
Это финал курса. Мы не вводим новых сущностей - мы собираем все ранее пройденное в одну работающую картину: как vshard режет данные на шарды, как репликация держит каждый шард живым, как etcd раздает единую конфигурацию всем узлам, и как мониторинг показывает, что система здорова. Цель - чтобы вы держали в голове путь запроса от клиента до конкретного tuple и понимали, какой компонент отвечает за каждую гарантию.
Промышленный кластер Tarantool 3.x - это не один процесс, а четыре слоя, которые работают вместе:
- слой шардирования (vshard): router-ы и storage-узлы, разбиение данных по бакетам;
- слой репликации: внутри каждого шарда - replica set с одним master и репликами;
- слой конфигурации: etcd (или Tarantool-based config.storage) как единый источник топологии;
- слой наблюдаемости: metrics + экспортер, алерты по лагу репликации и состоянию бакетов.
Слой 1. Шардирование (vshard). Весь датасет логически делится на фиксированное число виртуальных бакетов (bucket_count, например 30000). bucket_count - стратегический параметр: его задают на bootstrap и изменить потом нельзя. Правило - на 2-3 порядка больше, чем планируемое число узлов (100*M ... 1000*M), иначе пострадает гранулярность ребаланса.
Каждый tuple шардируемого спейса хранит свой bucket_id в отдельном поле. На стороне storage системный спейс _bucket хранит, какие бакеты сейчас лежат на этом шарде и в каком статусе. router держит routing table - карту bucket_id -> replica set - и не имеет персистентного состояния: он строит ее в рантайме. Специальный discovery fiber на router-е периодически обходит storage-узлы и обновляет карту, поэтому переезд бакета или смена master прозрачны для приложения.
Запрос всегда идет через router, и единственная операция router - call:
Код: Выделить всё
result = vshard.router.call(bucket_id, mode, func_name, {args}, {opts})
-- mode: 'read' (можно с реплики) или 'write' (только master)
Слой 2. Репликация внутри шарда. Шард = replica set. Реплика тянет WAL master-а и применяет его: репликация row-based, каждая запись WAL - детерминированная DML-операция с растущим LSN. Вызовы хранимок в WAL не пишутся - пишутся их фактические изменения данных, чтобы недетерминизм Lua не рассинхронил реплики. Рекомендованная топология - full mesh (не каскад: на реплике реплики узел может не узнать чужой replica set UUID и получить отказ в подключении). Предел - 32 реплики в mesh.
Слой 3. Отказоустойчивость. В replication.failover есть режимы. Самый автономный - election: Tarantool сам выбирает лидера через модификацию Raft. Жизнь сета делится на термы (монотонно растущий номер); узел без лидера повышает терм и начинает голосование. Кто собрал кворум replication.synchro_quorum (для строгого Raft - N/2+1), тот лидер и шлет heartbeat-ы. Если heartbeat-ов нет в течение replication.timeout*4, начинаются перевыборы. Чтобы старый лидер при потере связи не остался writable и не возник split-brain, есть fencing (election_fencing_mode: soft по умолчанию, strict жестче). Альтернатива выборам - supervised failover с внешним координатором, который как stateboard использует etcd/config.storage.
Слой 4. Единая конфигурация (etcd). В 3.x вся топология - декларативный YAML. Чтобы не раскладывать идентичный файл руками на каждый узел, его кладут в централизованное хранилище (etcd или Tarantool config.storage, доступно в Enterprise Edition). Все инстансы при старте тянут конфиг по пути prefix/config/*. etcd параллельно может работать stateboard-ом для supervised failover - то есть один внешний слой и про топологию, и про выбор мастера.
Слой 5. Мониторинг. Встроенный модуль metrics отдает счетчики и собирает специфику vshard/репликации. Ключевые сигналы: box.info.replication[n].upstream.status и lag (отставание реплики), состояние бакетов и наличие застрявших в SENDING/RECEIVING, дисбаланс replica set. Экспортер отдает это в Prometheus, поверх - алерты.
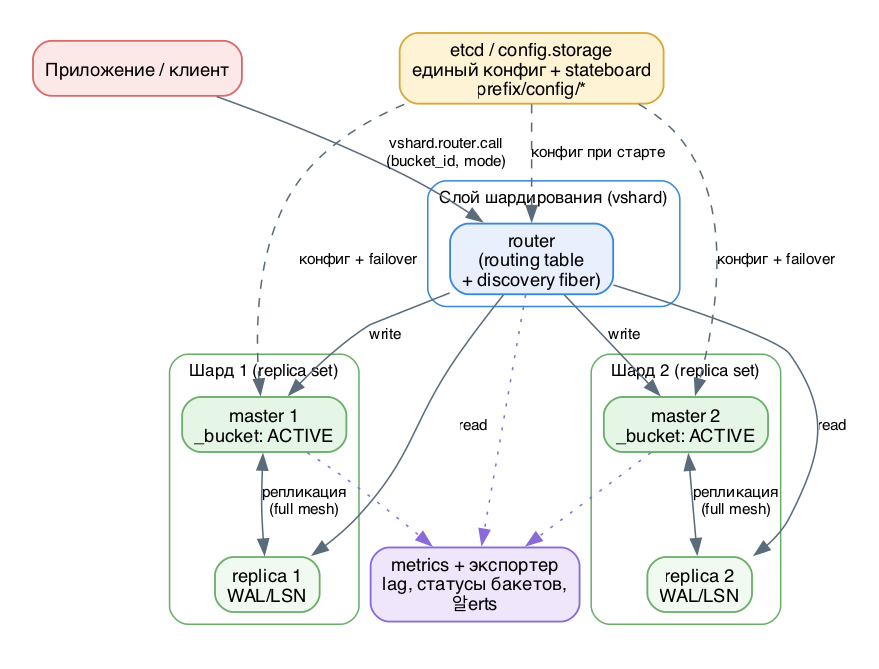
Сквозная архитектура: vshard, репликация, etcd, мониторинг
Ключевой код и команды
Декларативный 3.x: подключение узла к конфигу в etcd (фрагмент локального config.yaml):
Код: Выделить всё
config:
etcd:
endpoints:
- http://192.168.0.10:2379
- http://192.168.0.11:2379
prefix: /myapp
username: tarantool
password: secret
http:
request:
timeout: 3
Код: Выделить всё
$ etcdctl put /myapp/config/all < cluster.yaml
Код: Выделить всё
box.cfg{
listen = 3301,
replication = {'replicator@host1:3301','replicator@host2:3301','replicator@host3:3301'},
election_mode = 'candidate', -- участвовать в выборах
replication_synchro_quorum = 2, -- N/2+1 для N=3
read_only = false,
}
Код: Выделить всё
box.info.replication -- статус и lag всех upstream/downstream
box.info.election -- term, state (leader/follower/candidate), vote
vshard.storage.info() -- статус бакетов, алерты этого шарда
vshard.router.info() -- доступность шардов, известные бакеты
vshard.router.bucket_count() -- всего бакетов
Код: Выделить всё
disbalance = |etalon_buckets - real_buckets| / etalon_buckets * 100
если > порога конфигурации -> запускается миграция бакетов
bucket_count можно подкрутить позже. Нет. Он фиксируется на bootstrap. Заложите запас сразу: слишком мало - грубый ребаланс, слишком много - лишняя память под routing table.
- router на storage-узле. Технически можно, в проде - нет. Разносите router и storage по разным инстансам, иначе одна перегрузка валит оба слоя.
- Меньше трех реплик в шарде. Для election и для переживания отказа нужен кворум. Два узла дают failover, но не дают надежного кворума при сетевых разрывах - норма для прода 3+.
- Каскадная репликация. Реплика реплики не узнает UUID всех узлов через _cluster и при смене топологии получит отказ. Только full mesh (или временно ring, потом разрыв).
- Master-master с некоммутативными операциями. Асинхронный мультимастер безопасен только если изменения коммутативны. UPDATE-ы (присваивание, инкремент) легко уводят реплики в рассинхрон.
- Забыли про fencing. Без него потерявший связь лидер может остаться writable - привет split-brain. Для важных данных - strict.
- Разные конфиги на узлах. При ручной раскладке файлы расходятся. Единый источник (etcd) этого не допускает - в этом его смысл.
- Мониторят только CPU. Главный ранний сигнал - lag репликации и бакеты, застрявшие в SENDING/RECEIVING. Алертьте именно их.
Поднимите на одной машине кластер из двух шардов (по 2 инстанса) + 1 router, любым знакомым способом (tt + локальный config.yaml). Затем на router-е выполните vshard.router.info() и vshard.router.bucket_count(), а на одном из storage - vshard.storage.info() и box.info.replication. Задание: найдите в выводе, как бакеты распределились между двумя шардами, и кто из двух инстансов каждого шарда является master (read_only = false). Остановите master одного шарда и посмотрите через box.info.election, как роль leader переходит на реплику.
Контрольные вопросы
- Почему bucket_count выбирают сильно больше числа узлов и почему его нельзя менять после bootstrap?
- Что именно делает discovery fiber на router-е и почему благодаря ему failover и переезд бакета прозрачны для приложения?
- Какую роль играет etcd одновременно для конфигурации и для supervised failover?
- Что такое fencing в выборах лидера и от какой проблемы он защищает?