
Файловая система ломается не только от сбоя диска, но и от внезапного выключения, паники ядра или просто от старости железа. Задача администратора - вовремя увидеть, что место или иноды кончаются, понять, в каком состоянии метаданные, и при необходимости провести проверку и ремонт так, чтобы не сделать хуже. В этом уроке разбираем учёт места (df, du), проверку и ремонт ext4 и XFS, чтение и правку метаданных (tune2fs, dumpe2fs, xfs_info, xfs_db) и базовую осведомлённость о здоровье диска через SMART.
Как это работает
Любая ФС хранит две принципиально разные вещи: данные файлов и метаданные (карта свободных блоков, таблица инодов, журнал, ссылки каталогов). Когда вы видите No space left on device, причина бывает двух сортов: кончились блоки данных или кончились свободные иноды. Это разные ресурсы. Один инод - это запись об объекте (файле, каталоге, симлинке); миллион пустых файлов забьёт иноды при куче свободных гигабайт. Поэтому df показывают и то, и другое.
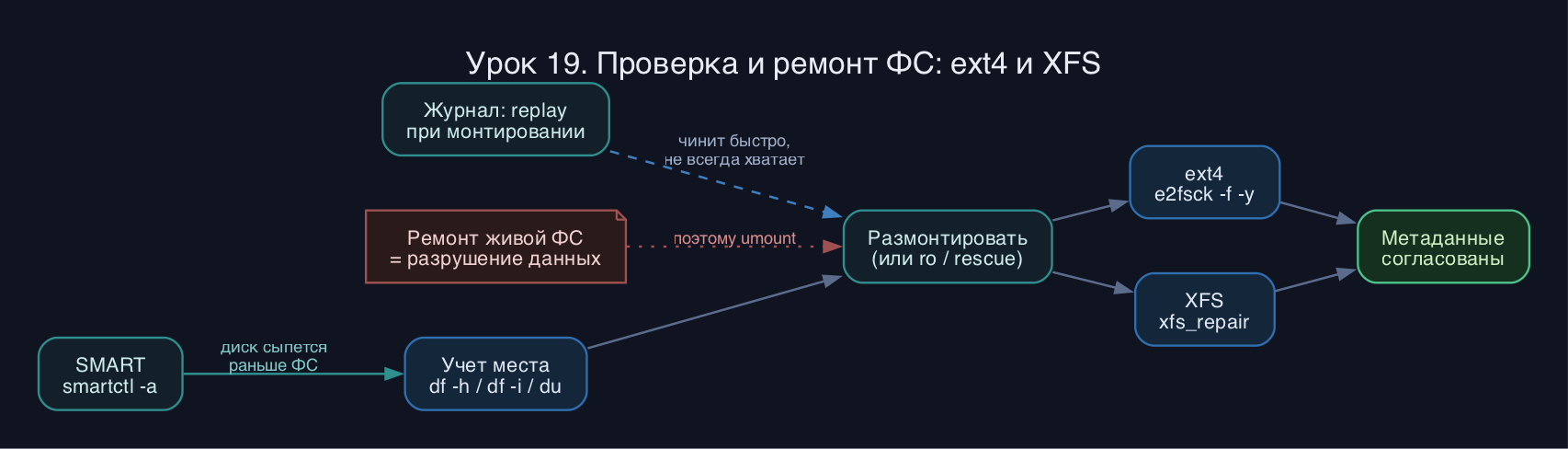
Журналируемые ФС (ext3/ext4, XFS) ведут журнал: перед изменением метаданных операция сначала пишется в журнал, и только потом применяется к самой ФС. После сбоя система при монтировании проигрывает журнал (replay) и приводит метаданные в согласованное состояние за секунды. Это не отменяет полную проверку насовсем, но делает её редкой: журнал защищает структуру, а не содержимое ваших файлов.
Главное правило ремонта: проверять и чинить нужно размонтированную ФС или смонтированную в режиме только-чтение. Если чинить живую ФС, ядро держит в памяти кэш метаданных, а инструмент правит их на диске - вы получите рассинхрон и реальное разрушение данных. Для корня это значит загрузку в rescue/initramfs или с live-носителя.
И ключевое различие семейств: ext4 чинят оффлайн через fsck/e2fsck, а XFS устроена иначе. При штатной загрузке XFS сама делает journal replay; отдельной проверки на каждый монтаж нет, а ремонт делается утилитой xfs_repair, причём только на размонтированной ФС. fsck.xfs специально ничего не делает (это заглушка), чтобы автозагрузка не трогала XFS зря.
Команды и примеры
Свободное место и иноды:
Код: Выделить всё
df -h # человекочитаемые размеры (G/M/K)
df -i # счётчик инодов: всего, занято, свободно, %
df -hT /var # с типом ФС, по конкретной точке монтирования
Код: Выделить всё
du -sh /var/* # суммарный размер каждого подкаталога
du -h --max-depth=1 / # то же, но через ограничение глубины
du -xsh / # -x не уходить на другие ФС (не считать /proc, mounts)
Код: Выделить всё
umount /dev/sdb1
fsck /dev/sdb1 # fsck сам выбирает e2fsck по типу ФС
e2fsck -f -y /dev/sdb1 # -f форс даже если ФС помечена чистой, -y на всё да
e2fsck -p /dev/sdb1 # preen: чинить только безопасное автоматически
Код: Выделить всё
umount /dev/sdb1
xfs_repair /dev/sdb1 # основной ремонт оффлайн
xfs_repair -n /dev/sdb1 # -n только проверка, без записи (dry-run)
xfs_repair -L /dev/sdb1 # обнулить повреждённый журнал - крайняя мера, риск потери
Код: Выделить всё
dumpe2fs /dev/sdb1 # суперблок, группы блоков, параметры
dumpe2fs -h /dev/sdb1 # только заголовок (короткий, читаемый)
tune2fs -l /dev/sdb1 # листинг параметров суперблока
tune2fs -m 1 /dev/sdb1 # резерв для root с 5% до 1%
tune2fs -c 30 -i 2w /dev/sdb1 # принудительный fsck каждые 30 монтирований или 2 недели
tune2fs -L data /dev/sdb1 # задать метку (label) тома
Код: Выделить всё
xfs_info /mnt/data # геометрия: размер блока, allocation groups, лог
xfs_db -c "sb 0" -c "p" /dev/sdb1 # эксперту: чтение суперблока, опасно на rw
Код: Выделить всё
smartctl -H /dev/sda # общий вердикт PASSED/FAILED
smartctl -a /dev/sda # все атрибуты: Reallocated_Sector_Ct, Pending и т.д.
smartctl -t short /dev/sda # запустить короткий самотест
Частые грабли
- Запуск fsck/e2fsck/xfs_repair на смонтированной ФС - почти гарантированное разрушение. Всегда umount, для корня - загрузка с live или в rescue.
- e2fsck без -f на чистой ФС просто выходит, ничего не проверив. Если нужна реальная проверка - добавляйте -f.
- Ожидание, что fsck.xfs что-то чинит. Это пустышка; ремонт только xfs_repair.
- xfs_repair -L обнуляет журнал и может потерять незаписанные изменения. Это последний шанс, а не штатный ключ.
- No space left при свободных гигабайтах - проверьте df -i: кончились иноды.
- Удалённый файл, который держит открытым процесс, место не освобождает - смотрите lsof, df покажет старую занятость до перезапуска процесса.
- du и df расходятся из-за sparse-файлов, удалённых-но-открытых файлов и разной единицы счёта - это нормально, не баг.
- SMART PASSED не гарантия: диск может сыпаться при растущих Pending/Reallocated секторах. Смотрите атрибуты, а не только вердикт.
- Создайте файл-образ: dd if=/dev/zero of=/tmp/disk.img bs=1M count=200, сделайте loop-устройство через losetup или сразу mkfs.ext4 /tmp/disk.img.
- Смонтируйте, заполните мелкими файлами (touch в цикле) и сравните df -h и df -i - убедитесь, что иноды кончаются раньше места.
- Снимите параметры: dumpe2fs -h на образе, найдите Inode count и Reserved block count.
- Размонтируйте и выполните e2fsck -f -y - посмотрите фазы проверки.
- Создайте второй образ с mkfs.xfs, смонтируйте, посмотрите xfs_info, размонтируйте и прогоните xfs_repair -n.
- На реальном диске выполните smartctl -H и smartctl -a, найдите атрибуты Reallocated_Sector_Ct и Current_Pending_Sector.
- Чем отличается исчерпание блоков от исчерпания инодов и какой ключ df покажет второе?
- Почему e2fsck нельзя запускать на смонтированной ФС и как проверить корневую ФС?
- Что делает fsck.xfs и какой утилитой реально чинят XFS?
- Зачем нужен ключ -f у e2fsck, если ФС помечена чистой?
- Какой командой задать резерв блоков для root на ext4 в 1% и зачем этот резерв вообще нужен?
- Что означает journal replay при монтировании и почему он не заменяет полный fsck?

