
Репликация в Tarantool - это механизм, при котором несколько экземпляров (instances) работают на копиях одних и тех же баз данных и держат их синхронными. Группа таких экземпляров называется replica set (репликасет). У каждого экземпляра внутри репликасета есть роль: master (доступен на запись) или replica (только чтение). Из ролей складываются топологии: классическая мастер-реплика и мастер-мастер (multi-master). В этом уроке разбираем не столько "как настроить", сколько как это работает внутри - откуда берётся синхронность, почему full mesh, и почему мастер-мастер не панацея.
Механика: WAL, LSN и vclock
Фундамент репликации - это write-ahead log (WAL). Каждое изменение данных (INSERT, UPDATE, DELETE) записывается в WAL как отдельная запись и получает монотонно растущий номер - LSN (log sequence number). Реплика не получает готовые строки; она непрерывно тянет (fetch) и применяет (apply) записи WAL мастера. Репликация в Tarantool row-based: каждый запрос детерминирован и работает с одним кортежем (tuple).
Чтобы понять, кто чьи изменения уже применил, нужны идентификаторы. У всего репликасета есть replica set UUID, у каждого экземпляра - instance UUID (глобально уникальный) и короткий instance ID (уникальный внутри репликасета, целое число). UUID хранится в системном спейсеВажная тонкость: вызовы хранимых функций в WAL не пишутся. Пишутся фактические data-change операции, которые эта Lua-функция выполнила. Поэтому возможный недетерминизм Lua (random, время, сеть) не ломает репликацию - реплики применяют уже зафиксированный результат, а не код.
Код: Выделить всё
box.space._clusterСостояние репликации отражает vclock (vector clock) - вектор "последний применённый LSN по каждому instance ID":
Код: Выделить всё
tarantool> box.info.vclock
---
- {1: 827, 2: 584}
...
-- от instance 1 применено 827 записей, от instance 2 - 584
Код: Выделить всё
box.info.replication[n].upstream.statusКод: Выделить всё
followПо умолчанию репликация асинхронная: мастер ответил клиенту "ок" сразу после локального коммита, не дожидаясь реплик. Если мастер тут же умрёт, после failover транзакция может "исчезнуть". Синхронную репликацию (per-space, опция is_sync) разбираем в отдельном уроке.
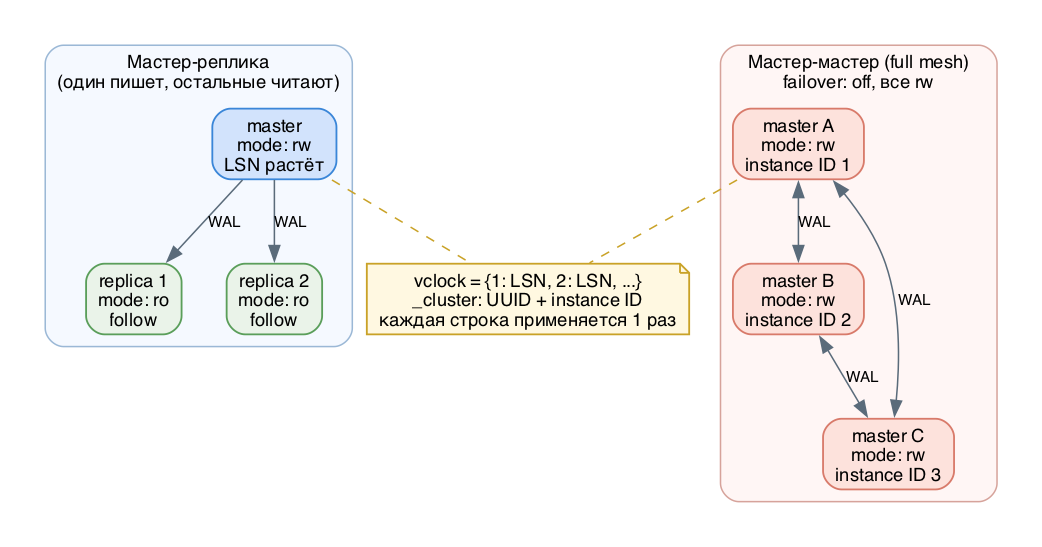
Топологии Tarantool: мастер-реплика и мастер-мастер full mesh
Топологии и роли
Роль задаётся параметром read_only (в декларативном конфиге 3.x -
Код: Выделить всё
database.mode: ro|rwМастер-реплика. Один пишет, остальные читают. Что меняется на мастере - видно на репликах, обратно - нет. Даёт две выгоды: failover (реплика подхватит, если мастер упал) и балансировку чтения. В 3.x за переключение лидера отвечает
Код: Выделить всё
replication.failoverКод: Выделить всё
manualКод: Выделить всё
leaderКод: Выделить всё
electionКод: Выделить всё
supervisedМастер-мастер (multi-master). Оба экземпляра в режиме rw, оба пишут, изменения видны в обе стороны. Настраивается через
Код: Выделить всё
replication.failover: offКод: Выделить всё
database.mode: rwТопология соединений задаётся параметром
Код: Выделить всё
replicationКод: Выделить всё
Топология Кто пишет Соединения Заметка
--------------- ------------- ---------------- ----------------------
master-replica один master mesh рекомендуется
master-master все instances full mesh нужна коммутативность
ring все/один кольцо поддерживается
cascade - цепочка НЕ рекомендуется
Ключевой код (3.x, декларативный config.yaml)Предел: максимум 32 экземпляра в full mesh.
Фрагмент конфигурации мастер-мастер из двух узлов:
Код: Выделить всё
credentials:
users:
replicator:
password: 'topsecret'
roles: [replication]
iproto:
advertise:
peer:
login: replicator
replication:
failover: off
groups:
group001:
replicasets:
replicaset001:
instances:
instance001:
database:
mode: rw
iproto:
listen:
- uri: '127.0.0.1:3301'
instance002:
database:
mode: rw
iproto:
listen:
- uri: '127.0.0.1:3302'
Код: Выделить всё
-- на каждом узле
box.info.ro --> false (узел доступен на запись)
box.info.replication --> upstream.status: follow
downstream.status: follow
box.info.vclock --> совпадает на обоих узлах
- "Мастер-мастер ускоряет запись." Нет. Запись в любом случае реплицируется на остальных; вы лишь распределяете точки входа. Зато получаете риск конфликтов.
- "Можно писать одно и то же на обоих мастерах." Безопасно, только если все изменения коммутативны - результат не зависит от порядка применения. Append-only безопасен. DELETE по TTL обычно тоже. А вот UPDATE с присваиванием или инкрементом не коммутативен и разъедет реплики.
- Конфликт дубликата ключа. Если на двух мастерах вставить кортеж с одним primary key, при встрече потоков станет
Код: Выделить всё
upstream.statusс ошибкой "Duplicate key exists". Лечится reseed (rebootstrap) отстающей реплики и перезапуском репликации.Код: Выделить всё
stopped - Split-brain. Два независимых лидера на запись (например, при ошибочном ниже N/2+1) приводят к ошибке
Код: Выделить всё
synchro_quorumи требуют rebootstrap. Защита целостности срабатывает при восстановлении связи.Код: Выделить всё
ER_SPLIT_BRAIN - Каскад "просто чтобы сэкономить трафик". Приводит к проблемам с _cluster UUID и отказам подключения. Используйте mesh.
Код: Выделить всё
before_replaceМини-лаба
- Поднимите репликасет из двух узлов через (см. конфиг выше). На instance001 создайте спейс и индекс, вставьте пару кортежей. На instance002 выполните
Код: Выделить всё
ttи убедитесь, что данные приехали. Затем вставьте новые кортежи уже на instance002 и проверьте их на instance001. СравнитеКод: Выделить всё
box.space.<name>:select()на обоих узлах - значения должны совпасть. Бонус: остановите instance002, вставьте на instance001 кортеж с ключом 5, отдельно на остановленном instance002 - другой кортеж с ключом 5, запустите обоих и посмотрите, какКод: Выделить всё
box.info.vclockперейдёт вКод: Выделить всё
upstream.status.Код: Выделить всё
stopped
- Что именно реплика тянет с мастера - готовые строки таблицы или записи WAL? Почему вызовы Lua-функций не реплицируются как код?
- Зачем в каждой записи WAL хранится instance ID, и как это связано с возможностью multi-master?
- Что показывает и как по нему понять, что узлы синхронизированы?
Код: Выделить всё
box.info.vclock - Почему мастер-мастер безопасен для append-only, но опасен для UPDATE-инкремента? Сформулируйте требование коммутативности.