
Когда одного сервера с дисками перестаёт хватать, а покупать дорогую SAN не хочется, на сцену выходят программно-определяемые распределённые файловые системы. GlusterFS собирает обычные серверы с локальными дисками в единое пространство имён, которое клиент монтирует как один большой каталог. Задача администратора - понимать, как из кирпичей и пиров собирается том нужного типа (распределённый, реплицированный, рассеянный), как его расширять без остановки, ребалансировать и чинить после сбоя узла. Сразу важная ремарка про 2026 год: коммерческая Red Hat Gluster Storage снята с поддержки в конце 2024, а upstream-проект (актуальная ветка 11.x) живёт в режиме сопровождения - правят баги и безопасность, новых фич почти нет. Для экзамена 306 и для существующих инсталляций знать его необходимо, но новые большие кластеры в 2026 чаще строят на Ceph.
Как это работает
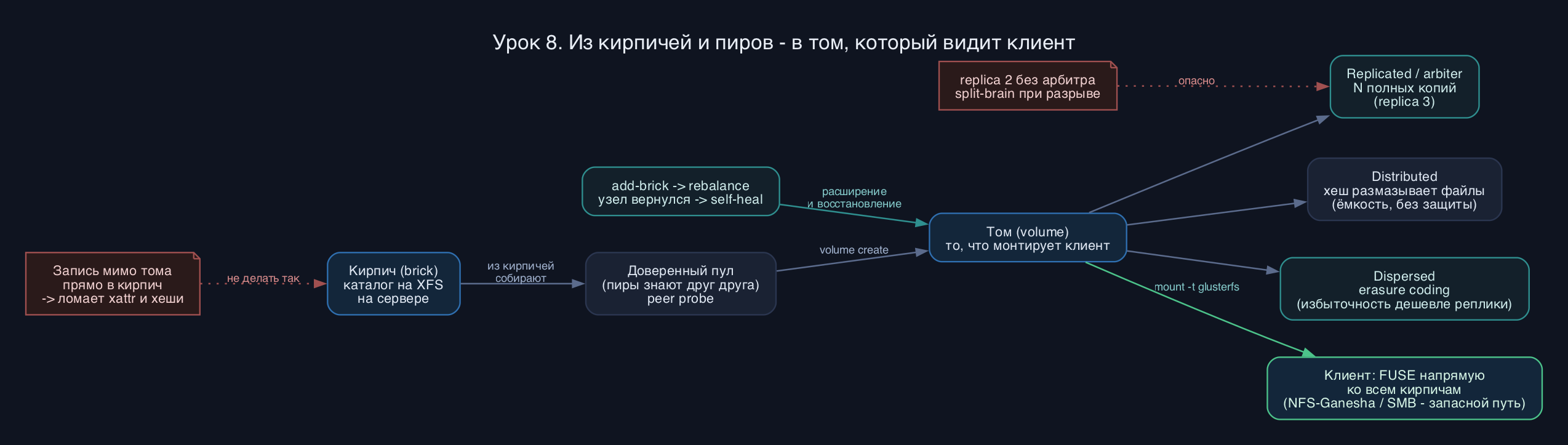
Базовый строительный блок GlusterFS - кирпич (brick). Это просто каталог на уже смонтированной локальной файловой системе сервера, например /data/brick1 на XFS. Gluster не форматирует диски сам и не управляет блочным уровнем - он работает поверх обычной ФС и хранит файлы как файлы, что упрощает восстановление: даже без Gluster данные с кирпича можно прочитать напрямую.
Серверы объединяются в доверенный пул (trusted storage pool) - набор пиров, которые знают друг о друге и доверяют по адресу или имени хоста. Внутри пула из кирпичей собираются тома (volumes). Том - это то, что видит клиент. Принципиально, что в GlusterFS нет выделенного сервера метаданных: где лежит файл, вычисляется алгоритмически по его имени через хеш-функцию (механизм DHT, distributed hash table). Это убирает единую точку отказа и узкое место, но имеет цену - операции вроде ls по огромному каталогу опрашивают все кирпичи и работают медленно.
Тип тома определяет, как файлы раскладываются по кирпичам. Distributed просто размазывает целые файлы по кирпичам через хеш - объём суммируется, но смерть одного кирпича теряет лежавшие на нём файлы. Replicated держит N полных копий файла на N кирпичах (replica 3 - три копии) - это надёжность ценой ёмкости. Dispersed (рассеянный) использует код стирания (erasure coding по схеме Рида-Соломона): файл бьётся на фрагменты данных плюс фрагменты избыточности, и том переживает потерю заданного числа кирпичей, тратя на избыточность меньше места, чем полная реплика. Эти типы комбинируются: distributed-replicated - самый частый прод-вариант, где реплики собраны в группы, а группы размазаны хешем.
Клиент монтирует том двумя путями. Нативный FUSE-клиент (glusterfs) сам знает топологию тома, общается со всеми кирпичами напрямую и выполняет репликацию на стороне клиента - именно он обеспечивает отказоустойчивость монтирования. NFS-доступ (через NFS-Ganesha в современных сборках, встроенный gnfs устарел) и SMB через Samba VFS нужны там, где FUSE недоступен, но они теряют клиентскую отказоустойчивость и требуют отдельной балансировки.
Самовосстановление (self-heal) - сердце надёжности реплик. Пока один узел реплики лежал, на нём накапливались устаревшие файлы. Демон self-heal (glustershd) сравнивает версии через служебные xattr (atributy trusted.afr.*) и докатывает изменения на отставший кирпич. Расширение тома добавлением кирпичей не перекладывает старые файлы автоматически - для этого запускается ребаланс, который пересчитывает хеши и двигает файлы под новую раскладку.
Команды и примеры
Установка. В Debian 13 / Ubuntu 24.04 пакеты идут из репозиториев дистрибутива:
Код: Выделить всё
apt install glusterfs-server xfsprogs
systemctl enable --now glusterd
Код: Выделить всё
dnf install centos-release-gluster # подключить Storage SIG (на CentOS Stream)
dnf install glusterfs-server xfsprogs
systemctl enable --now glusterd
Код: Выделить всё
mkfs.xfs -i size=512 /dev/sdb
mkdir -p /data/brick1
echo '/dev/sdb /data/brick1 xfs defaults 0 0' >> /etc/fstab
mount -a
Код: Выделить всё
gluster peer probe node2
gluster peer probe node3
gluster peer status
Код: Выделить всё
gluster volume create gv0 replica 3 \
node1:/data/brick1/gv0 node2:/data/brick1/gv0 node3:/data/brick1/gv0 \
node1:/data/brick2/gv0 node2:/data/brick2/gv0 node3:/data/brick2/gv0
gluster volume start gv0
gluster volume info gv0
Код: Выделить всё
gluster volume create gvdisp disperse 6 redundancy 2 \
node1:/d/b node2:/d/b node3:/d/b node4:/d/b node5:/d/b node6:/d/b
gluster volume start gvdisp
Код: Выделить всё
apt install glusterfs-client # или dnf install glusterfs-fuse
mount -t glusterfs node1:/gv0 /mnt/gv0
# в fstab с backupvolfile-server для отказоустойчивости начального коннекта:
# node1:/gv0 /mnt/gv0 glusterfs defaults,_netdev,backupvolfile-server=node2 0 0
Код: Выделить всё
gluster volume add-brick gv0 replica 3 \
node1:/data/brick3/gv0 node2:/data/brick3/gv0 node3:/data/brick3/gv0
gluster volume rebalance gv0 start
gluster volume rebalance gv0 status
Код: Выделить всё
gluster volume heal gv0 info
gluster volume heal gv0
gluster volume heal gv0 info split-brain
Код: Выделить всё
gluster volume replace-brick gv0 \
node2:/data/brick1/gv0 node2:/data/brick1new/gv0 commit force
gluster volume heal gv0 full
- replica 2 без арбитра почти гарантирует split-brain при сетевом разрыве - оба кирпича считают себя правыми. Используйте replica 3 либо replica 2 arbiter 1 (третий кирпич хранит только метаданные, занимает мало места и ломает ничью при голосовании).
- Кирпичи на корневой ФС или вложенные друг в друга каталоги. Свежий gluster ругается и требует force, и не зря - так теряют данные. Кирпич - всегда отдельная смонтированная ФС, выделенный подкаталог на ней.
- Добавили кирпичи через add-brick и забыли rebalance - новые кирпичи стоят пустыми, место не используется, нагрузка не распределяется.
- Имена хостов не резолвятся одинаково на всех узлах. peer probe по IP, а том по имени - и пул разваливается. Заведите единые имена в DNS или /etc/hosts на всех пирах.
- Прямая запись в каталог кирпича в обход тома (мимо точки монтирования Gluster). Это рушит xattr и хеши, self-heal сходит с ума. С кирпичом работают только через смонтированный том.
- Встроенный gluster-NFS (gnfs) считают устаревшим - для NFS поднимают NFS-Ganesha. Не путайте его с ядерным nfsd и не включайте оба сразу на 2049 порту.
- disperse-том чувствителен к производительности на мелких файлах и случайной записи - erasure coding дорог по CPU. Под базы и миллионы мелких файлов он подходит плохо, его стихия - крупные объекты и архивы.
- Помните про EOL: Red Hat Gluster Storage без поддержки с конца 2024, upstream в режиме сопровождения. Для новых проектов оценивайте Ceph, а GlusterFS держите осознанно.
- Поднимите три виртуалки (node1-3), на каждой добавьте по два чистых диска, сделайте на них XFS с -i size=512 и смонтируйте под /data/brick1 и /data/brick2.
- Установите glusterfs-server, запустите glusterd, с node1 выполните peer probe на node2 и node3, проверьте gluster peer status - должно быть два пира в состоянии Peer in Cluster.
- Соберите распределённо-реплицированный том replica 3 из шести кирпичей, запустите его и изучите вывод gluster volume info.
- С четвёртой машины-клиента смонтируйте том через FUSE с опцией backupvolfile-server, запишите туда сотню файлов и убедитесь скриптом, что копии лежат на трёх кирпичах группы.
- Жёстко выключите node3, дозапишите файлы с клиента, верните node3, запустите gluster volume heal gv0 и проследите по heal info, как отставший кирпич догоняется.
- Добавьте третью группу реплик через add-brick replica 3, выполните rebalance start и убедитесь по status, что часть файлов переехала на новые кирпичи.
- Сэмулируйте смерть кирпича: удалите его каталог, выполните replace-brick на новый путь с commit force и heal full, проверьте восстановление данных.
- Почему в GlusterFS нет выделенного сервера метаданных и как клиент узнаёт, на каком кирпиче лежит нужный файл?
- Чем рассеянный (dispersed) том выгоднее реплицированного по ёмкости и в каких сценариях он, наоборот, проигрывает?
- Что такое split-brain в replica 2, как от него защищает арбитр и почему replica 3 надёжнее?
- Зачем после add-brick нужен rebalance и что именно он делает с уже лежащими на томе файлами?
- Как работает self-heal: по каким признакам демон определяет отставший кирпич и докатывает на него изменения?
- Почему запись напрямую в каталог кирпича в обход смонтированного тома опасна, и в чём преимущество и недостаток NFS/SMB-доступа против нативного FUSE-клиента?

