
Этот курс готовит к экзамену 306-300 (версия 3.0) - последней ступени LPIC-3, посвящённой высокой доступности и кластерным хранилищам. Задача администратора здесь меняется качественно: вы перестаёте чинить отдельный сервер и начинаете проектировать систему, которая переживёт смерть этого сервера без участия человека. В нулевом уроке мы разберём язык, на котором об этом говорят: что такое доступность и как её считают, что такое единая точка отказа, что означают RTO и RPO, и куда в этой картине ложатся четыре больших темы экзамена - сам кластерный менеджер, кластерное хранилище, распределённое хранилище и резервирование одного узла.
Как это работает
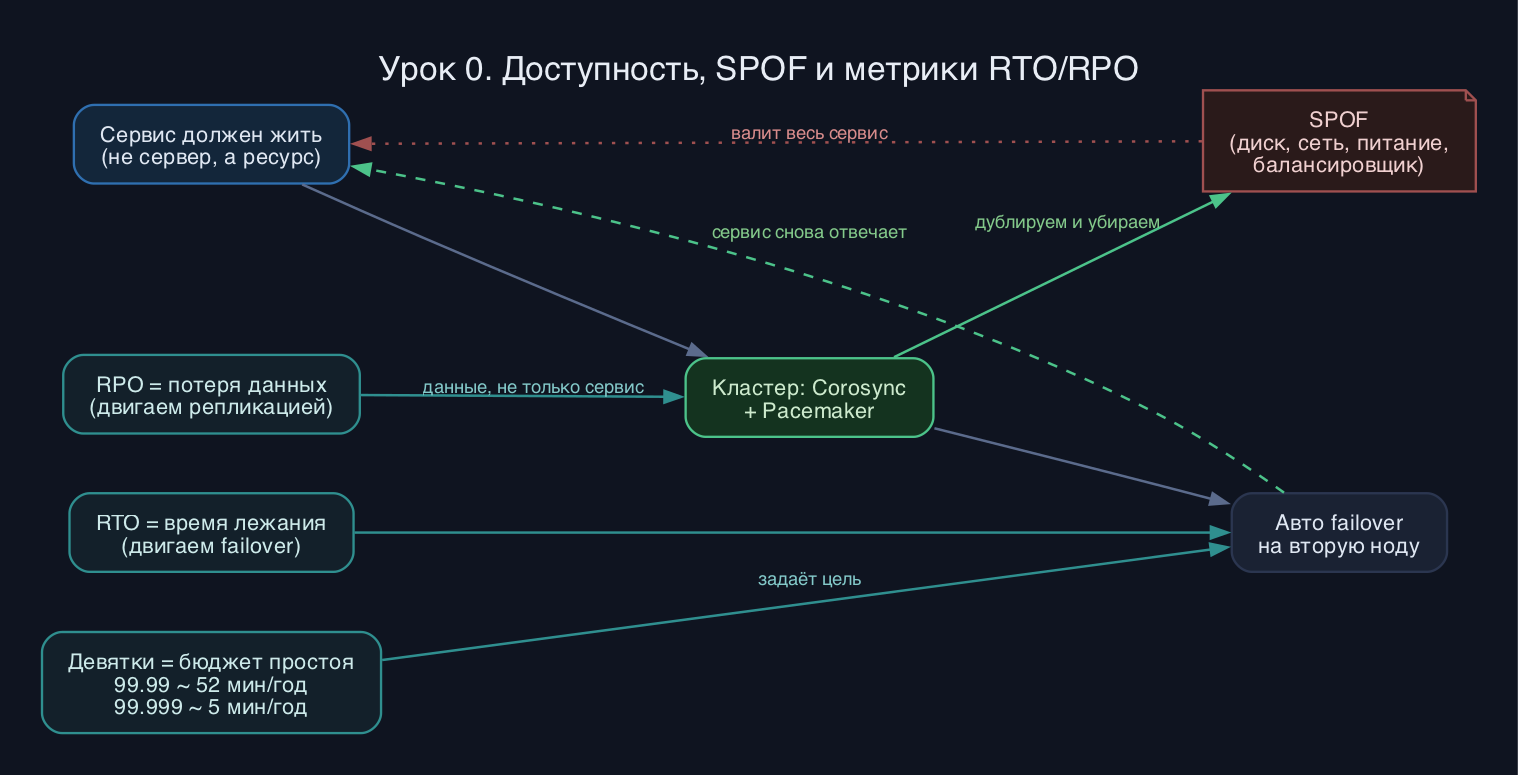
Высокая доступность (HA) - это свойство сервиса оставаться рабочим, несмотря на отказ отдельных компонентов. Ключевое слово - сервис, а не сервер. Пользователю не важно, какая именно нода отвечает на запрос; ему важно, что запрос обслужен. Поэтому HA-инженер мыслит не машинами, а ресурсами (IP-адрес, файловая система, демон базы) и тем, как эти ресурсы перетекают между узлами.
Враг номер один - единая точка отказа, SPOF (single point of failure). Это любой элемент, чья поломка валит весь сервис: один блок питания, один коммутатор, один диск, один балансировщик, один человек, который знает пароль. Проектирование HA - это методичный обход системы и устранение каждого SPOF дублированием. Важно: дублирование без автоматики не даёт HA. Два сервера, между которыми вы переключаетесь руками ночью, - это резерв, но не высокая доступность.
Доступность измеряют в процентах за период и привычно называют девятками. 99 процентов (две девятки) - это около 3.65 суток простоя в год. 99.9 (три девятки) - примерно 8.77 часа. 99.99 (четыре девятки) - около 52.6 минуты. 99.999 (пять девяток, эталон телекома) - около 5.26 минуты в год. Каждая лишняя девятка дороже предыдущей в разы, потому что требует убрать всё больше SPOF и всё точнее автоматику. Бизнес почти никогда не хочет максимума - он хочет ровно тот уровень, который окупается.
Две метрики описывают сам инцидент. RTO (Recovery Time Objective) - сколько максимум сервис может лежать, то есть целевое время восстановления. RPO (Recovery Point Objective) - сколько данных допустимо потерять, измеряется во времени до последней сохранной точки. RTO двигают кластеризацией и быстрым failover; RPO двигают репликацией и частотой бэкапов. Пример: синхронная репликация даёт RPO около нуля (потерь нет), но дороже и медленнее; бэкап раз в сутки даёт RPO до 24 часов, зато дёшев.
Отдельно держите в голове разницу между доступностью и сохранностью. Кластер может мгновенно поднять сервис на второй ноде (отличный RTO), но если данные были на одном диске без репликации, поднимать будет нечего. Поэтому экзамен 306 идёт двумя ветками сразу: оркестрация ресурсов (Pacemaker, Corosync) и собственно данные (общие и распределённые ФС).
Команды и примеры
Прикинуть бюджет простоя из девяток - арифметика, которую полезно держать под рукой:
Код: Выделить всё
# минут простоя в год = 525600 * (1 - доступность)
# 99.9% -> 525600 * 0.001 = 525.6 мин (~8.8 ч)
# 99.99% -> 525600 * 0.0001 = 52.56 мин
# 99.999% -> 525600 * 0.00001 = 5.256 мин
python3 -c "print(525600*(1-0.9999), 'минут в год')"
Код: Выделить всё
# Debian 13 / Ubuntu 24.04 LTS
apt update
apt install -y pacemaker corosync pcs fence-agents-base
# RHEL 10 / Fedora 41+ (репозиторий HighAvailability)
dnf install -y pacemaker corosync pcs fence-agents-all
Код: Выделить всё
systemctl enable --now pcsd
pcs status # сводка по нодам и ресурсам
crm_mon -1 # снимок состояния один раз
corosync-cfgtool -s # видны ли соседи на кольце
Код: Выделить всё
# Debian/Ubuntu
dpkg -l pacemaker corosync | grep ^ii
cat /etc/os-release
# RHEL/Fedora
rpm -q pacemaker corosync pcs
- Путают резерв и HA. Ручное переключение - это не высокая доступность; без автоматики failover RTO остаётся часами.
- Считают, что репликация заменяет бэкап. Репликация мгновенно копирует и ошибку, и удаление; для RPO катастроф нужен независимый бэкап.
- Обещают бизнесу пять девяток, не убрав сетевые и питающие SPOF. Софтовый кластер на одном коммутаторе и одном вводе питания пять девяток не даст.
- Забывают про fencing. Кластер без изоляции сбойного узла рано или поздно поймает split-brain и порчу данных - это отдельная большая тема дальше по курсу.
- Берут устаревшие гайды с yum, pcs cluster setup старого синтаксиса и SysVinit-скриптами. В 2026 это dnf/dnf5, systemd и текущий синтаксис pcs.
- Поднимите две одинаковые виртуалки (RHEL 10 или Debian 13), задайте им имена node1 и node2, пропишите друг друга в /etc/hosts.
- Установите пакеты pacemaker, corosync, pcs из примеров выше под своё семейство.
- Включите и запустите pcsd через systemctl на обеих нодах.
- Выполните pcs status и зафиксируйте, что кластера ещё нет - это нормальная отправная точка.
- Для каждой ноды выпишите её потенциальные SPOF: диск, сеть, питание, гипервизор. Отметьте, какие из них в вашем стенде общие для обеих нод.
- Посчитайте допустимый годовой простой для целей 99.9 и 99.99 процента и сформулируйте, какой RTO и RPO вы хотите от будущего кластера.
- Чем высокая доступность отличается от простого резервирования, и почему дублирование без автоматики её не обеспечивает?
- Сколько минут простоя в год допускают четыре и пять девяток, и почему каждая следующая девятка дороже?
- В чём разница между RTO и RPO, и какими техническими средствами двигают каждую из этих метрик?
- Приведите три примера SPOF, которые софтовый кластер Pacemaker сам по себе не устраняет.
- Почему синхронная репликация даёт RPO около нуля, но не отменяет необходимости бэкапа?
- Какие две роли играют Corosync и Pacemaker и почему их разделяют?

