
В прошлых уроках конфиг лежал в локальном YAML рядом с каждым экземпляром. Это работает, но в кластере из десятков инстансов появляется боль: один и тот же config.yaml нужно положить на все машины, и при любой правке - заново разложить везы и проследить, чтобы файлы не разъехались. Один забытый узел со старым файлом - и у вас рассинхрон топологии.
Централизованное хранилище решает это так: единственный источник правды - внешнее распределённое key-value хранилище, а каждый инстанс при старте сам идёт туда и забирает свой кусок конфигурации. Tarantool 3.x поддерживает два типа такого хранилища:
- etcd - внешний распределённый KV-стор на алгоритме Raft (де-факто стандарт в мире Kubernetes).
- Tarantool-based config storage - реплика-сет самого Tarantool со встроенной ролью config.storage, который хранит конфиг в синхронных (raft-подобных) спейсах.
Как это устроено внутри: кворум и распространениеВажно: централизованные хранилища конфигурации - фича только Enterprise Edition. В Community Edition доступен лишь локальный YAML. Дальше речь про EE.
Главная идея - конфиг хранится не на одной ноде, а в кластере из нечётного числа узлов (обычно 3 или 5), которые держат данные согласованно через кворум.
Кворум etcd (Raft). etcd-кластер выбирает лидера; запись считается зафиксированной (committed), только когда её подтвердило большинство узлов - (N/2)+1. Для трёх узлов кворум - 2, значит кластер переживёт падение одного узла. Для пяти - переживёт падение двух. Когда вы делаете put конфига, лидер реплицирует запись в свой Raft-лог, ждёт подтверждения большинства и только потом отвечает "ок". Поэтому опубликованный конфиг сразу консистентен: любой инстанс, читающий с любого живого узла, увидит одну и ту же версию.
Раскладка ключей. Tarantool ищет конфигурацию по фиксированному шаблону:
Код: Выделить всё
<prefix>/config/*Код: Выделить всё
/myapp/config/allДоставка и watch. Инстанс при старте подключается к endpoint-ам, читает все ключи под префиксом, склеивает их и применяет к себе только релевантную часть (своя группа -> реплика-сет -> instance). После старта он не опрашивает хранилище в цикле, а вешает watch на префикс. etcd сам шлёт уведомление при изменении ключа - инстанс получает его и применяет новый конфиг на лету, без рестарта. Это и есть автоматический reload.
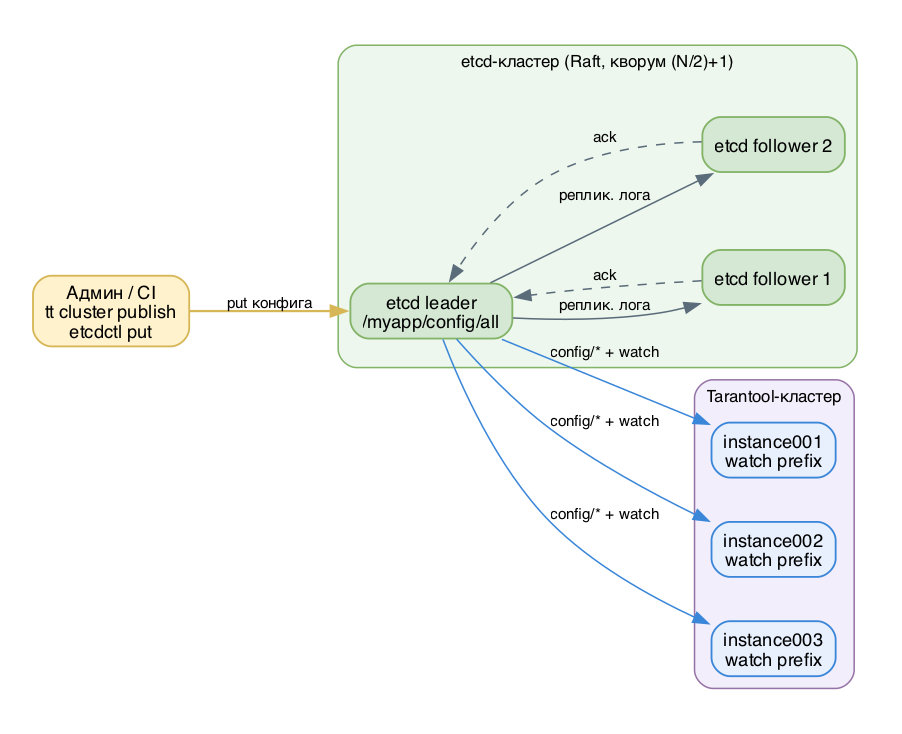
Публикация и watch-доставка конфига через кворум etcd
Ключевые команды и конфиги
1. Публикация конфига в etcd. Через tt (умеет и etcd, и Tarantool-стор):
Код: Выделить всё
# source.yaml - это полный кластерный конфиг
tt cluster publish "http://user:pass@localhost:2379/myapp" source.yaml
# посмотреть, что лежит в хранилище
tt cluster show "http://user:pass@localhost:2379/myapp"
Код: Выделить всё
etcdctl put /myapp/config/all < source.yaml
Код: Выделить всё
config:
etcd:
endpoints:
- http://localhost:2379
prefix: /myapp
username: sampleuser
password: '123456'
http:
request:
timeout: 3
3. Старт без локального файла - через переменные окружения:Грабли: внутри конфига, который лежит в etcd, секции config.etcd быть НЕ должно. Connection-настройки - это про то, как достать конфиг; класть их внутрь самого конфига нельзя (получите ошибку валидации).
Код: Выделить всё
export TT_CONFIG_ETCD_ENDPOINTS=http://localhost:2379
export TT_CONFIG_ETCD_PREFIX=/myapp
tarantool --name instance001
Код: Выделить всё
config:
reload: 'manual'
etcd:
# ...
Код: Выделить всё
require('config'):reload()
-- проверить текущий статус применения
require('config'):info()
Код: Выделить всё
replication.failover: electionКод: Выделить всё
database.use_mvcc_engine: trueЧастые заблуждения и грабли
- "Можно держать 2 узла etcd для отказоустойчивости". Нет. Кворум из 2 - это 2, падение любого узла останавливает запись. Нужно нечётное число: 3 или 5. Два узла хуже одного по доступности записи.
- "etcd упал - кластер встанет". Уже стартовавшие инстансы продолжат работать на последнем применённом конфиге; недоступным станет только reload и старт новых инстансов. Но если в этот момент инстанс перезапустится, он не сможет подняться без хранилища.
- "reload применит всё что угодно". Reload применяет только изменяемые в рантайме опции. Параметры вроде имени инстанса, путей к WAL/снапшотам, listen-порта при reload не меняются - для них нужен рестарт.
- "Префикс можно писать без слэша". Префикс обязан начинаться со слэша; Tarantool ищет строго по .
Код: Выделить всё
<prefix>/config/* - Failover-координатор. Если используете , etcd дополнительно хранит состояние координаторов отказоустойчивости. Это ещё один аргумент за надёжный кворум хранилища.
Код: Выделить всё
replication.failover: supervised
- Поднимите одноузловой etcd (для лабы кворум из одного достаточен): . Положите минимальный кластерный конфиг:
Код: Выделить всё
etcd. Запустите инстанс с TT_CONFIG_ETCD_ENDPOINTS и TT_CONFIG_ETCD_PREFIX. Затем измените один параметр (например log.level), сделайте повторный put и проверьте в консоли инстанса черезКод: Выделить всё
etcdctl put /myapp/config/all < source.yaml, что конфиг подхватился сам, без рестарта.Код: Выделить всё
require('config'):info()
- Сколько узлов etcd переживёт кластер из 5 без потери записи и почему именно столько?
- По какому шаблону пути Tarantool ищет конфигурацию в etcd и что произойдёт, если префикс задать без ведущего слэша?
- Чем отличается поведение при reload: 'manual' от поведения по умолчанию, и за счёт какого механизма работает автоматический режим?
- Зачем для Tarantool-based config storage обязательно включать MVCC и failover: election?