
В этом уроке разбираем, как Tarantool 3.x официально едет в продакшен: из чего складывается рабочая топология кластера, где лежит конфигурация, кто назначает лидеров и как всё это упаковывается в Docker. Мы сознательно держимся ЧИСТОГО стека - только официальные компоненты: бинарь tarantool, утилита tt, образ tarantool/tarantool, централизованное хранилище конфигурации (etcd или сам Tarantool как config storage) и, для Enterprise, Tarantool Cluster Manager (TCM). Никакого кастомного HAProxy и самописных оркестраторов.
Главная мысль урока: в 3.x кластер - это не набор отдельных Lua-скриптов, а единая декларативная YAML-конфигурация, которая описывает всю топологию сразу. Запущенные процессы tarantool лишь читают свой кусок этой конфигурации и принимают роль (лидер, реплика, роутер, стораж).
Механика и архитектура
Кирпичики топологии. Минимальная единица отказоустойчивости - реплика-сет (replicaset): один лидер на запись плюс одна-две реплики на чтение. Реплика-сеты объединяются в группы (groups), а группы образуют кластер. Внутри реплика-сета работает full-mesh репликация: каждый инстанс соединён с каждым, поэтому в сети должны быть открыты iproto-порты (по умолчанию 3301 и далее) между всеми узлами.
Декларативная конфигурация и иерархия. Конфигурация в 3.x строится по уровням: global -> group -> replicaset -> instance. Опция, заданная на верхнем уровне, наследуется вниз и может быть переопределена. Это позволяет, например, задать sharding.bucket_count один раз глобально, а advertise URI - на каждом инстансе. Топология описывается секциями groups -> replicasets -> instances.Официальное требование к продакшену: минимум ТРИ физических или виртуальных машины. На двух нельзя построить честный кворум для синхронной репликации и выборов - кластер из двух узлов при сетевом разрыве не сможет безопасно выбрать лидера.
Где живёт конфигурация. Два официальных способа:
- Локальный config.yaml рядом с каждым инстансом - просто, но конфиг надо раскатывать на все узлы синхронно.
- Централизованное хранилище: etcd или кластер Tarantool в роли config storage. Инстанс при старте получает в своём локальном config.yaml только адреса etcd (endpoints), префикс ключа (prefix) и креды, а саму топологию тянет из etcd. Изменили YAML в одном месте - все инстансы перечитали (режим auto или вручную). Это и есть продакшен-паттерн для больших кластеров. Важно: централизованное хранилище конфигурации - функция Enterprise Edition.
- off - все мастера фиксированы, ручное управление.
- manual - лидер каждого реплика-сета прописан в конфиге руками (через replicaset.leader).
- election - встроенные выборы на базе Raft: узлы сами выбирают лидера по кворуму. Обычно идёт в паре с синхронной репликацией.
- supervised - внешний координатор (официальный failover coordinator) читает конфигурацию из etcd, опрашивает инстансы и назначает лидера по их здоровью.
Docker. Официальный образ tarantool/tarantool содержит бинарь и популярные модули. В продакшене обычно: монтируем каталог с конфигом и кодом приложения внутрь контейнера, прокидываем порты iproto и HTTP-метрик, кладём снапшоты и WAL на персистентный volume (потеря volume = потеря данных). Внутри контейнера инстанс запускается через tt или напрямую tarantool с указанием своего имени.
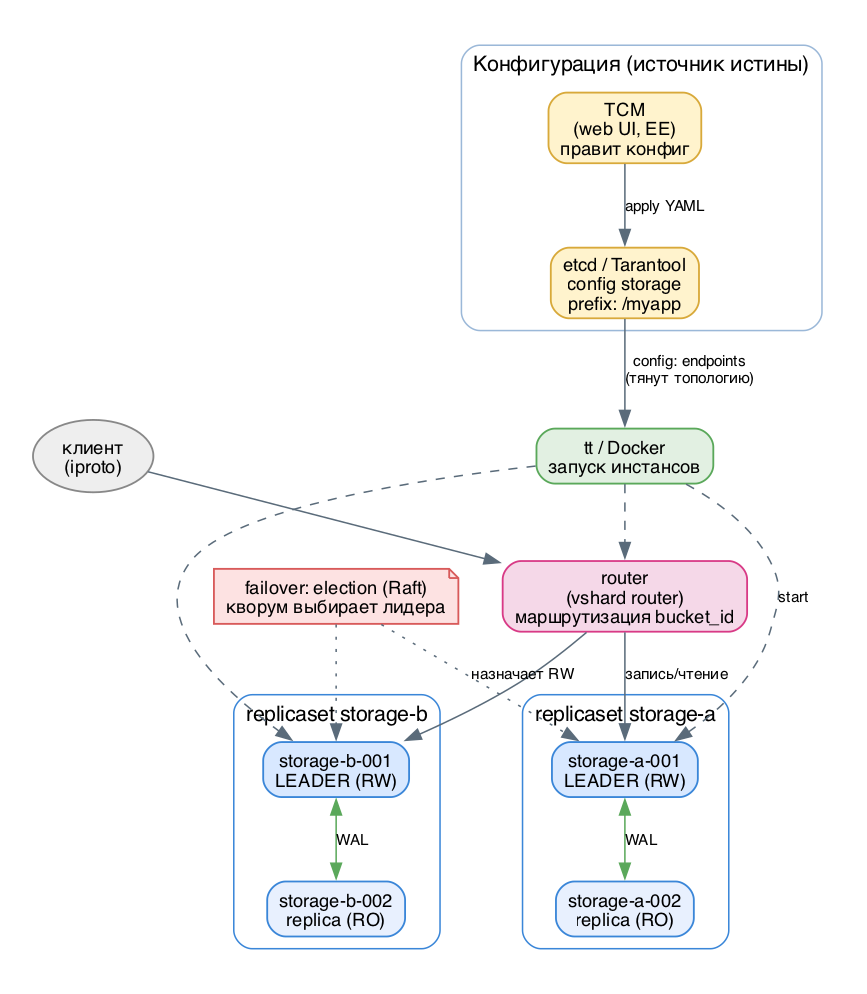
Продакшен-топология кластера Tarantool 3.x
Ключевые команды и код
Скелет config.yaml (топология двух реплика-сетов с выборами):
Код: Выделить всё
credentials:
users:
replicator:
password: 'topsecret'
roles: [ replication ]
iproto:
advertise:
peer:
login: replicator
replication:
failover: election # выборы на базе Raft
synchro_quorum: 2 # кворум для синхронной записи
groups:
storages:
replicasets:
storage-a:
instances:
storage-a-001: { iproto: { listen: [{uri: '127.0.0.1:3301'}] } }
storage-a-002: { iproto: { listen: [{uri: '127.0.0.1:3302'}] } }
storage-b:
instances:
storage-b-001: { iproto: { listen: [{uri: '127.0.0.1:3303'}] } }
storage-b-002: { iproto: { listen: [{uri: '127.0.0.1:3304'}] } }
Код: Выделить всё
config:
etcd:
endpoints:
- http://etcd-1:2379
- http://etcd-2:2379
- http://etcd-3:2379
prefix: /myapp
http:
request:
timeout: 3
Код: Выделить всё
$ tt start cluster
$ tt status cluster
INSTANCE STATUS PID MODE CONFIG BOX UPSTREAM
cluster:instance-001 RUNNING 8747 RW ready running --
cluster:instance-002 RUNNING 8748 RO ready running --
cluster:instance-003 RUNNING 8749 RO ready running --
Код: Выделить всё
$ docker run --name td -d \
-p 3301:3301 -p 8081:8081 \
-v /srv/myapp/cfg:/opt/tarantool \
-v /srv/myapp/data:/var/lib/tarantool \
tarantool/tarantool:3
Код: Выделить всё
режим кто решает кворум когда применять
----------- ------------------ ------- -----------------------
off оператор вручную нет статичные мастера
manual конфиг (leader:) нет простые, ручной контроль
election сами узлы (Raft) да авто-failover + синхрон
supervised внешний координатор да контроль из etcd/TCM
- Кластер из двух узлов. Кажется отказоустойчивым, но кворум 2 из 2 недостижим при разрыве - запись встаёт. Нужно минимум три узла (или три участника выборов).
- election без синхронной репликации. Авто-выборы сами по себе почти не защищают данные: новый лидер может оказаться без последних транзакций. Защита появляется только вместе с синхронной репликацией.
- Redo, а не undo. У Tarantool журнал на повтор, отката нет. Если после выборов реплика оказалась впереди нового лидера, её удаляют и перекачивают данные заново. Это нормальное, но болезненное поведение - не пугайтесь.
- Зависшая синхро-очередь. При смене лидера незавершённые синхронные транзакции прошлого мастера могут потребовать ручного box.ctl.promote() или очистки очереди. Закладывайте это в runbook.
- Volume в Docker. Снапшоты и WAL внутри контейнера без внешнего volume исчезают при пересоздании контейнера. Это самая частая потеря данных у новичков.
- Закрытый full-mesh. Забыли открыть iproto-порты между всеми узлами реплика-сета - репликация молча не поднимается. Mesh требует связности каждый-с-каждым.
- Пароли в YAML. Официально не рекомендуется хранить пароли открытым текстом - грузите их из переменных окружения или внешних файлов.
Задание: соберите локально кластер из трёх инстансов в одном реплика-сете с режимом replication.failover: election.
- Выполните tt init, создайте каталог instances.enabled/cluster.
- В instances.yml перечислите три инстанса, в config.yaml опишите один реплика-сет с тремя instances и опцией failover: election.
- Запустите tt start cluster и tt status cluster - убедитесь, что один инстанс в режиме RW, два в RO.
- Подключитесь к лидеру (tt connect), создайте спейс, запишите тапл, прочитайте его на реплике.
- Остановите лидера (tt stop одного инстанса) и через tt status посмотрите, как RW-роль переехала на другой узел.
- Почему официально требуется минимум три узла, и что произойдёт с записью в кластере из двух узлов при сетевом разрыве?
- В чём разница между режимами failover election и supervised: кто в каждом случае принимает решение о лидере?
- Зачем election почти бесполезен для сохранности данных без синхронной репликации?
- Какие данные нужно вынести на персистентный Docker volume, чтобы не потерять состояние при пересоздании контейнера, и где в конфиге указываются адреса централизованного хранилища конфигурации?