
Администратор Linux половину рабочего времени читает текст: логи, конфиги, вывод команд, выгрузки в CSV. Глазами это не осилить, поэтому есть набор маленьких утилит-фильтров, каждая из которых делает ровно одну операцию над потоком строк. По отдельности они примитивны, но соединённые в конвейер превращаются в мощный инструмент разбора данных. В этом уроке разберём классические фильтры из coreutils, научимся собирать их в цепочки и решим типовые задачи: посчитать ошибки в логе, выдрать колонку из таблицы, найти топ IP-адресов.
Как это работает
Фильтр - это программа, которая читает стандартный ввод (stdin), как-то его преобразует и пишет в стандартный вывод (stdout). Если файл не указан аргументом, фильтр берёт данные из stdin, поэтому его можно поставить в середину конвейера. Символ вертикальной черты соединяет stdout одной команды с stdin следующей, и данные текут слева направо, строка за строкой, не дожидаясь конца файла.
Большинство фильтров мыслят строками и полями. Строка - это всё до символа перевода строки. Поле - это кусок строки, отделённый разделителем: по умолчанию у cut это табуляция, у sort, awk и подобных - последовательность пробелов и табуляций. Понимание, что считается разделителем в конкретной утилите, важнее знания всех ключей, потому что именно тут чаще всего ломаются конвейеры.
Ключевая идея Unix-философии: не искать одну гигантскую команду, а собрать решение из нескольких простых. Каждый фильтр в цепочке сужает или переформатирует поток, а итог получается комбинацией. Почти все эти утилиты входят в пакет coreutils и ведут себя одинаково на Debian, Ubuntu, RHEL и Fedora - различий между семействами тут почти нет, в отличие от управления пакетами.
Команды и примеры
Просмотр и склейка. cat выводит файлы подряд, tac - в обратном порядке строк (удобно смотреть лог с конца). nl нумерует строки, причём по умолчанию пропускает пустые.
Код: Выделить всё
cat -A file.txt # показать спецсимволы: $ конец строки, ^I табуляция
tac /var/log/syslog # последние события сверху
nl -ba script.sh # пронумеровать ВСЕ строки, включая пустые
Код: Выделить всё
head -n 20 access.log # первые 20 строк
tail -n 50 access.log # последние 50
tail -f /var/log/nginx/error.log # следить за дописыванием в реальном времени
journalctl -u sshd | tail -n 100 # хвост лога юнита через systemd
Код: Выделить всё
cut -d: -f1,7 /etc/passwd # логин и оболочка
cut -c1-8 /var/log/syslog # первые 8 символов (метка времени)
echo "a b c" | cut -d' ' -f2 # ВНИМАНИЕ: cut не схлопывает пробелы
Код: Выделить всё
sort -k2,2 -k3,3n data.txt # по 2-му полю как текст, затем по 3-му как число
sort -t: -k3 -n /etc/passwd # разделитель двоеточие, числовая сортировка по UID
sort access.log | uniq -d # только строки, которые повторяются
Код: Выделить всё
tr 'a-z' 'A-Z' < name.txt # в верхний регистр
tr -s ' ' # схлопнуть повторяющиеся пробелы в один
tr -d '\r' < dos.txt > unix.txt # убрать CR из файла с CRLF
wc -l access.log # число строк
Код: Выделить всё
paste -d, names.txt ids.txt # склеить две колонки через запятую
join -t: -1 1 -2 1 users.txt mail.txt # объединить по первому полю
split -l 100000 huge.log part_ # куски по 100000 строк
od -An -tx1 file.bin | head # дамп в шестнадцатеричном виде
Код: Выделить всё
grep -i error app.log | grep -v debug # с ошибками, но без debug
grep -c 'HTTP/1.1" 500' access.log # сколько раз встретилось
sed -n '10,20p' file.txt # вывести только строки 10-20
sed 's/ */ /g; s/^ //' messy.txt # схлопнуть пробелы, убрать ведущий
Код: Выделить всё
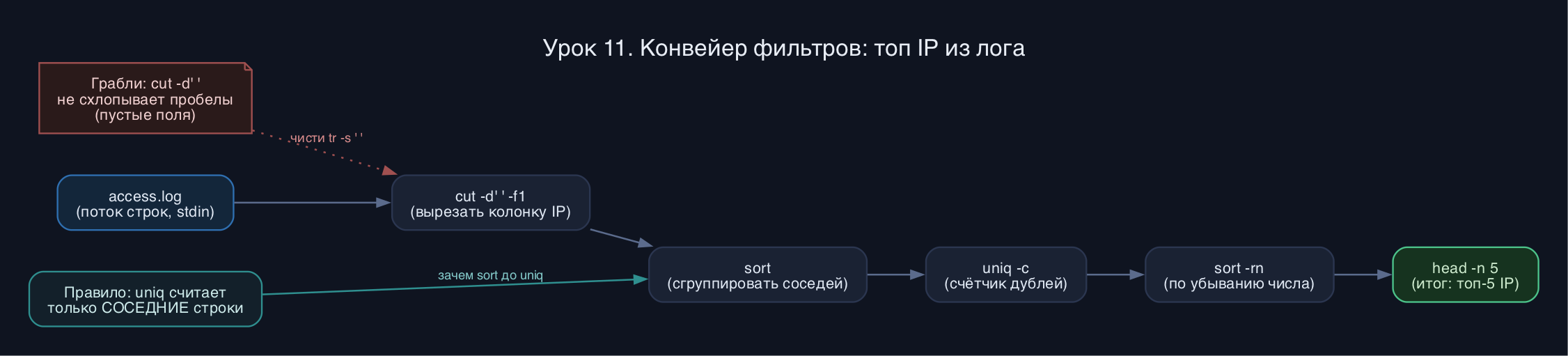
cut -d' ' -f1 access.log | sort | uniq -c | sort -rn | head -n 5
- uniq убирает только СОСЕДНИЕ дубли. Без предварительного sort он пропустит повторы, разбросанные по файлу.
- cut с разделителем-пробелом не схлопывает их: два пробела подряд дадут пустое поле. Для текста с переменными отступами сначала прогоните через tr -s ' ' или используйте awk.
- sort по умолчанию сортирует лексикографически: 10 окажется раньше 2. Для чисел нужен ключ -n, для размеров вида 1K, 2M - ключ -h.
- Локаль ломает порядок: в ru_RU.UTF-8 сортировка может игнорировать регистр и пунктуацию. Для стабильного байтового порядка ставьте LC_ALL=C перед sort.
- tr читает только stdin, файл аргументом не принимает - пишите tr ... < file, иначе получите ошибку или зависание в ожидании ввода.
- head -c и tail -c режут по байтам, а не по символам: на UTF-8 можно разрубить букву пополам.
- Внутри двойных кавычек bash раскрывает переменные и подстановки, поэтому регулярки для sed и grep почти всегда берут в ОДИНАРНЫЕ кавычки.
- Скопируйте свежий лог веб-сервера или возьмите journalctl -u ssh --no-pager > ssh.log.
- Командой wc -l посчитайте общее число строк в файле.
- Через grep -c найдите, сколько строк содержат слово Failed или error.
- Постройте конвейер cut | sort | uniq -c | sort -rn и выведите топ-10 повторяющихся источников (IP или имя юнита).
- Командой cut выдерните из /etc/passwd логины пользователей с UID >= 1000: подсказка - sort -t: -k3 -n и затем awk или фильтрация.
- Сделайте из двух файлов (логины и e-mail) одну таблицу через paste и через join, сравните результат.
- Возьмите файл с CRLF (или создайте printf 'a\r\nb\r\n') и почистите его через tr -d, проверьте результат командой od -c.
- Почему uniq без sort часто не находит все дубликаты и как это исправить?
- Чем отличается вывод sort без ключей от sort -n на строках 2, 10, 1?
- Как командой cut выбрать второе и седьмое поля из файла /etc/passwd?
- Какой фильтр и с какими ключами схлопнет повторяющиеся пробелы в один?
- В чём разница между paste и join при объединении двух файлов?
- Как одной цепочкой фильтров получить пять самых частых значений первого столбца лога?

