит до write()/кеша ОС. Гарантию на пластину даёт fsync.
- "checkpoint_count удалит лишние снапшоты всегда." Нет: если есть реплика, которая ещё не получила данные, файлы не удалятся - GC бережёт их для отстающих реплик. Может неожиданно расти диск.
- "snapshot - это бэкап." Это слепок памяти для быстрого старта, а не резервная копия (для бэкапа есть отдельные инструменты, копирующие .snap + хвост .xlog согласованно).
- "wal_mode none быстрее, оставлю в продакшене." Любой сбой между снапшотами = безвозвратная потеря данных. none уместен для тестов и эфемерных кешей.
- Долгий старт = много WAL. Если снапшоты редкие, recovery проигрывает гигабайты журнала. Лечится более частыми чекпоинтами.
Запустите Tarantool интерактивно, инициализируйте box, создайте спейс и сделайте несколько вставок. Снимите снапшот, добавьте ещё кортежи ПОСЛЕ снапшота, затем убейте процесс жёстко (kill -9, имитация сбоя) при wal_mode 'write'. Перезапустите инстанс на том же каталоге и убедитесь, что данные после снапшота тоже на месте - их вернул WAL.
Код: Выделить всё
box.cfg{ wal_mode = 'write' }
local s = box.schema.space.create('t', {if_not_exists=true})
s:create_index('pk', {if_not_exists=true})
for i=1,5 do s:insert{i, 'before snap'} end
box.snapshot()
print('lsn after snap:', box.info.lsn)
for i=6,10 do s:insert{i, 'after snap'} end
print('lsn before crash:', box.info.lsn)
-- теперь kill -9 процесс, перезапусти на том же memtx_dir/wal_dir
-- после старта: box.space.t:count() должно быть 10
Контрольные вопросы
- В каком порядке во время recovery применяются снапшот и WAL и почему именно так, а не наоборот?
- Чем отличаются wal_mode write и fsync на уровне системных вызовов и какие данные рискуют потеряться в режиме write при отключении питания?
- Почему .xlog, бывший текущим в момент старта box.snapshot(), нельзя удалять сразу после завершения снапшота?
- Что такое LSN и vclock, и какую роль LSN играет на шаге, где recovery пропускает часть записей WAL?