
Регулярные выражения - это язык описания текстовых шаблонов, и без него администратор слеп. Найти строки с ошибками в логе на гигабайт, выдрать IP из access.log, поправить параметр в десятке конфигов одним проходом sed - всё это про регэкспы. В уроке разберём, чем BRE отличается от ERE, как работают якоря, классы и кванторы, и почему grep, egrep и sed понимают шаблоны по-разному. На экзамене 103.7 эти различия спрашивают прямо, а на проде они экономят часы.
Как это работает
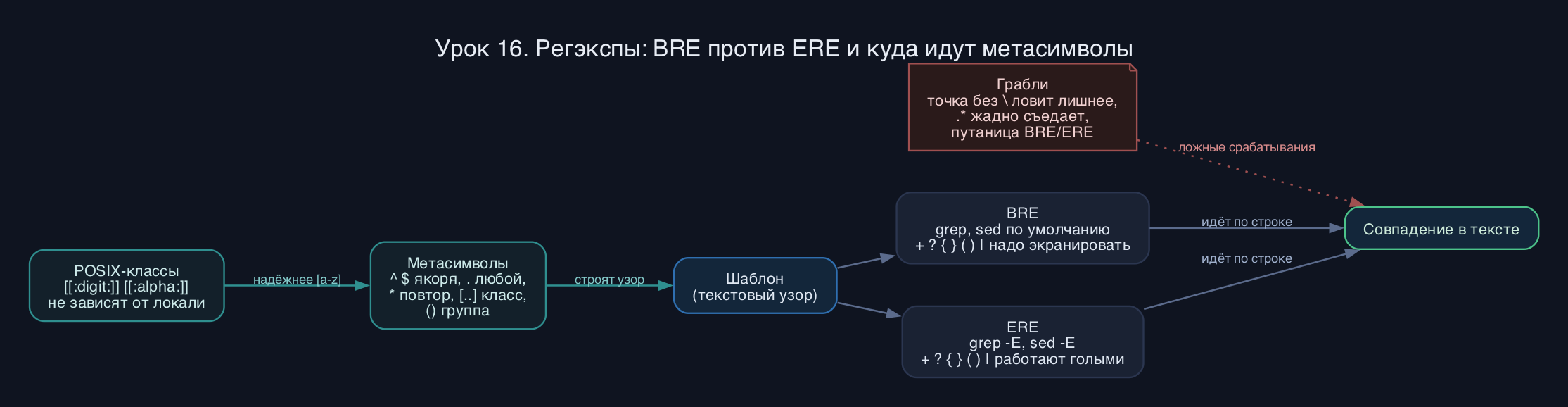
Регулярное выражение - это не строка для поиска, а программа для маленькой машины (автомата), которая идёт по тексту слева направо и проверяет, складывается ли шаблон. Большинство символов означают сами себя, но часть символов - метасимволы - имеют особый смысл: точка, звёздочка, скобки, якоря. Если нужен буквальный метасимвол, его экранируют обратным слешем.
Исторически в Unix сложились два диалекта. BRE (Basic Regular Expressions) - старый и консервативный: метасимволы плюс, вопрос, фигурные скобки, круглые скобки и вертикальная черта в нём работают только если их экранировать обратным слешем. ERE (Extended Regular Expressions) - расширенный: те же символы спецсимволичны сами по себе, без слеша. Это главный источник путаницы. grep по умолчанию говорит на BRE, grep -E (бывший egrep) - на ERE, sed без ключа - на BRE, sed -E - на ERE.
Точка означает один любой символ. Звёздочка - повтор предыдущего элемента ноль и более раз, она жадная и хватает максимально длинную строку. Якоря ^ и $ привязывают шаблон к началу и концу строки, они не съедают символов, а лишь обозначают позицию. Квадратные скобки задают класс - набор символов, любой один из которых подойдёт: [abc] это a или b или c, диапазон [a-z] это любая строчная латинская. Внутри класса метасимволы теряют силу, а ^ первым символом инвертирует набор: [^0-9] это всё, кроме цифры.
Группировка в круглых скобках позволяет применить квантор к целому куску и запомнить совпавшее для обратной ссылки. Альтернация (вертикальная черта) - это логическое или между вариантами. В замене sed запомненную группу подставляют как \1, \2 и так далее, а весь матч - амперсандом.
Отдельно стоит запомнить про локаль. Диапазоны вроде [a-z] зависят от переменной LC_COLLATE: в некоторых локалях порядок сортировки перемешивает регистры, и [a-z] неожиданно зацепит не то. Поэтому для предсказуемости либо ставят LC_ALL=C, либо используют POSIX-классы: [[:alpha:]], [[:digit:]], [[:space:]], [[:alnum:]], [[:upper:]], [[:punct:]]. Двойные скобки тут не опечатка: [:digit:] это имя класса, а внешние [ ] - сам класс символов.
Команды и примеры
Поиск строк с ошибками в логе, регистронезависимо, с номерами строк:
Код: Выделить всё
grep -in 'error' /var/log/syslogКод: Выделить всё
# BRE: плюс надо экранировать
grep 'ca.' file.txt
# ERE: один-или-более через голый +
grep -E 'colou?r' file.txt #找 color и colourКод: Выделить всё
grep -Eo '([0-9]{1,3}\.){3}[0-9]{1,3}' /var/log/nginx/access.log | sort -uPOSIX-классы вместо хрупких диапазонов. Строки, начинающиеся с буквы:
Код: Выделить всё
grep '^[[:alpha:]]' /etc/passwdКод: Выделить всё
grep -F '10.0.0.1' hosts # точка тут буквальная, не метасимволКод: Выделить всё
sed 's/foo/bar/' file # первое в строке
sed 's/foo/bar/g' file # все в строке
sed -i 's/foo/bar/g' file # на месте, правит файлКод: Выделить всё
echo 'имя:значение' | sed -E 's/^([^:]+):(.+)$/\2:\1/'Код: Выделить всё
sed -i -E 's/^#[[:space:]]*(PermitRootLogin.*)/\1/' /etc/ssh/sshd_configКод: Выделить всё
echo 'порт 8080' | sed -E 's/[0-9]+/(&)/g'Частые грабли
- Путаница BRE/ERE: написали grep 'a+b' и удивляетесь, что не находит a+b как один-или-более. В BRE плюс буквальный, нужен grep -E или a\+b.
- Жадность звёздочки и .* в sed: шаблон .* хватает до конца строки, и замена съедает больше, чем хотелось. Сужайте через [^x]* или конкретные классы.
- Незаэкранированная точка в IP и версиях: 10.0.0.1 совпадёт и с 10X0Y0Z1. Для буквальной точки - \. или grep -F.
- Диапазон [a-Z] невалиден или ловит лишнее из-за локали. Используйте [[:alpha:]] или LC_ALL=C.
- Якоря в середине: ^ и $ это не символы строки, а позиции. grep 'a$b' не найдёт ничего, потому что после конца строки символов нет.
- egrep и fgrep объявлены устаревшими в современном GNU grep и печатают предупреждение - пишите grep -E и grep -F.
- sed -i без бэкапа правит файл необратимо. На проде сначала прогоните без -i и посмотрите вывод, либо sed -i.bak.
- Возьмите свой /var/log (syslog или journalctl --no-pager > log.txt) как полигон.
- Командой grep с -i и -c посчитайте строки, содержащие fail или error, сравните BRE и ERE-варианты альтернации.
- Через grep -Eo выдерните все IPv4 и прогоните через sort -u | wc -l - сколько уникальных адресов.
- Сделайте копию sshd_config и одной командой sed закомментируйте строку с PasswordAuthentication, добавив # в начало.
- Той же копией поменяйте обратно, сняв комментарий через группу и обратную ссылку \1.
- Напишите шаблон с POSIX-классом, который вытащит из лога временные метки вида HH:MM:SS.
- Сравните вывод grep 'a.b' и grep -F 'a.b' на строке a.b и axb - убедитесь в разнице.
- Чем отличается обработка символов + ? { } ( ) | в BRE и ERE и какими ключами grep и sed переключаются между ними?
- Что найдёт шаблон ^[^#] и где это применяют при работе с конфигами?
- В чём разница между . и [.] внутри регэкспа и когда нужен grep -F?
- Как в sed сослаться на запомненную группу и на весь найденный фрагмент в строке замены?
- Почему [[:digit:]] предпочтительнее [0-9] и при чём тут переменная LC_COLLATE?
- Что делает квантор * применительно к предыдущему элементу и почему он называется жадным?

