
Ceph решает задачу, которую обычные NAS и SAN решить не могут: дать петабайты хранилища без единой точки отказа и без центрального сервера-диспетчера, который знает, где что лежит. Администратор кластера хранения должен понимать не команды, а модель: какие демоны за что отвечают, как клиент находит данные без обращения к каталогу, и почему кластер переживает падение целой стойки. В этом уроке мы разберём демоны (OSD, MON, MGR, MDS), фундамент RADOS, алгоритм CRUSH, пулы с placement groups и выбор между репликацией и erasure coding. Актуально на июнь 2026: стабильная ветка Tentacle (20.2.x), Squid (19.2.x) поддерживается до сентября 2026.
Как это работает
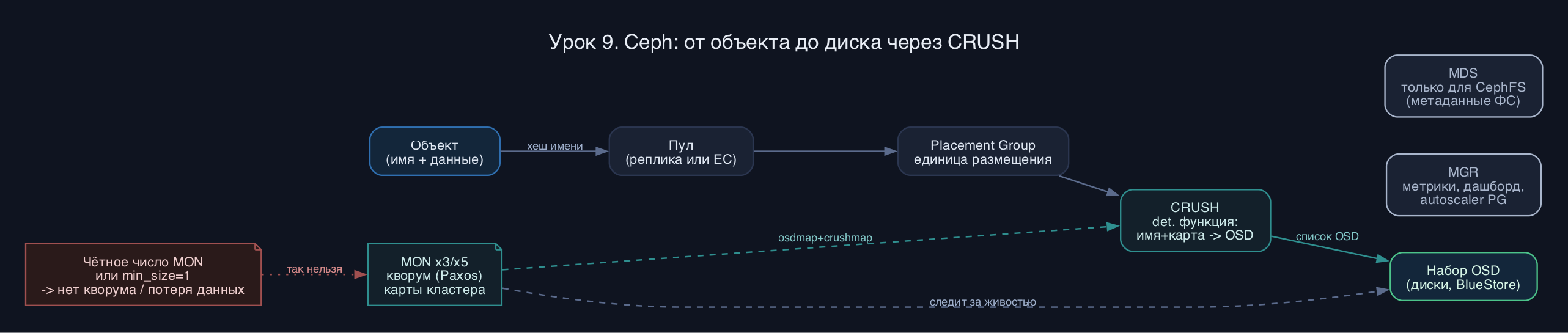
В основе всего лежит RADOS - надёжное автономное распределённое хранилище объектов. Всё остальное (блочные устройства RBD, файловая система CephFS, S3-шлюз RGW) - это лишь надстройки над RADOS. Объект в RADOS - это не файл и не блок, а именованный кусок данных с метаданными и атрибутами, живущий в пуле.
Ключевая идея Ceph: нет таблицы размещения. Клиент не спрашивает у сервера где лежит объект - он вычисляет это сам по алгоритму CRUSH. CRUSH - детерминированная псевдослучайная функция: на вход имя объекта, имя пула и карта кластера, на выходе - список конкретных OSD. Поскольку формула одна и та же у всех, клиент и демоны независимо приходят к одному ответу. Это убирает узкое место центрального каталога и даёт линейное масштабирование.
Демоны делят роли. OSD (object storage daemon) - рабочая лошадь: один демон обслуживает один диск, хранит объекты, делает репликацию, восстановление и проверку целостности (scrub). В современном Ceph данные на диске лежат в формате BlueStore - OSD пишет прямо на блочное устройство, без промежуточной ФС. MON (monitor) хранит и раздаёт карты кластера (monmap, osdmap, crushmap), а главное - поддерживает консенсус через Paxos. Мониторов ставят нечётное число (3 или 5), чтобы существовал кворум: кластер работает, пока живо большинство. MGR (manager) собирает метрики, держит дашборд и модули вроде балансировщика и автоскейлера PG. MDS (metadata server) нужен только CephFS - он держит дерево каталогов, прав и блокировок; сами данные файлов идут мимо MDS прямо в RADOS.
Между объектом и OSD есть промежуточный слой - placement group (PG). Объект по хешу имени попадает в одну из PG пула, а уже PG алгоритмом CRUSH ложится на набор OSD. PG - это единица репликации и восстановления. Без них при миллиардах объектов CRUSH пришлось бы считать индивидуально для каждого, а карта восстановления стала бы неуправляемой. Число PG подбирают так, чтобы на один OSD приходилось примерно 100 PG; в Tentacle этим обычно занимается autoscaler автоматически.
Защита данных бывает двух видов. Репликация хранит N полных копий (типично size=3, min_size=2): дорого по месту (overhead 200 процентов), но быстро и просто в восстановлении. Erasure coding режет объект на k частей данных и считает m частей чётности (например k=4, m=2): кластер переживает потерю любых m частей при overhead всего (k+m)/k, для 4+2 это 50 процентов. Платой идут CPU на кодирование, нагрузка на сеть при восстановлении и отсутствие частичных перезаписей - поэтому EC любят для холодных данных и RGW, а репликацию для RBD под виртуалки.
Команды и примеры
Установка. В 2026 канонический путь - cephadm с контейнерами (podman или docker), пакеты ставят на узел-загрузчик.
Код: Выделить всё
# Debian 13 / Ubuntu 24.04
apt install -y cephadm podman
cephadm bootstrap --mon-ip 10.0.0.11
# RHEL 10 / Fedora 41+
dnf install -y cephadm podman
cephadm bootstrap --mon-ip 10.0.0.11Код: Выделить всё
ceph -s # сводка: health, демоны, PG, использование
ceph mon stat # кто в кворуме
ceph quorum_status -f json-pretty
ceph osd tree # иерархия CRUSH: root -> host -> osdКод: Выделить всё
# Реплика 3 (по умолчанию), 128 PG
ceph osd pool create rbd-pool 128 128 replicated
ceph osd pool set rbd-pool size 3
ceph osd pool set rbd-pool min_size 2
# Erasure coding 4+2
ceph osd erasure-code-profile set ec42 k=4 m=2 \
crush-failure-domain=host
ceph osd pool create cold-pool 128 128 erasure ec42Код: Выделить всё
ceph osd erasure-code-profile get ec42
ceph pg dump pgs_brief | head # состояние каждой PG
ceph osd pool autoscale-status # рекомендации по числу PGЧастые грабли
- Чётное число мониторов. Два MON не дают отказоустойчивости: при разрыве сети кворума нет вообще. Всегда нечётное - 3 на старте, 5 на крупных кластерах.
- min_size=1 на проде. Соблазн пережить две потери копий оборачивается записью в единственный экземпляр - один сбой и данные потеряны без шансов на восстановление.
- crush-failure-domain=osd вместо host у EC. Тогда несколько шардов одного объекта могут лечь на один хост, и его падение убьёт объект. Для k+m нужно минимум k+m доменов отказа.
- Попытка изменить k и m у существующего EC-пула. Профиль фиксируется при создании; меняется только через новый пул и миграцию данных.
- Слишком много или мало PG вручную. Мало - неравномерная загрузка дисков, много - пожирается RAM и CPU на OSD. Доверяйте autoscaler, не выставляйте PG на глаз.
- EC-пул напрямую под RBD без overwrites. Старые гайды требовали кэш-тиринг; сейчас включают allow_ec_overwrites, но частичные записи всё равно дороже - под активные VM берите реплику.
- Поднимите три ВМ (Debian 13 или RHEL 10), на каждой по два чистых диска. Выполните cephadm bootstrap на первом узле.
- Добавьте два других узла через ceph orch host add и раскатайте OSD командой ceph orch apply osd --all-available-devices.
- Убедитесь, что мониторов три и есть кворум: ceph mon stat и ceph quorum_status.
- Создайте реплицированный пул size=3 и EC-пул профиля k=2 m=1 с failure-domain=host.
- Запишите объект: rados -p rbd-pool put test /etc/hostname, найдите его OSD через ceph osd map rbd-pool test.
- Остановите один OSD (systemctl stop ceph-osd@N в контейнере или ceph orch daemon stop), наблюдайте переход PG в degraded и обратно в active+clean.
- Сравните доступную ёмкость пулов в ceph df и объясните разницу overhead репликации и EC.
- Почему клиенту Ceph не нужен центральный сервер метаданных для поиска объекта, и что подаётся на вход CRUSH?
- Сколько мониторов должно выжить из пяти, чтобы сохранился кворум, и какой алгоритм консенсуса это обеспечивает?
- Чем placement group отличается от объекта и от OSD, и зачем нужен этот промежуточный слой?
- Для профиля erasure coding k=6 m=3 - сколько OSD можно потерять без потери данных и каков overhead по месту?
- Какой демон обязателен только для CephFS и почему данные файлов идут мимо него?
- В каких сценариях вы выберете репликацию, а в каких erasure coding, и какими ограничениями EC за это платит?

