
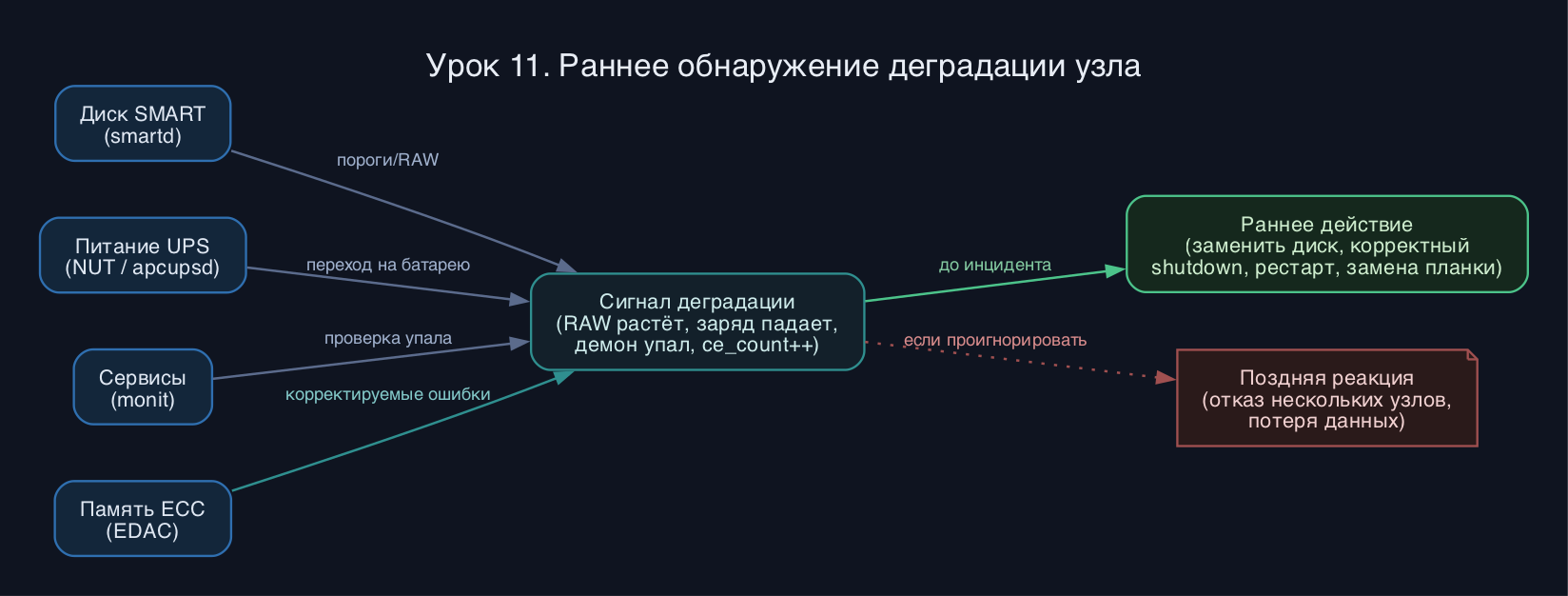
Кластер высокой доступности живёт на отдельных узлах, и кластер не спасёт, если узлы тихо деградируют до момента, когда отказывают сразу несколько. Задача администратора - поймать деградацию на уровне одного узла раньше, чем она превратится в инцидент: предсказать смерть диска по SMART, корректно пережить пропадание питания через UPS, поднять упавший демон без ручного вмешательства и заложить аппаратное резервирование (ECC-память, два блока питания). В этом уроке разбираем smartd, NUT и apcupsd, monit и принципы раннего обнаружения деградации.
Как это работает
SMART - это набор счётчиков внутри самого накопителя (HDD, SATA SSD, NVMe). Диск сам ведёт статистику по переназначенным секторам, ошибкам чтения, температуре, износу ячеек. Демон smartd периодически опрашивает эти атрибуты и сравнивает с порогами. Хитрость в том, что у каждого атрибута есть текущее нормированное значение (VALUE), порог (THRESH) и худшее зафиксированное (WORST). Когда VALUE опускается до THRESH - диск официально считается предотказным. Но опытный инженер смотрит на RAW-значения сырых счётчиков: рост Reallocated_Sector_Ct или Current_Pending_Sector это сигнал заменить диск, даже если формальный порог ещё не пробит.
UPS защищает от пропадания питания, но сам по себе он только держит нагрузку несколько минут. Смысл мониторинга - поймать переход на батарею, дождаться разумного порога заряда и инициировать корректное выключение, пока питание ещё есть. NUT (Network UPS Tools) - это клиент-серверная архитектура: драйвер (драйвер общается с железом по USB/serial/SNMP), демон upsd отдаёт состояние по сети, а upsmon на каждом узле принимает решение о shutdown. Это позволяет одному UPS обслуживать несколько серверов. apcupsd - более простой монолитный демон, исторически заточенный под APC, но умеющий и другие модели.
monit следит за процессами и ресурсами по принципу проверка - условие - действие. Он опрашивает PID-файл или процесс по имени, и если демон упал, monit запускает его заново. Важно понимать разделение зон ответственности: systemd с Restart=on-failure перезапускает то, что он сам запустил, а monit полезен для проверок уровня приложения (отвечает ли HTTP-эндпоинт, не растёт ли память, есть ли файл сокета) и для алертов.
ECC-память исправляет одиночные битовые ошибки на лету и сообщает о них через EDAC. Двойная ошибка не исправляется, но детектируется. Раннее обнаружение тут - это чтение счётчиков корректируемых ошибок: их рост на конкретной плашке предсказывает её скорый отказ.
Команды и примеры
Установка smartmontools и базовый опрос:
Код: Выделить всё
# Debian 13 / Ubuntu 24.04
apt install smartmontools
# RHEL 10 / Fedora 41+
dnf install smartmontools
smartctl -i /dev/sda # модель, серийник, поддержка SMART
smartctl -H /dev/sda # короткий вердикт PASSED/FAILED
smartctl -A /dev/sda # таблица атрибутов с VALUE/THRESH/RAW
smartctl -a /dev/nvme0 # для NVMe атрибуты в своём формате
smartctl -t long /dev/sda # запустить длинный самотест
smartctl -l selftest /dev/sda # журнал самотестов
Код: Выделить всё
# опрашивать все диски, слать тест-письмо при старте, мейл на алерт
DEVICESCAN -a -o on -S on -n standby,q -s (S/../.././02|L/../../6/03) -m root@localhost -M exec /usr/share/smartmontools/smartd-runner
Код: Выделить всё
systemctl enable --now smartd
systemctl status smartd
Код: Выделить всё
# /etc/nut/ups.conf
[myups]
driver = usbhid-ups
port = auto
desc = "APC BackUPS"
# /etc/nut/upsd.users
[monuser]
password = secret
upsmon master
# /etc/nut/upsmon.conf
MONITOR myups@localhost 1 monuser secret master
SHUTDOWNCMD "/sbin/shutdown -h +0"
# /etc/nut/nut.conf
MODE=standalone
Код: Выделить всё
systemctl enable --now nut-server nut-monitor
upsc myups@localhost # дамп всех переменных
upsc myups battery.charge # заряд в процентах
Код: Выделить всё
apt install apcupsd # или dnf install apcupsd
# /etc/apcupsd/apcupsd.conf
UPSCABLE usb
UPSTYPE usb
DEVICE
BATTERYLEVEL 15 # ниже 15% - выключение
MINUTES 5 # или меньше 5 минут автономии
systemctl enable --now apcupsd
apcaccess status # состояние, заряд, нагрузка
Код: Выделить всё
apt install monit # или dnf install monit
# /etc/monit/conf.d/nginx (Debian) или /etc/monit.d/nginx (RHEL)
check process nginx with pidfile /run/nginx.pid
start program = "/usr/bin/systemctl start nginx"
stop program = "/usr/bin/systemctl stop nginx"
if failed host 127.0.0.1 port 80 protocol http
then restart
if 5 restarts within 5 cycles then alert
systemctl enable --now monit
monit status # текущая картина по всем проверкам
Код: Выделить всё
dnf install edac-utils # apt install edac-utils
edac-util -v # сводка корректируемых/некорректируемых ошибок
grep . /sys/devices/system/edac/mc/mc*/ce_count # счётчики по контроллерам
dmesg | grep -i edac
- Вердикт smartctl -H говорит PASSED, а диск уже сыплется: формальный порог пробивается поздно, ориентируйтесь на рост RAW Reallocated_Sector_Ct, Current_Pending_Sector, Uncorrectable.
- Для дисков за RAID-контроллером smartctl не видит SMART напрямую - нужен ключ -d, например -d megaraid,0 или -d cciss,0.
- NVMe и SATA имеют разные наборы атрибутов: для NVMe смотрите Percentage Used и Media Errors, привычные SATA-атрибуты там отсутствуют.
- UPS подключён по USB, но после перезагрузки драйвер не стартует - частая причина в правах на /dev и в том, что MODE в nut.conf остался netserver вместо standalone.
- monit и systemd дерутся за один сервис: оба пытаются перезапускать, получается флаппинг. Решайте, кто хозяин процесса, и не дублируйте Restart= с check process.
- Письма от smartd и monit некуда слать: не настроен локальный MTA или smarthost, алерты молча теряются.
- ECC-ошибки растут на одной плашке, но это списывают на софт - корректируемые ошибки это предвестник отказа модуля, меняйте планку.
- Установите smartmontools, выполните smartctl -a по своему системному диску и найдите атрибуты Reallocated_Sector_Ct и Current_Pending_Sector, запишите их RAW.
- Запустите короткий самотест smartctl -t short, через пару минут посмотрите результат через smartctl -l selftest.
- Настройте /etc/smartd.conf с DEVICESCAN и расписанием самотестов, включите smartd, убедитесь по journalctl -u smartd что он подхватил диски.
- Если есть UPS - поднимите NUT в режиме standalone и снимите upsc battery.charge; если нет железа, поставьте dummy-ups драйвер и проверьте, что upsc отдаёт переменные.
- Установите monit, опишите check process для любого демона (например sshd) с проверкой порта, остановите демон вручную и убедитесь, что monit его поднял.
- Прочитайте edac-util -v и счётчики ce_count, зафиксируйте текущие значения как базовую линию.
- Чем отличается нормированное VALUE атрибута SMART от его RAW-значения и почему для прогноза отказа важнее второе?
- Какие три компонента образуют стек NUT и за что отвечает каждый из них?
- Как один UPS защищает несколько серверов и какой узел принимает решение о выключении?
- В каком случае разумно использовать monit, а в каком достаточно systemd с Restart=on-failure?
- Что детектирует и что исправляет ECC-память, и какой счётчик предсказывает отказ модуля?
- Почему smartctl -H PASSED не является достаточным основанием считать диск исправным?

