
В предыдущих уроках вы научились давать нескольким узлам один и тот же блочный том - через общий SAN-LUN или через DRBD в режиме dual-primary. Но блочное устройство - это просто массив секторов. Если вы возьмёте обычный ext4 или XFS и смонтируете его на двух узлах одновременно, вы получите не отказоустойчивость, а гарантированное разрушение данных за минуты. Этот урок про то, как сделать одну файловую систему, которую несколько узлов читают и пишут параллельно и при этом не дерутся за метаданные. Разберём GFS2 и OCFS2, их зависимость от DLM и кворумного кластера, форматирование с журналами по узлам, монтирование, и главное - чем кластерная ФС принципиально отличается от распределённой.
Как это работает
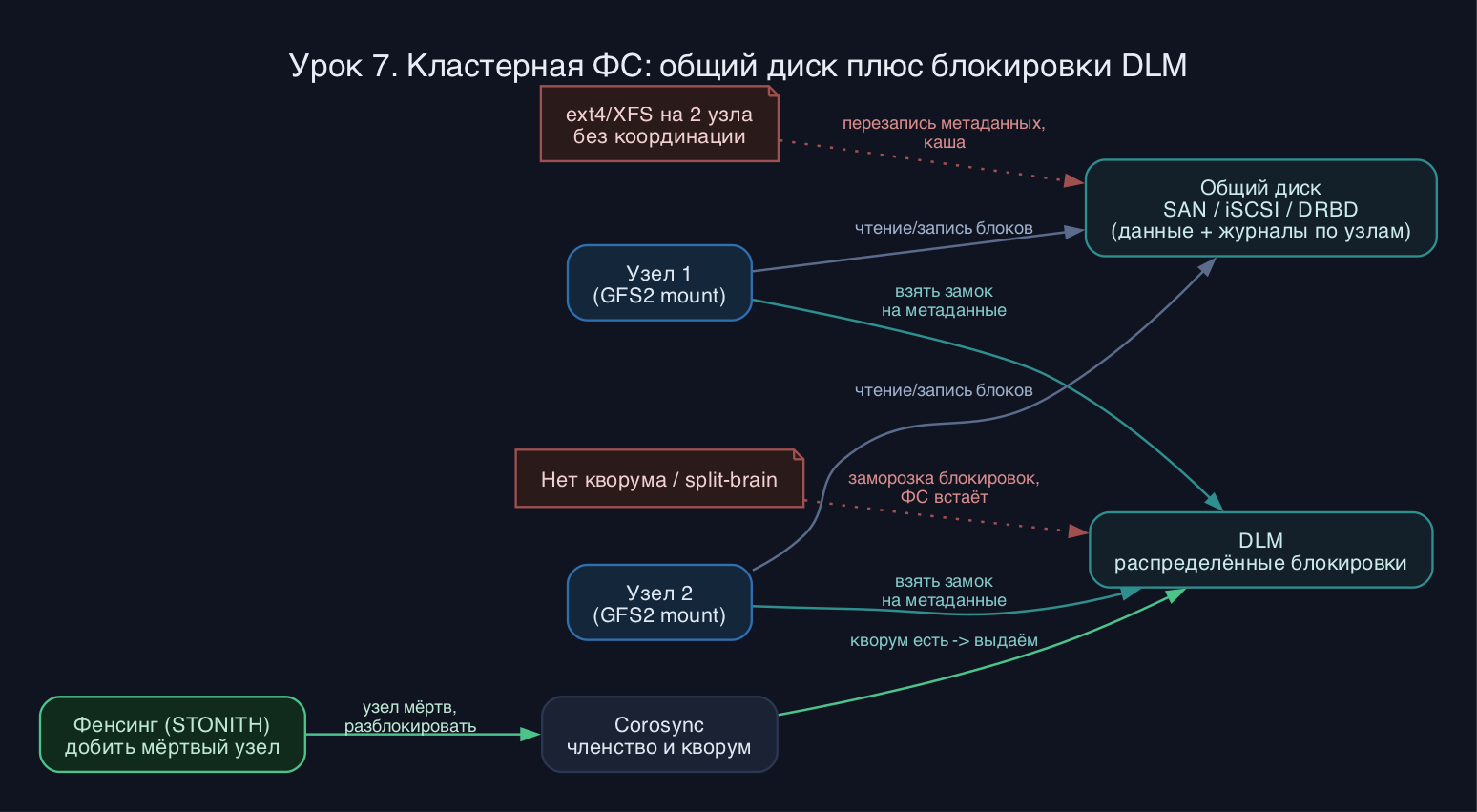
Любая обычная локальная ФС считает, что она единственный хозяин устройства. Она кеширует блоки метаданных в памяти, отложенно сбрасывает их на диск, держит inode-битмапы и журнал в расчёте на то, что никто другой эти же секторы не трогает. Смонтируйте такую ФС на двух узлах - и каждый закеширует свою версию суперблока и битмапов, они начнут писать друг поверх друга, и согласованности не будет ни на диске, ни в памяти. Файловую систему это не чинит fsck, потому что повреждение не структурное, а логическое.
Кластерная ФС решает ровно эту проблему. Она не хранит метаданные на разных дисках - она хранит их на одном общем устройстве, но координирует доступ к ним между узлами через распределённую блокировку. Перед тем как узел тронет inode, каталог или блок данных, он берёт на него кластерную блокировку. Эту блокировку выдаёт DLM - Distributed Lock Manager, который работает поверх кластерного стека Corosync. Узел, изменивший метаданные, обязан сбросить их на диск и отдать блокировку, прежде чем другой узел её получит. Так все видят согласованное состояние.
Отсюда жёсткая зависимость: кластерная ФС не запускается без кворумного кластера. DLM получает членство и кворум от Corosync, а в Pacemaker за неё отвечают ресурсы dlm и lvmlockd (или clvmd на старых системах). Нет кворума - DLM замораживает все блокировки, и ФS встаёт колом. Это сделано намеренно: лучше зависнуть, чем продолжать писать в расколотом кластере (split-brain). Поэтому фенсинг (STONITH) обязателен - DLM не разблокируется, пока кластер не убедится, что отвалившийся узел гарантированно мёртв и не пишет в общий том.
Второй ключевой момент - журналы по узлам. У обычной ФС один журнал. У кластерной их несколько: по одному на каждый узел, который монтирует ФС одновременно. Если бы журнал был общий, узлы дрались бы ещё и за него. Поэтому при форматировании вы заранее указываете число журналов, и это число задаёт верхний предел одновременных монтирований. Хотите добавить узлы сверх лимита - доращиваете журналы отдельной операцией.
Теперь отличие от распределённых ФС, которое любят спрашивать. Кластерная ФС (GFS2, OCFS2) - это shared-disk: все узлы видят одно и то же блочное устройство (SAN, iSCSI, DRBD), а сетью гоняются только блокировки и небольшие сообщения координации. Данные по сети не передаются, узлы читают их прямо с общего диска. Распределённая ФС (CephFS, GlusterFS) - это shared-nothing: у каждого узла свои локальные диски, а сами данные реплицируются и собираются по сети. Кластерная ФС даёт低 задержку и точную POSIX-семантику, но плохо масштабируется за десяток узлов и требует общего хранилища. Распределённая масштабируется на сотни узлов на обычном железе, но платит сетевой задержкой и более слабыми гарантиями.
Команды и примеры
Сначала ставим пакеты. Состав отличается по семействам.
Debian 13 / Ubuntu 24.04 LTS:
Код: Выделить всё
apt install gfs2-utils dlm-controld lvm2-lockd
# для OCFS2:
apt install ocfs2-tools
Код: Выделить всё
dnf install gfs2-utils dlm lvm2-lockd
# OCFS2 в RHEL официально не поставляется, это путь Oracle Linux/SUSE
Код: Выделить всё
mkfs.gfs2 -p lock_dlm -t mycluster:webdata -j 3 /dev/vg_shared/lv_web
Монтирование - на каждом узле обычным mount, тип gfs2:
Код: Выделить всё
mount -t gfs2 /dev/vg_shared/lv_web /srv/web
 Filesystem) с упорядочиванием после dlm и lvmlockd, а не строка в /etc/fstab. Добавить журнал под новый узел на смонтированной ФС:
Filesystem) с упорядочиванием после dlm и lvmlockd, а не строка в /etc/fstab. Добавить журнал под новый узел на смонтированной ФС:Код: Выделить всё
gfs2_jadd -j 1 /srv/web # добавит один журнал
gfs2_grow /srv/web # расширить ФС после роста LV
Код: Выделить всё
mkfs.ocfs2 -N 8 -L webdata /dev/sdb1
# -N - число node slots (аналог журналов/слотов), -L - метка
tunefs.ocfs2 --node-slots 12 /dev/sdb1 # нарастить слоты позже
Частые грабли
- Смонтировать ext4/XFS на двух узлах сразу. Это не кластерная ФС, координации нет, данные превратятся в кашу. XFS поверх общего LUN допустим только в active/passive, когда монтирует строго один узел.
- Забыть про фенсинг. Без рабочего STONITH DLM при сбое узла навсегда заморозит блокировки, и вся ФС зависнет до ручного вмешательства. Это не баг, это защита от split-brain.
- Несовпадение имени кластера в ключе -t и в Corosync. ФС просто не смонтируется, а ошибка в логах неочевидная.
- Слишком мало журналов/слотов. Поставили -j 2, а узлов три - третий не смонтирует, пока не добавите журнал. Планируйте с запасом.
- Ждать от кластерной ФС масштабирования как у Ceph. На десятках узлов GFS2 захлебнётся в трафике блокировок DLM. Это инструмент для 2-8 узлов с общим диском, а не для сотен.
- Тяжёлые нагрузки с конкуренцией за одни и те же файлы/каталоги. Постоянная передача блокировок (lock ping-pong) убивает производительность. Разносите рабочие наборы узлов по разным каталогам.
- Соберите кластер из двух-трёх узлов с уже работающими Corosync, Pacemaker и настроенным фенсингом (хотя бы fence_virsh в виртуалке).
- Дайте узлам общий том: проще всего DRBD в dual-primary или один iSCSI-LUN, экспортированный на все узлы.
- Поднимите в Pacemaker клон-ресурсы dlm и lvmlockd, дождитесь, что они Started на всех узлах.
- Отформатируйте том: mkfs.gfs2 -p lock_dlm -t ИмяВашегоКластера:lab -j 3 /dev/... - число журналов не меньше числа узлов.
- Смонтируйте ФС на всех узлах (вручную mount -t gfs2), создайте файл на одном узле, убедитесь, что он мгновенно виден на остальных.
- Проверьте координацию: запишите в один файл с двух узлов поочерёдно, посмотрите dlm_tool ls и счётчики блокировок.
- Сымитируйте сбой: грубо вырубите один узел (kill питания ВМ) и проследите, как фенсинг подтверждает смерть, а DLM возвращает блокировки выжившим.
- Почему обычную ext4 или XFS нельзя смонтировать на двух узлах одновременно, и какое именно повреждение это вызывает?
- Какую роль играет DLM и от какого компонента он получает информацию о кворуме и членстве?
- Зачем кластерной ФС несколько журналов и что произойдёт при попытке смонтировать ФС на узлах больше, чем создано журналов?
- Что означает ключ -t в mkfs.gfs2 и к каким последствиям приведёт несовпадение имени кластера?
- Почему фенсинг (STONITH) обязателен для GFS2/OCFS2, а не желателен?
- В чём принципиальная разница между кластерной (shared-disk) и распределённой (shared-nothing) ФС, и в каком сценарии выбирают каждую?

