
В прошлых уроках мы балансировали нагрузку. Здесь задача другая: обеспечить, чтобы сервис (виртуальный IP, база, файловая шара) пережил падение целого узла и автоматически переехал на живой. Это классический failover-кластер. В Linux его собирают из двух слоёв: Corosync отвечает за то, кто в кластере жив и есть ли кворум, а Pacemaker (cluster resource manager) решает, где и в каком порядке запускать ресурсы. В этом уроке разберём членство, кворум и транспорт Corosync, устройство конфигурации Pacemaker (CIB), инструменты pcs и crm, типы агентов ресурсов и соберём рабочий двухузловой кластер.
Как это работает
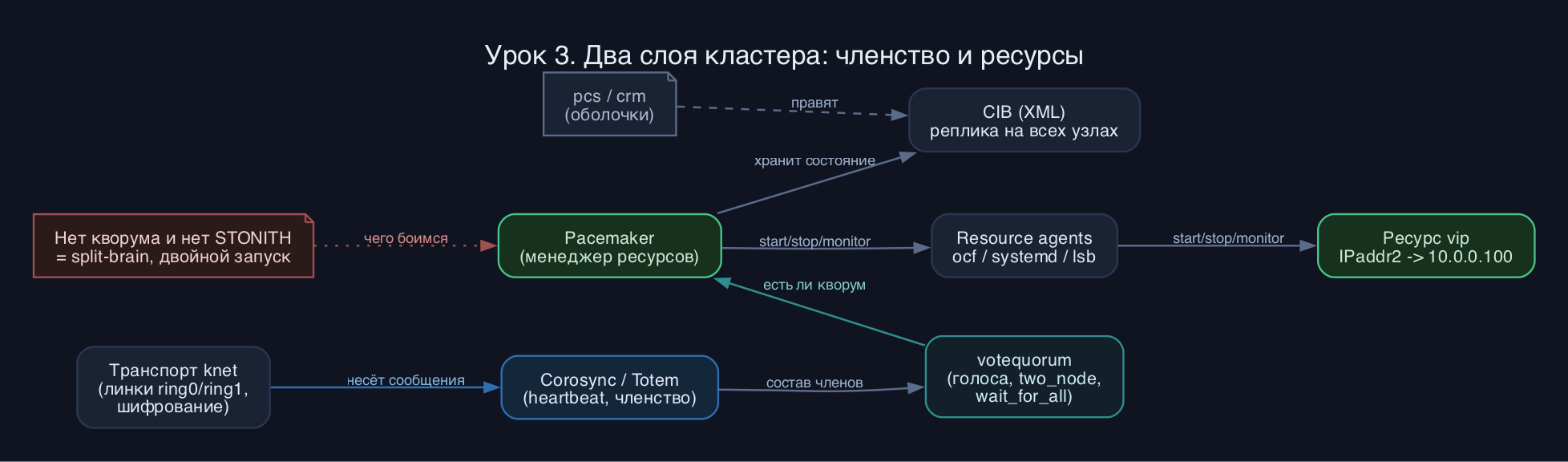
Corosync - это движок обмена сообщениями. Его сердце - протокол Totem: узлы постоянно шлют друг другу heartbeat и согласуют единый список членов. Когда состав меняется (узел упал или вернулся), Totem формирует новую конфигурацию членства и сообщает её всем. На этом строится votequorum - подсистема, считающая голоса. По умолчанию каждый узел даёт один голос, и кластер считается кворумным, если живых голосов больше половины. Без кворума Pacemaker по умолчанию останавливает ресурсы, чтобы две половины не запустили один и тот же сервис дважды (split-brain).
Транспорт в Corosync 3 - это knet (kronosnet). Он пришёл на смену старому udpu/multicast и умеет несколько физических линков сразу с автоматическим переключением, а также шифрует и сжимает трафик из коробки. Каждый узел описывается одним или несколькими адресами (ring0_addr, ring1_addr) - это и есть резервирование сети на уровне кластера.
Pacemaker поверх этого хранит всё состояние в CIB (Cluster Information Base) - это XML-дерево, реплицируемое на все узлы. В CIB лежат описания узлов, ресурсов, ограничений (constraints) и текущий статус. Вручную XML не правят: есть высокоуровневые оболочки. В мире RHEL это pcs, в мире SUSE и Debian исторически популярен crmsh (команда crm). Обе делают одно и то же - транслируют человеческие команды в правки CIB.
Ресурсом управляет resource agent - скрипт со стандартным интерфейсом start/stop/monitor. Основные классы: ocf (самые гибкие, с параметрами и проверками здоровья, например ocf
 IPaddr2 для виртуального IP), systemd (обёртка над юнитом, например systemd:nginx) и устаревший lsb (init-скрипты, в 2026 практически не нужен). Отдельный важный механизм - fencing/STONITH: способность кластера принудительно выключить зависший узел через IPMI или PDU. Без рабочего STONITH в проде кластер не считается надёжным.
IPaddr2 для виртуального IP), systemd (обёртка над юнитом, например systemd:nginx) и устаревший lsb (init-скрипты, в 2026 практически не нужен). Отдельный важный механизм - fencing/STONITH: способность кластера принудительно выключить зависший узел через IPMI или PDU. Без рабочего STONITH в проде кластер не считается надёжным.Команды и примеры
Установка пакетов. Debian 13 / Ubuntu 24.04:
Код: Выделить всё
apt update
apt install -y pacemaker corosync pcs fence-agents-base resource-agents-base
Код: Выделить всё
dnf install -y pacemaker corosync pcs fence-agents-all resource-agents
Код: Выделить всё
passwd hacluster
systemctl enable --now pcsd
# с одного узла:
pcs host auth node1 node2 -u hacluster -p ВашПароль
Код: Выделить всё
pcs cluster setup hacluster1 node1 addr=10.0.0.11 node2 addr=10.0.0.12
pcs cluster start --all
pcs cluster enable --all
Код: Выделить всё
quorum {
provider: corosync_votequorum
two_node: 1
}
Код: Выделить всё
pcs property set stonith-enabled=false
Код: Выделить всё
pcs resource create vip ocf:heartbeat:IPaddr2 ip=10.0.0.100 cidr_netmask=24 op monitor interval=10s
pcs status
Код: Выделить всё
crm configure primitive vip ocf:heartbeat:IPaddr2 params ip=10.0.0.100 cidr_netmask=24 op monitor interval=10s
Код: Выделить всё
corosync-quorumtool -s # сводка: голоса, кворум, флаги (2Node, WaitForAll)
corosync-cfgtool -s # состояние линков knet, статус ring
pcs status corosync # то же глазами pcs
Код: Выделить всё
journalctl -u pacemaker -u corosync -f
tail -f /var/log/pacemaker/pacemaker.log
Код: Выделить всё
pcs resource list ocf:heartbeat
pcs resource list systemd
- Забыли STONITH. В проде stonith-enabled=false - это бомба: при сетевом разрыве оба узла поднимут vip и базу, данные разъедутся. Отключение допустимо только в учебном стенде.
- Файрвол режет Corosync. knet ходит по UDP-портам около 5404-5405, pcsd слушает TCP 2224. Нужны правила: на RHEL firewall-cmd --add-service=high-availability, на Debian - открыть порты в nftables. iptables - это легаси, в 2026 пишите nftables.
- Время не синхронизировано. Расхождение часов между узлами ломает таймстампы в логах и сбивает таймауты Totem. Поднимайте chrony до сборки кластера.
- Путаница two_node и wait_for_all. После полного выключения обоих узлов кластер намеренно ждёт второго и не стартует - это не баг. Снять можно pcs quorum unblock, понимая риски.
- Правка corosync.conf на одном узле. Файл должен быть идентичен везде; меняйте через pcs или вручную, но потом pcs cluster sync и pcs cluster reload corosync.
- Ресурс как systemd-юнит и одновременно enable у systemd. Если юнит включён в systemd напрямую, он стартует мимо кластера. Сервисами, отданными в Pacemaker, управляет только кластер: systemctl disable их на уровне ОС.
- Поднимите две ВМ (node1, node2) в одной сети, синхронизируйте время через chrony, пропишите имена в /etc/hosts.
- Установите пакеты pacemaker corosync pcs, задайте пароль hacluster, включите pcsd на обоих.
- Выполните pcs host auth, затем pcs cluster setup и pcs cluster start --all. Убедитесь в кворуме через corosync-quorumtool -s (ищите флаги 2Node и WaitForAll).
- Отключите stonith-enabled и создайте ресурс vip (IPaddr2) на адрес из вашей подсети. Проверьте pcs status - запомните, на каком узле он висит.
- Пингуйте 10.0.0.100 с третьей машины непрерывно. Введите pcs node standby на узле с vip и смотрите, как IP переезжает; потерь пинга почти нет.
- Верните узел: pcs node unstandby. Сделайте жёстче - pcs cluster stop на активном узле и наблюдайте failover по journalctl -f.
- Изучите CIB: pcs cluster cib выведет XML; найдите там описание ресурса vip и блок nodes.
- За что отвечает Corosync, а за что Pacemaker, и где проходит граница между ними?
- Что делают параметры two_node и wait_for_all и почему их обычно включают вместе в двухузловом кластере?
- Чем класс агента ocf отличается от systemd и lsb, и когда какой выбирать?
- Что такое CIB, в каком формате он хранится и почему его не редактируют вручную?
- Какими командами проверить членство, кворум и состояние линков knet, не используя Pacemaker?
- Почему STONITH критичен для целостности данных и что произойдёт при его отсутствии во время split-brain?

