
Создать раздел и записать на него mkfs - это полдела. Дальше начинается жизнь: ФС обрастает данными, диск стареет, иногда внезапно гаснет питание, и однажды система просит проверку. Этот урок про то, как смотреть внутрь файловой системы, чинить её после сбоев, тюнинговать поведение и заранее ловить умирающий диск. Разберём три семейства - ext2/3/4, XFS и Btrfs - и сквозную тему здоровья накопителя через SMART. К концу вы будете понимать, какой инструмент к какой ФС подходит и почему нельзя путать.
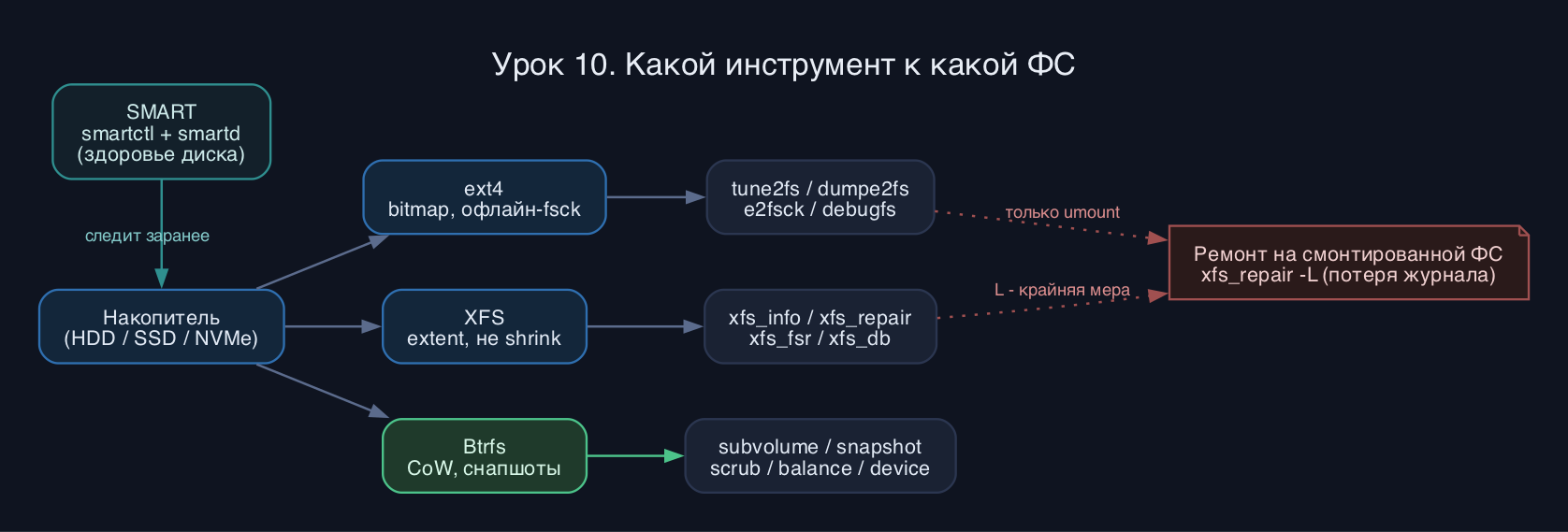
Как это работает
Любая журналируемая ФС хранит метаданные (суперблок, таблицу инодов, дескрипторы групп, битмапы свободных блоков) отдельно от ваших файлов. Когда система падает на середине записи, метаданные и реальное содержимое могут разойтись. Журнал (journal) - это запись намерений: ФС сперва пишет в журнал, что собирается сделать, потом делает. После сбоя достаточно проиграть журнал, а не сканировать весь диск. Поэтому fsck при чистом журнале отрабатывает за секунды.
Ext4 - классическая bitmap-based ФС: всё описано заранее выделенными структурами фиксированного размера. Её утилиты (семейство e2fsprogs) работают по этим структурам напрямую. XFS - extent-based, спроектирована под параллельный ввод-вывод и огромные тома, у неё свои инструменты с префиксом xfs_. Btrfs - copy-on-write: при записи новый блок пишется в новое место, а старый остаётся, пока на него кто-то ссылается. Именно CoW даёт почти бесплатные снапшоты, подтома и контрольные суммы на каждый блок, но требует периодического обслуживания (scrub, balance).
Важнейшее различие на практике: ext4 проверяют и чинят в офлайне (размонтированной), XFS проверяет журнал при монтировании, а xfs_repair тоже требует размонтирования. XFS нельзя ужать (shrink), только расширить. Btrfs живёт по своим правилам и многое делает онлайн, на смонтированной ФС.
SMART - это телеметрия внутри самого накопителя. Контроллер диска ведёт счётчики: переназначенные сектора, ошибки чтения, температура, для SSD - износ ячеек и записанные терабайты. smartctl читает эти счётчики, а демон smartd следит за ними в фоне и шлёт алерт до того, как диск отвалится.
Команды и примеры
Установка инструментов. Debian 13 / Ubuntu 24.04:
Код: Выделить всё
apt install e2fsprogs xfsprogs btrfs-progs smartmontoolsКод: Выделить всё
dnf install e2fsprogs xfsprogs btrfs-progs smartmontoolsКод: Выделить всё
dumpe2fs /dev/sda1 | less # весь дамп метаданных
dumpe2fs -h /dev/sda1 # только заголовок суперблока
tune2fs -l /dev/sda1 # компактный список параметров
tune2fs -L data /dev/sda1 # задать метку тома
tune2fs -m 1 /dev/sda1 # резерв для root снизить с 5% до 1%
tune2fs -c 30 -i 0 /dev/sda1 # проверка каждые 30 монтированийКод: Выделить всё
umount /dev/sda1
e2fsck -p /dev/sda1 # автоматически чинить безопасное
e2fsck -f /dev/sda1 # форсировать, даже если "clean"
e2fsck -y -b 32768 /dev/sda1 # чинить от резервной копии суперблокаКод: Выделить всё
debugfs -R "stat <12>" /dev/sda1 # инфо по иноду номер 12
debugfs -R "ncheck 12" /dev/sda1 # какой путь у этого инода
debugfs -w -R "rm /tmp/lock" /dev/sda1Код: Выделить всё
xfs_info /mnt/data # геометрия: blocksize, agcount, sunit/swidth
xfs_repair -n /dev/sdb1 # dry-run, только показать проблемы
umount /dev/sdb1
xfs_repair /dev/sdb1 # реальный ремонт (ФС размонтирована)
xfs_repair -L /dev/sdb1 # ОБНУЛИТЬ битый журнал - крайняя мераКод: Выделить всё
xfs_fsr /dev/sdb1 # реорганизация экстентов смонтированной ФС
xfs_db -r /dev/sdb1 # read-only форензика суперблокаКод: Выделить всё
btrfs subvolume create /mnt/pool/@data
btrfs subvolume list /mnt/pool
btrfs subvolume snapshot -r /mnt/pool/@data /mnt/pool/.snap/data-2026-06-14Код: Выделить всё
btrfs scrub start -B /mnt/pool # вычитать всё, сверить чек-суммы
btrfs scrub status /mnt/pool
btrfs balance start -dusage=50 /mnt/pool # уплотнить полупустые чанки
btrfs device add /dev/sdc /mnt/pool # добавить диск в пул
btrfs filesystem usage /mnt/pool # реальная занятость (не df!)Код: Выделить всё
smartctl -i /dev/sda # модель, поддержка SMART
smartctl -H /dev/sda # вердикт PASSED / FAILED
smartctl -A /dev/nvme0 # атрибуты: Reallocated, Wear_Leveling
smartctl -t short /dev/sda # запустить короткий самотест
smartctl -l selftest /dev/sda # журнал самотестовКод: Выделить всё
DEVICESCAN -a -o on -S on -s (S/../.././02|L/../../6/03) -m root@localhostКод: Выделить всё
systemctl enable --now smartd- Запуск e2fsck или xfs_repair на СМОНТИРОВАННОЙ ФС - почти гарантированное разрушение. Сначала umount.
- xfs_repair -L затирает журнал и теряет незаписанные транзакции. Использовать только когда mount уже не поднимает журнал.
- Попытка ужать XFS: её нельзя shrink в принципе. Планируйте размер заранее или используйте LVM.
- df на Btrfs врёт про свободное место из-за CoW и метаданных. Реальную картину даёт btrfs filesystem usage.
- Снапшот Btrfs НЕ занимает место сразу, но удерживает старые блоки. Забытые снапшоты тихо съедают пул - чистите их.
- Отсутствие balance: со временем чанки фрагментируются и Btrfs выдаёт ENOSPC при формально свободном месте.
- Чтение SMART через RAID-контроллер без -d (megaraid/cciss) вернёт мусор или ошибку.
- Атрибут SMART прошёл PASSED, но растущий Reallocated_Sector_Ct - уже повод менять диск, не дожидаясь FAILED.
- Создайте петлевой файл и сделайте на нём ext4: dd if=/dev/zero of=/tmp/img bs=1M count=512, затем mkfs.ext4 /tmp/img.
- Посмотрите суперблок: dumpe2fs -h /tmp/img. Задайте метку tune2fs -L lab /tmp/img и убедитесь, что метка применилась.
- Размонтируйте (если монтировали) и прогоните e2fsck -f /tmp/img, прочитайте 5 фаз проверки.
- Создайте второй образ под XFS, смонтируйте, посмотрите xfs_info, затем размонтируйте и сделайте xfs_repair -n.
- Сделайте Btrfs-образ, создайте подтом, сделайте read-only снапшот, запустите btrfs scrub start -B и прочитайте статус.
- Выполните smartctl -i и smartctl -A на вашем реальном системном диске, найдите температуру и Power_On_Hours.
- Запустите smartctl -t short, подождите и посмотрите результат через smartctl -l selftest.
- Чем принципиально отличается выделение блоков в ext4 (bitmap) от XFS (extent) и как это влияет на крупные файлы?
- Почему e2fsck нельзя запускать на смонтированной ФС, а xfs_repair можно вызвать с -n даже теоретически "на горячую"?
- Что делает xfs_repair -L и какой риск с этим связан?
- Зачем Btrfs нужны периодические scrub и balance, что именно каждая из команд решает?
- Какие два-три атрибута SMART сигналят о деградации HDD, и какой - об износе SSD?
- Почему df показывает некорректное свободное место на Btrfs и чем его заменить?

