
memtx держит 100% данных в RAM. vinyl - дисковый движок для случаев, когда данных больше, чем памяти, и докупить память нереально. Внутри vinyl лежит не B-дерево, а LSM-дерево (log-structured merge tree). Ключевая идея: на запись B-дерево читает и переписывает целый блок (4 Кб) ради изменения 100 байт - это write amplification в десятки раз. LSM же не переписывает данные на месте, а только дописывает в конец файлов (append-only), что резко снижает запись на SSD.
Главное отличие LSM от B-дерева: оно хранит не значения, а операции - REPLACE, DELETE, UPSERT. У каждой операции есть LSN (монотонно растущий номер). Внутри одного дерева всё упорядочено сначала по ключу (по возрастанию), затем в рамках ключа по LSN (по убыванию) - то есть самая свежая версия ключа лежит первой.
Механика: уровни, дамп, компакция
L0 и дамп. Свежие операции пишутся в L0 - часть дерева в RAM (в Tarantool это B+*-дерево). Размер L0 ограничен параметром vinyl_memory. Когда L0 переполняется, он целиком сбрасывается в файл на диске - это дамп (dump), а сам файл называется run (сортированный пробег). После дампа L0 очищается под новые операции. Дамп идёт из теневой ("shadow") копии L0, поэтому новые вставки и чтения не блокируются.
Пирамида уровней. Раны на диске образуют последовательность по LSN: диапазоны LSN в разных ранах не пересекаются, более свежие раны - ближе к вершине пирамиды. Раны примерно одного размера образуют уровень (L1, L2, ...). Соотношение размеров ранов соседних уровней задаёт vinyl_run_size_ratio (по умолчанию ~3.5), а максимум ранов на уровне - vinyl_run_count_per_level (по умолчанию 2).
Компакция. Когда на уровне накапливается больше ранов, чем разрешено, несколько соседних ранов сливаются в один новый - это компакция (она же merge/purge/сборка мусора). При слиянии для одного ключа остаётся только версия с наибольшим LSN; если за вставкой шло удаление - обе операции выбрасываются. Компакция всегда идёт в отдельном потоке, независимо от дампов - это возможно благодаря append-only природе (старые раны после дампа не меняются, компакция лишь создаёт новые).
Tombstone (надгробие). Из append-only файла нельзя "удалить" запись, поэтому DELETE вставляет в L0 маркер-надгробие. Оно проходит сквозь промежуточные уровни и физически удаляется только при major-компакции, затрагивающей самый нижний уровень.
Ranges и slices. Один индекс - это не одно LSM-дерево, а набор поддеревьев - ranges (диапазонов), размер каждого регулирует vinyl_range_size. При переполнении range делается split (разрезается по среднему ключу), при усыхании соседей - coalesce (слияние). Split и coalesce не создают новых ранов: вводится сущность slice - ссылка на часть рана с диапазоном ключей. Всё это пишется в метаданный лог .vylog (формат совместим с .xlog), что делает truncate и drop мгновенными - реально файлы чистит фоновый GC.
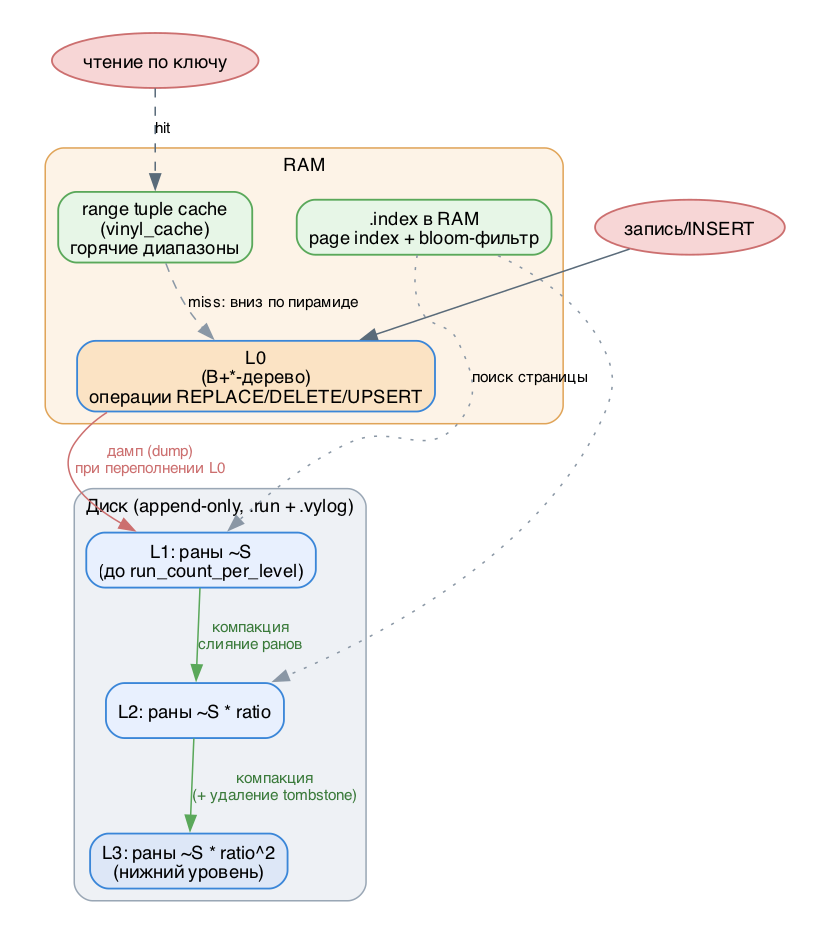
Путь данных vinyl: L0, дамп, компакция, кэш
Чтение, page index, bloom-фильтры, кэш
При точечном поиске нужна самая свежая операция по ключу: идём с вершины пирамиды вниз и останавливаемся на первом совпадении (если это DELETE - значит ключа нет). В худшем случае (ключа нет) приходится просмотреть все уровни - это и есть высокий read amplification у LSM.
Page index. При дампе/компакции данные рана режутся на страницы размером vinyl_page_size, каждая сжимается через zstd. Первый ключ и смещение каждой страницы пишутся в .index-файл. Все .index целиком кэшируются в RAM, поэтому нужная страница в .run находится за одно обращение к диску.
Bloom-фильтр. Чтобы не сканировать уровни ради отсутствующих ключей (типичный случай - проверка уникальности при вставке, "паразитные" чтения), к каждому рану строится bloom-фильтр. Если хоть один бит на позициях ключа равен 0 - ключа в ране точно нет. Вероятность ложного срабатывания задаёт vinyl_bloom_fpr (по умолчанию 0.05 = 5%). Фильтры лежат в .index и кэшируются.
Range tuple cache. У vinyl уникальный кэш: он хранит не страницы (как RocksDB/MySQL), а диапазоны значений индекса, уже слитые по всем уровням. Поэтому кэш работает и для точечных, и для range-запросов, и в RAM попадают только горячие кортежи. Размер - vinyl_cache.
Команды и тюнинг (двойной трек)
Классический box.cfg (1.x/2.x/3.x).
Код: Выделить всё
box.cfg{
vinyl_memory = 1024*1024*1024, -- размер L0 (квота на запись)
vinyl_cache = 256*1024*1024, -- range tuple cache
vinyl_run_count_per_level = 2, -- ранов на уровне до компакции
vinyl_run_size_ratio = 3.5, -- форма пирамиды
vinyl_range_size = nil, -- авто; иначе размер range
vinyl_page_size = 8*1024,
vinyl_bloom_fpr = 0.05,
vinyl_read_threads = 1,
vinyl_write_threads = 4, -- дампы + компакции
vinyl_timeout = 60,
}
Код: Выделить всё
groups:
group-001:
replicasets:
replicaset-001:
instances:
instance-001:
vinyl:
memory: 1073741824
cache: 268435456
run_count_per_level: 2
run_size_ratio: 3.5
bloom_fpr: 0.05
read_threads: 1
write_threads: 4
timeout: 60
Код: Выделить всё
s = box.schema.space.create('t', {engine='vinyl'})
s:create_index('pk', {parts={1,'unsigned'},
page_size=8192, run_count_per_level=2, bloom_fpr=0.01})
-- посмотреть статистику движка:
box.stat.vinyl() -- regulator, scheduler, memory, disk
-- per-index: дампы, компакции, размер
s.index.pk:stat()
-- принудительная major-компакция индекса (с 2.8+):
s.index.pk:compact()
Частые заблуждения и грабли
- "Изменил bloom_fpr/page_size через index:alter() - сразу применилось". Нет: новые опции действуют только в НОВЫХ файлах. Старые раны перестроятся лишь при компакции - возможно, придётся вызвать index:compact().
- "Больше кэша - быстрее любой запрос". В vinyl кэш снижает общую нагрузку, а не магически ускоряет всё. Промахи всё равно идут на диск; цель - стабильное время ответа.
- "UPSERT всегда дешёвый". Он откладывает выполнение до компакции. Если по ключу накопились тысячи upsert без дампа (L0 не переполнился) - чтение проигрывает всю историю. Спасает фоновое squash-сжатие upsert, но не злоупотребляйте upsert на горячих ключах.
- "len() вернёт точное число кортежей". У vinyl len() и count() приблизительны/переменны по времени, delete() всегда возвращает nil, а select может yield-ить. Это следствие LSM-структуры.
- "Компакция не успевает = просто медленно". Если compaction_queue растёт, Tarantool троттлит запись (rate_limit), и при всплесках возможны таймауты (vinyl_timeout). Лечится числом vinyl_write_threads и формой пирамиды.
- Маленький run_size_ratio = высокая пирамида = больше уровней = выше read amplification, но меньше работы на компакцию. Большой ratio - наоборот. Tune под профиль нагрузки (read- vs write-heavy).
Мини-лабаПравило большой пирамиды: write amplification растёт примерно как log по основанию x от (N/L0), умноженный на x, где x = run_size_ratio. Read amplification пропорционален числу уровней. Один параметр одновременно оба не улучшит - выбирайте сторону.
Создайте vinyl-space, залейте данные так, чтобы прошёл хотя бы один дамп, и понаблюдайте за компакцией.
Код: Выделить всё
box.cfg{vinyl_memory=64*1024*1024}
s = box.schema.space.create('lab', {engine='vinyl'})
s:create_index('pk', {parts={1,'unsigned'}})
for i=1,200000 do s:replace{i, string.rep('x',512)} end
-- посмотрите дампы и раны:
require('json').encode(s.index.pk:stat().disk)
box.stat.vinyl().scheduler -- dump_count, tasks_*
s.index.pk:compact() -- форсируем major-компакцию
box.stat.vinyl().scheduler.compaction_queue -- проследите, как опустеет
Контрольные вопросы
- Чем дамп отличается от компакции и почему компакция может идти параллельно с дампом?
- Что физически происходит при DELETE в vinyl и когда tombstone действительно исчезает?
- Как vinyl_run_size_ratio влияет на форму пирамиды, write- и read-amplification?
- Зачем нужны bloom-фильтр и page index, и почему range tuple cache эффективнее кэша страниц для range-запросов?