
В прошлом уроке мы собрали базовый массив. Теперь задача администратора другая: держать массив живым годами под реальной нагрузкой. Сюда входит выбор уровня под профиль чтения и записи, замена сдохшего диска без остановки сервиса, горячий резерв, расширение массива на ходу, связка с LVM и, главное, чтобы вы узнали о деградации раньше, чем пользователи. Разберём mdadm на экспертном уровне: что происходит внутри, какие ключи важны и где можно потерять данные одной неосторожной командой.
Как это работает
RAID на mdadm - это программный слой между блочными устройствами и файловой системой. Ядро (модуль md) держит суперблок метаданных (версия 1.2, по умолчанию в 4 КБ от начала каждого члена) и из них при загрузке собирает массив. Выбор уровня - это всегда компромисс между ёмкостью, отказоустойчивостью и скоростью. RAID10 (не путать с вложенным 1+0 вручную) даёт лучшую случайную запись и переживает потерю нескольких дисков из разных зеркал, но платит половиной ёмкости. RAID5 хорош на чтение и экономен по дискам, но любая запись - это read-modify-write по чётности, отсюда write penalty и риск в окне ребилда на больших дисках. RAID6 держит двойную чётность и потому стал стандартом для массивов из крупных HDD, где ребилд идёт сутками.
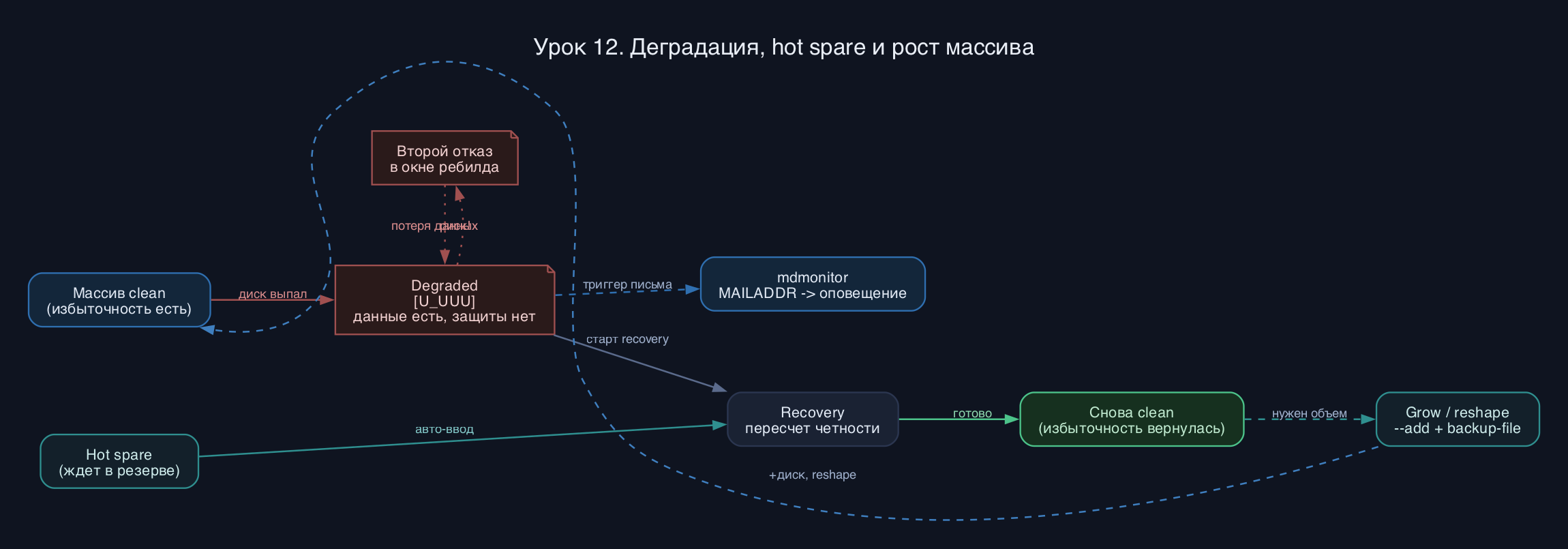
Деградация - это состояние, когда массив потерял избыточность, но ещё отдаёт данные. Тут вступает hot spare: заранее добавленный диск в статусе spare, который md автоматически вводит в строй при выпадении члена и запускает recovery. Чётность пересчитывается на лету, и пока идёт ребилд, массив уязвим - вторая поломка убьёт RAID5. Поэтому скорость ребилда - это не косметика, а время вашего риска.
Рост массива (grow) бывает двух видов. Первый - добавить диски и увеличить число активных устройств с reshape: md переписывает раскладку страйпов по всему массиву, операция долгая и пишет состояние в critical section, чтобы пережить перезагрузку. Второй - заменить все диски на более крупные по очереди, дождаться ребилда каждого, а потом раздвинуть размер. После любого роста надо ещё расширить то, что лежит сверху - LVM PV или файловую систему.
Команды и примеры
Установка отличается по семействам. Debian 13 / Ubuntu 24.04:
Код: Выделить всё
apt install mdadmКод: Выделить всё
dnf install mdadmКод: Выделить всё
mdadm --create /dev/md0 --level=6 --raid-devices=5 \
/dev/sd[b-f] --spare-devices=1 /dev/sdg
mdadm --detail /dev/md0Код: Выделить всё
cat /proc/mdstatКод: Выделить всё
mdadm --manage /dev/md0 --fail /dev/sdc
mdadm --manage /dev/md0 --remove /dev/sdc
mdadm --manage /dev/md0 --add /dev/sdhКод: Выделить всё
sysctl -w dev.raid.speed_limit_min=100000
sysctl -w dev.raid.speed_limit_max=500000Код: Выделить всё
mdadm --add /dev/md0 /dev/sdi
mdadm --grow /dev/md0 --raid-devices=6 \
--backup-file=/root/md0-reshape.bakКод: Выделить всё
pvresize /dev/md0
lvextend -l +100%FREE /dev/vg0/data
# XFS - только онлайн-рост, уменьшать нельзя:
xfs_growfs /mnt/data
# либо для ext4:
resize2fs /dev/vg0/dataКод: Выделить всё
systemctl enable --now mdmonitor.serviceКод: Выделить всё
MAILADDR ops@example.org
PROGRAM /usr/local/sbin/md-alert.shКод: Выделить всё
echo check > /sys/block/md0/md/sync_action
cat /sys/block/md0/md/mismatch_cnt- Забыли mdadm --detail --scan >> mdadm.conf и обновить initramfs (update-initramfs -u в Debian, dracut -f в RHEL) - после смены имён дисков массив собирается как /dev/md127 и не монтируется по fstab.
- Запустили reshape без backup-file и поймали отключение питания в critical section - массив может не собраться, данные под угрозой.
- RAID5 на дисках 8 ТБ+: ребилд идёт так долго, что вероятность второго отказа в окне реальна. Для крупных HDD берите RAID6.
- Спутали --fail диск с физическим выдёргиванием не того диска. Всегда сверяйте серийник по ls -l /dev/disk/by-id перед заменой.
- Демон mdmonitor выключен или MAILADDR пустой - деградацию замечают по упавшей производительности через неделю.
- После grow забыли pvresize/growfs - место в массиве есть, а файловая система его не видит.
- mismatch_cnt стабильно не ноль на RAID1/10 со свопом - часто ложная тревога, но на data-массиве это сигнал к расследованию.
- Создайте на стенде 6 loop-устройств по 1 ГБ (losetup) и соберите из пяти RAID6 с одним spare.
- Положите сверху LVM: pvcreate /dev/md0, vgcreate, lvcreate, отформатируйте в XFS и смонтируйте.
- Запишите тестовый файл с контрольной суммой. Сделайте --fail одного диска и наблюдайте автозамену spare в /proc/mdstat.
- Поднимите speed_limit_min и засеките, как изменилось время ребилда.
- Добавьте новый диск и расширьте массив через --grow с backup-file, затем pvresize и xfs_growfs.
- Настройте mdmonitor с MAILADDR (можно на локальный sendmail) и проверьте письмо, повторно уронив диск.
- Сверьте контрольную сумму файла - данные должны пережить все манипуляции.
- Почему для массива из дисков по 12 ТБ предпочтительнее RAID6, а не RAID5, и при чём тут окно ребилда?
- Что хранит backup-file при reshape и в каком сценарии его отсутствие приведёт к потере массива?
- Чем отличается поведение hot spare от ручной замены через --add, и когда recovery стартует автоматически?
- Какие два параметра ядра ограничивают скорость ребилда и почему опасно задирать только верхний предел?
- Какие шаги нужны после --grow, чтобы прирост ёмкости стал доступен приложению на XFS поверх LVM?
- Что означает mismatch_cnt, отличный от нуля, после scrub, и в каких случаях это не повод для паники?

