
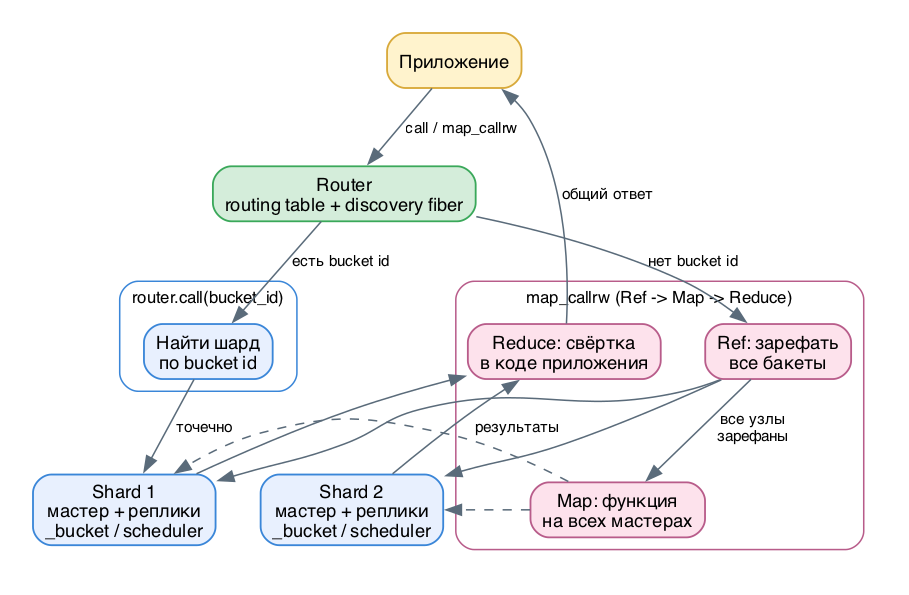
В шардированном кластере приложение никогда не ходит на storage напрямую. Все запросы проходят через router, и у него есть ровно две модели доступа.
- Точечный вызов по bucket id - вы знаете ключ шардирования, router находит нужный шард и зовёт функцию только на нём. Это vshard.router.call (и его варианты callrw/callro).
- Map-reduce поверх всех шардов - bucket id неизвестен или нужны данные со всего кластера. Router рассылает одну функцию на все мастера и собирает ответы. Это vshard.router.map_callrw.
Механика точечного вызоваГлавное правило: единственная операция, которую понимает router, - это call. Любой SELECT, INSERT, любая хранимка попадают на storage только как аргумент router-вызова. Router не знает вашу схему данных, он знает только карту bucket id -> replica set.
Router держит routing table - карту всех bucket id на replica set. При старте он создаёт постоянный пул соединений ко всем storage и кэширует эту карту. Фоновый discovery fiber периодически обновляет её, чтобы переезд бакета при ребалансе или фейловер мастера были прозрачны для приложения.
Код: Выделить всё
result = vshard.router.call(bucket_id, mode, func_name, {args}, {opts})
-- mode = 'read' -> vshard.router.callro (можно на реплику)
-- mode = 'write' -> vshard.router.callrw (только мастер)
- Router берёт bucket_id и ищет replica set в routing table. Если бакет ещё не известен (discovery не дошёл), router спрашивает у всех storage, где он.
- Найдя шард, router зовёт функцию на нужном узле. На storage срабатывает проверка: бакет реально лежит в этом _bucket, и он в состоянии ACTIVE или PINNED (для чтения допустим ещё SENDING).
- Если проверка провалилась (бакет уехал) - storage возвращает специальную ошибку с новым местоположением, router обновляет карту и сам ретраит. Прикладной код этого не видит.
Mode и предпочтения чтения. Для чтения mode можно расширить: prefer_replica=true (читать с реплики, разгрузить мастер), balance=true (раскидывать чтения по узлам по политике балансировки vshard). Запись всегда идёт на мастер.
Router call и map-reduce поверх шардов
Механика map-reduce: Ref, Map, Reduce
vshard.router.map_callrw не принимает bucket id. Он рассылает одну и ту же функцию на мастера всех replica set, и эта функция работает со всеми локальными данными узла независимо от bucket id. Зачем три стадии? Чтобы гарантировать консистентность: ни один бакет не должен переехать между узлами, пока выполняется обход.
- Ref - router сначала просит каждый storage поставить общую RO-ссылку на все свои бакеты разом. Пока ссылка жива, ребалансер не может вынести данные с узла. Если хоть один storage не смог зарефать (идёт миграция, мастер недоступен) - вся операция падает, частичных результатов нет.
- Map - только после успешного Ref на всех узлах router зовёт вашу функцию на каждом мастере. Функция уже уверена, что видит полный и неподвижный срез своих данных.
- Reduce - этой стадии в vshard нет. map_callrw отдаёт вам map вида {replicaset_uuid = результат}, а сворачивать (суммировать, склеивать, дедуплицировать) вы должны сами в прикладном коде.
Код: Выделить всё
local map, err = vshard.router.map_callrw(
'count_local_bands', -- имя функции, объявленной на storage
{}, -- аргументы
{timeout = 5} -- таймаут на ВСЮ операцию
)
-- success: map = { ['uuid-1'] = {42}, ['uuid-2'] = {37} }
-- fail: map = nil, err, [uuid] -- где случилась ошибка
local total = 0
for _, res in pairs(map) do total = total + res[1] end
Модуль crud: map-reduce без ручного bucket id
Писать router.call с вычислением bucket id под каждый запрос утомительно. Модуль crud (официальный rock) даёт привычный CRUD-интерфейс поверх vshard и сам выбирает стратегию.
Код: Выделить всё
local crud = require('crud')
-- INSERT: crud сам считает bucket_id из ключа шардирования
crud.insert('bands', {1, box.NULL, 'Scorpions', 1965})
-- GET по первичному ключу: точечный вызов в нужный шард
crud.get('bands', 1)
-- SELECT с условием по НЕ ключу шардирования: map-reduce!
crud.select('bands', {{'>=', 'year', 2000}}, {first = 100})
Код: Выделить всё
условие содержит ключ шардирования -> один шард (точечно)
условие НЕ содержит ключ шардирования -> обход всех шардов (map-reduce)
Частые заблуждения и грабли
- map_callrw - не аналог callro. Несмотря на имя rw, его используют и для чтений по всему кластеру. rw здесь означает, что он ходит на мастера и держит refs; на реплики он не пойдёт.
- map_callrw требует живых мастеров везде. Если хоть в одном replica set мастер лёг, Ref не пройдёт - вся операция упадёт. Точечный callro в это время продолжит работать с реплик.
- Reduce за вас никто не сделает. Частая ошибка - ждать готовую сумму. Вы получаете map по узлам и сворачиваете сами.
- Огромные таймауты на map-reduce - вредны. Refs на все бакеты блокируют ребаланс на это время. Минуты держать refs - плохая практика (кроме тестов).
- crud.select без ключа шардирования - это скрытый map-reduce по всему кластеру. На больших данных это дорого: лучше фильтровать по ключу шардирования или ограничивать first.
- Запись неидемпотентна. callrw нельзя слепо ретраить: ответ мог потеряться по таймауту уже после применения. Встроенной дедупликации нет - проверку "применено ли уже" пишете сами (например, по уникальному id вставки). Для чтений безопасный ретрай даёт пара timeout + request_timeout (timeout > request_timeout).
На развёрнутом sharded-кластере из учебных примеров (router + 2 storage с пространством bands):
- Сделайте точечный crud.get('bands', N) и crud.insert - убедитесь, что данные легли в один шард (посмотрите bucket_id в результате).
- Сделайте crud.select('bands', {{'>=', 'year', 1990}}) без ключа шардирования и заметьте, что ответ собран с обоих storage (это и есть map-reduce).
- Бонус: на storage объявьте функцию count_local() и вызовите vshard.router.map_callrw('count_local', {}, {timeout=5}); сложите счётчики из map вручную.
- Почему единственная операция router - это call, и как тогда выполняется SELECT приложения?
- Что делает стадия Ref в map_callrw и почему без неё нельзя гарантировать консистентность?
- По какому признаку crud.select выбирает между точечным запросом и обходом всех шардов?
- Почему нельзя ставить таймаут в минуты на map_callrw и какой компонент storage за это отвечает?