
Базовый ip addr и один шлюз по умолчанию хватает на простом хосте. Но как только сервер смотрит в две сети, агрегирует интерфейсы ради отказоустойчивости или вы ловите плавающий сбой в проде, нужен инструментарий посерьёзнее. В этом уроке разбираем policy routing с несколькими таблицами маршрутизации, мосты и туннели, агрегацию каналов (bonding и его наследника team) и набор для анализа трафика: tcpdump, tshark, netcat и socat. Всё через современный пакет iproute2, потому что ifconfig и route в 2026 - легаси, которое во многих дистрибутивах даже не ставится по умолчанию.
Как это работает
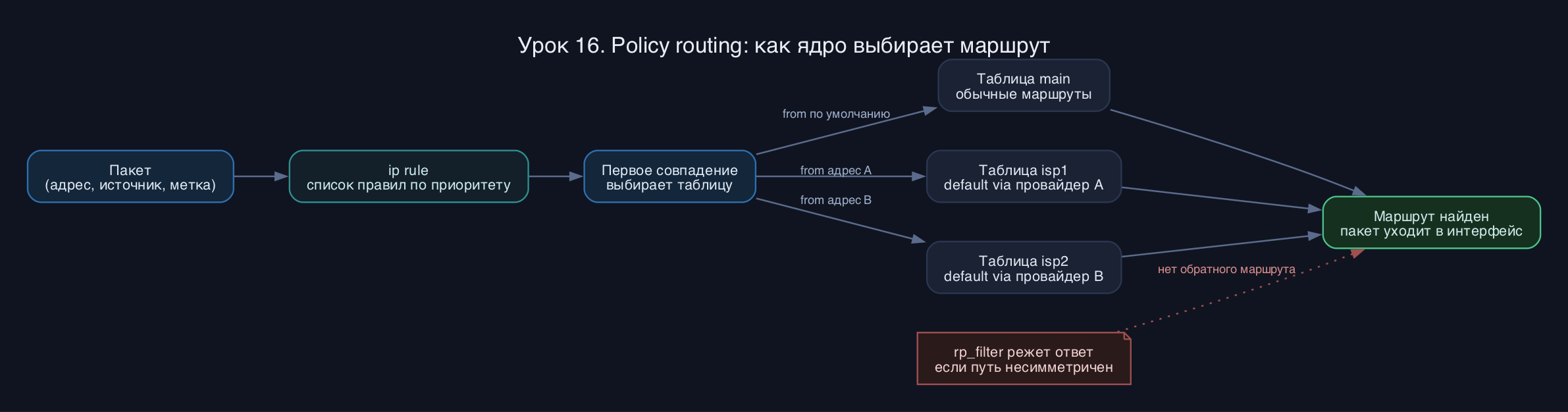
Ядро Linux принимает решение о маршруте не по одной таблице, а по набору правил (ip rule). Каждый пакет прогоняется сверху вниз по списку правил, и первое подходящее правило указывает, в какой таблице маршрутизации искать маршрут. По умолчанию есть три таблицы: local (приоритет 0, локальные и широковещательные адреса, трогать нельзя), main (приоритет 32766, ваши обычные маршруты) и default (приоритет 32767). Это и есть policy routing - маршрут выбирается не только по адресу назначения, но и по источнику, метке, интерфейсу.
Зачем это надо. Классика - сервер с двумя провайдерами. Ответ на пакет, пришедший через провайдера B, должен уйти обратно через B, иначе провайдер с проверкой обратного пути (reverse path filter) его выкинет. Решается двумя дополнительными таблицами и правилами by source address.
Мост (bridge) - это виртуальный коммутатор второго уровня внутри ядра. Он объединяет интерфейсы в один широковещательный домен, обучается MAC-адресам и форвардит кадры. Основа сети контейнеров и виртуалок: docker0, virbr0 - это всё бриджи.
Агрегация каналов объединяет несколько физических NIC в один логический ради пропускной способности или резерва. Старый механизм bonding живёт в модуле ядра и настраивается через драйвер. Более новый teaming вынес логику в userspace-демон teamd, что гибче, но в энтерпрайзе bonding по-прежнему доминирует, и LACP (802.3ad) - стандарт для связки с управляемым коммутатором.
Команды и примеры
Policy routing для двух аплинков. Создаём именованные таблицы в /etc/iproute2/rt_tables, затем наполняем их и навешиваем правила.
Код: Выделить всё
# справочник таблиц (добавить строки)
echo "100 isp1" >> /etc/iproute2/rt_tables
echo "200 isp2" >> /etc/iproute2/rt_tables
# маршрут по умолчанию в каждой таблице
ip route add default via 203.0.113.1 dev eth0 table isp1
ip route add default via 198.51.100.1 dev eth1 table isp2
# трафик с адреса eth0 уходит через isp1, с eth1 - через isp2
ip rule add from 203.0.113.10 table isp1
ip rule add from 198.51.100.10 table isp2
ip rule show # порядок и приоритеты правил
ip route show table isp1
ip route get 8.8.8.8 from 198.51.100.10 # проверка решения ядра
Мост через iproute2 (то же делает nmcli в NetworkManager-средах RHEL/Ubuntu):
Код: Выделить всё
ip link add br0 type bridge
ip link set eth0 master br0
ip link set br0 up
bridge link show # члены моста
bridge fdb show # таблица выученных MAC
# вариант через NetworkManager (RHEL 10 / Ubuntu 24.04)
nmcli con add type bridge ifname br0
nmcli con add type bridge-slave ifname eth0 master br0
Код: Выделить всё
ip link add bond0 type bond mode 802.3ad miimon 100
ip link set eth0 down && ip link set eth0 master bond0
ip link set eth1 down && ip link set eth1 master bond0
ip link set bond0 up
cat /proc/net/bonding/bond0 # состояние, активные слейвы, LACP
Код: Выделить всё
ip tunnel add gre1 mode gre remote 198.51.100.5 local 203.0.113.10 ttl 255
ip addr add 10.10.0.1/30 dev gre1
ip link set gre1 up
Код: Выделить всё
tcpdump -i eth0 -nn 'tcp port 443 and host 8.8.8.8' # -nn без резолва имён и портов
tcpdump -i eth0 -w cap.pcap 'port 53' # запись в файл
tcpdump -r cap.pcap -A 'tcp port 80' # чтение, -A текст
tshark -i eth0 -f "udp port 123" -Y "ntp.flags.mode == 4" # -f захват, -Y отображение
netcat (ncat в RHEL из nmap-ncat, netcat-openbsd в Debian) и socat для отладки сокетов:
Код: Выделить всё
nc -lvnp 9000 # слушатель на порту 9000
nc -vz host 22 # проверка доступности порта, -z сканер
socat -d -d TCP-LISTEN:8443,fork,reuseaddr TCP:backend:443 # TCP-проброс
socat OPENSSL:host:443,verify=0 - # ручной TLS-клиент
Частые грабли
- Ручные ip route и ip rule живут до перезагрузки. Для постоянства нужен NetworkManager (nmcli/keyfile), systemd-networkd или netplan в Ubuntu - голый ip их не сохраняет.
- Несимметричная маршрутизация при двух аплинках: забыли таблицу для исходящего, и rp_filter (/proc/sys/net/ipv4/conf/*/rp_filter) молча режет ответы. Симптом - пакеты приходят, ответы не уходят.
- Порядок ip rule важен: правила проверяются по возрастанию приоритета, первое совпадение выигрывает. Неудачный приоритет - и ваше правило никогда не сработает.
- Bonding mode=4 требует настройки LACP и на коммутаторе. Без согласования получите либо отвал линка, либо петлю. Проверяйте /proc/net/bonding.
- tcpdump без -n тормозит и сам генерит DNS-трафик при резолве - в захвате видите лишний шум. Всегда -nn при отладке.
- Фильтр захвата и фильтр отображения - разный синтаксис. tcp.port в -f не сработает, это синтаксис Wireshark; в BPF пишут tcp port.
- nc -e (выполнить команду) вырезан в большинстве сборок как дыра в безопасности. Для шеллов используйте socat с EXEC.
- На стенде с двумя интерфейсами заведите таблицы isp1 и isp2 в rt_tables, добавьте в каждую default-маршрут.
- Навесьте ip rule from по адресу источника каждого интерфейса и проверьте выбор через ip route get ... from ...
- Создайте мост br0, добавьте в него один интерфейс, посмотрите bridge fdb show после пинга.
- Поднимите bond0 в режиме active-backup (mode=1) из двух интерфейсов, погасите активный слейв и убедитесь по /proc/net/bonding, что трафик перешёл на второй.
- Запустите на одном хосте nc -lvnp 9000, с другого подключитесь nc -vz и nc для передачи строки.
- Снимите tcpdump -i ... -w lab.pcap на этом порту, откройте файл через tshark и примените фильтр отображения tcp.port == 9000.
- В каком порядке ядро проверяет правила ip rule и что определяет приоритет таблиц local, main, default?
- Чем фильтр захвата tcpdump (-f / BPF) принципиально отличается от фильтра отображения Wireshark (-Y) и почему первый экономит ресурсы?
- Какой режим bonding соответствует LACP, что нужно настроить на стороне коммутатора и где смотреть состояние агрегата?
- Зачем при двух провайдерах нужны отдельные таблицы маршрутизации и как с этим связан rp_filter?
- Какие возможности socat недоступны классическому netcat и в каком случае это решает задачу?
- Чем мост (bridge) отличается от обычной маршрутизации и на каком уровне модели OSI он работает?

