
Tarantool Cartridge - это официальный фреймворк для распределённых приложений, который много лет был штатным способом собирать кластер на Tarantool 1.10 и 2.x. До 3.x у самого ядра не было ни декларативной конфигурации, ни встроенной оркестрации топологии: голый instance умел только box.cfg() и репликацию. Cartridge закрыл эту дыру - он дал шаблон приложения, упаковку в RPM/DEB/tgz, веб-интерфейс администрирования, автоматический failover, встроенный шардинг через vshard и понятие ролей. По сути это был "application server" поверх Tarantool.
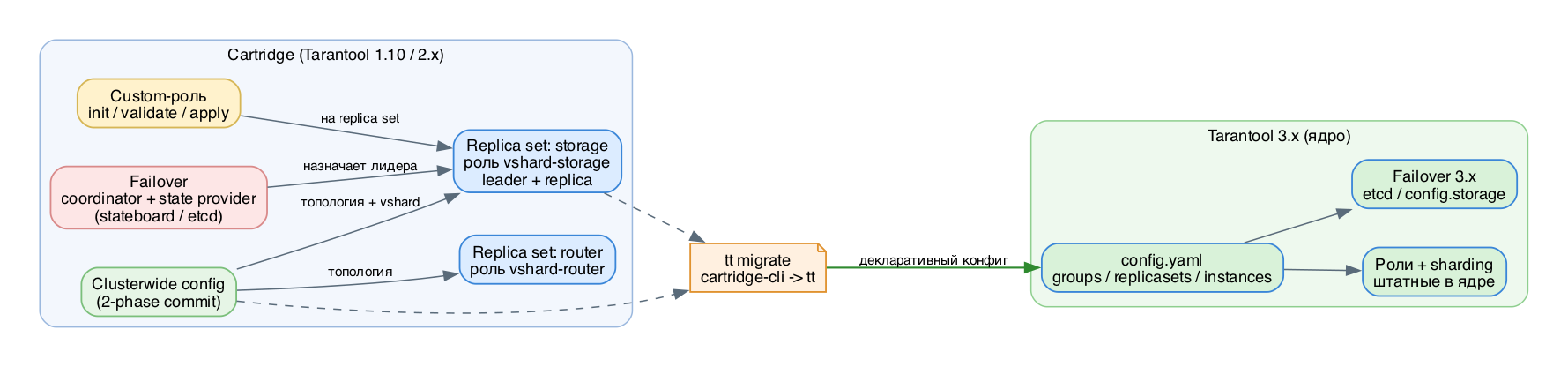
Как Cartridge устроен внутриГлавное, что нужно зафиксировать сразу: Cartridge несовместим с Tarantool 3.0 и выше. Он поддерживает только ветки 1.10 и 2.x. Это не баг, а архитектурное решение - в 3.x задачи Cartridge встроили прямо в ядро (декларативный config, роли, управление топологией). Поэтому Cartridge сегодня - официальный legacy, и каждый новый проект надо начинать на 3.x.
Роли (cluster roles)
Роль - это просто Lua-модуль с предопределёнными callback-функциями. Cartridge сегрегирует функциональность инстансов по ролям: все инстансы запускают один и тот же код приложения и знают про все объявленные роли, но реально включены на конкретном инстансе только нужные. Важная деталь механики: роли назначаются на replica set целиком, а не на отдельный инстанс - все инстансы одного набора реплик несут одинаковый набор ролей. Роли можно включать и выключать на лету, без рестарта.
Встроенных ролей две, обе про шардинг через vshard:
- vshard-router - маршрутизирует запросы по bucket_id к нужному storage (compute-нагрузка);
- vshard-storage - хранит и обслуживает подмножество данных (transaction-нагрузка).
Жизненный цикл роли
Cartridge вызывает у роли строго определённый набор функций в строго определённом порядке. При join инстанса или рестарте с включённой ролью порядок такой:
- validate_config(conf_new, conf_old) - проверить новую конфигурацию (вызывается ДО автоматического box.cfg(), поэтому box-функции надо оборачивать в проверку type(box.cfg) == 'table');
- init(opts) - инициализация: создать спейсы/индексы (только на мастере, через opts.is_master), запустить fiber, повесить HTTP-роуты;
- apply_config(conf, opts) - применить конфигурацию (уже после box.cfg(), box-функции можно звать свободно, но создавать спейсы - только на мастере).
Clusterwide-конфигурация и two-phase commit
Сердце Cartridge - распределённая конфигурация, единая для всего кластера (топология, vshard, failover, auth, ваши custom-секции). Каждый инстанс хранит копию config.yml в своём workdir. Изменение проходит через cartridge.confapplier.patch_clusterwide() и идёт двухфазным коммитом:
- Preparation phase - патч рассылается всем живым инстансам, каждый прогоняет validate_config() всех ролей и пишет config.prepare.yml. Если хоть один отверг - Abort phase, все откатываются.
- Commit phase - при общем успехе каждый инстанс атомарно подменяет активный конфиг на prepared и зовёт apply_config() всех ролей.
Топология и failover
Топология - это инстансы (каждый со своим instance UUID и advertise_uri), сгруппированные в replica sets (каждый со своим replicaset UUID). У набора есть failover priority - упорядоченный список, первый здоровый становится лидером (writable master). Режимов failover три:
- disabled - лидер всегда первый в списке, автопереключения нет;
- eventual - каждый инстанс сам решает, кто лидер, по статусу членства (протокол SWIM); не рекомендуется на больших highload-кластерах из-за гонок и "failover storms";
- stateful - решение принимает один coordinator (тоже роль), а карта лидерства лежит во внешнем state provider: stateboard (отдельный инстанс Tarantool) или etcd. Coordinator берёт распределённый lock, и только держатель lock-а назначает лидеров.
Топология Cartridge и путь миграции на Tarantool 3.x
Ключевые команды и код
Точка входа приложения (init.lua) - box.cfg() звать нельзя, его за вас вызовет кластер:
Код: Выделить всё
local cartridge = require('cartridge')
cartridge.cfg({
advertise_uri = 'localhost:3301',
cluster_cookie = 'super-cluster-cookie',
http_port = 8081,
roles = {'custom-role'}, -- список своих ролей
}, {
memtx_memory = 1000 * 1024 * 1024, -- это box-опции
})
Код: Выделить всё
local function init(opts)
if opts.is_master then -- спейсы создаём только на лидере
local s = box.schema.space.create('customer', {if_not_exists = true})
s:format({{'customer_id','unsigned'},{'bucket_id','unsigned'},{'name','string'}})
s:create_index('pk', {parts = {'customer_id'}, if_not_exists = true})
end
end
return {
role_name = 'custom-role',
dependencies = {'cartridge.roles.vshard-router'},
init = init,
}
Код: Выделить всё
cartridge create --name myapp
cartridge build
cartridge start -d
cartridge replicasets setup --bootstrap-vshard
cartridge failover set stateful --state-provider stateboard \
--provider-params '{"uri":"localhost:4401","password":"passwd"}'
В 3.x всё, что давал Cartridge, переехало в ядро: декларативный YAML-конфиг, роли как штатная сущность, управление топологией и replicaset-ами. Дорожная карта:
Код: Выделить всё
Шаг 1. Перейти с cartridge-cli на tt (он deprecated).
tt init -> команды cartridge становятся "tt cartridge ..."
Шаг 2. Заморозить запись и снять дамп схемы/данных со storage-ов.
Шаг 3. Переписать clusterwide config.yml -> декларативный config.yaml 3.x:
groups -> replicasets -> instances; роли в секции roles/sharding.
Шаг 4. Перенести custom-роли на API ролей 3.x (validate/apply/init по новому).
Шаг 5. failover: stateboard/etcd -> штатный failover 3.x
(etcd/config.storage как provider).
Шаг 6. Поднять 3.x-кластер, восстановить данные, проверить box.info.replication.
Частые заблуждения и грабли
- "Cartridge заведётся на 3.x, если подобрать версию" - нет. Граница жёсткая: 1.10/2.x только. Никакая версия Cartridge 2.x не поддерживает ядро 3.0+.
- Вызов box.cfg() руками в init.lua - запрещён, кластер делает это сам. Ручной вызов ломает bootstrap.
- box-функции в validate_config() без проверки type(box.cfg)=='table' падают, потому что валидация может идти ДО box.cfg().
- Создание спейсов/юзеров не под if opts.is_master - даёт коллизии репликации (объект создаётся и на мастере, и на реплике одновременно).
- Роль включают "на инстанс" - на самом деле на весь replica set; индивидуально на одном инстансе набора роль не выключить.
- При миграции/перебутстрапе путают UUID: replicaset UUID должны совпадать, а instance UUID - различаться, иначе новый кластер не поднимется по текущей bootstrap-политике.
- eventual failover на highload - источник гонок и failover storms (ложные SWIM-гипотезы); в проде берите stateful с etcd.
- Частичный сбой two-phase commit Cartridge не лечит автоматически - чините конфиг руками, поэтому вся логика проверок должна быть в validate_config().
Возьмите README быстрого старта и разверните локальный Cartridge-кластер: cartridge create / build / start -d, затем в веб-интерфейсе на http://localhost:8081 соберите топологию из роутера и одного storage-набора, включите роль vshard-storage и bootstrap-нете vshard. После этого откройте config.yml в workdir любого инстанса и найдите там секции topology, vshard и failover. Задание: на листе бумаги выпишите, какие из этих секций в Tarantool 3.x превратятся в groups/replicasets/instances декларативного config.yaml, а какие - в секцию sharding.
Контрольные вопросы
- На какой уровень топологии назначаются роли в Cartridge - на инстанс или на replica set, и почему это важно при включении vshard-storage?
- В каком порядке кластер вызывает функции роли при join инстанса, и почему box-функции в validate_config() надо оборачивать в проверку type(box.cfg) == 'table'?
- Опишите две фазы patch_clusterwide(): что происходит в preparation и в commit, и что будет, если один инстанс отвергнет конфиг в validate_config()?
- Чем stateful failover отличается от eventual по механике принятия решения о лидере, и какие два state provider он поддерживает?