
В прошлом уроке мы собрали образ и запустили контейнер. Но контейнер сам по себе бесполезен, пока ему некуда складывать данные, не с кем общаться по сети, пока его логи неуправляемы, а аппетит к памяти и CPU ничем не ограничен. Этот урок про то, как Docker подключает хранилище, строит сети, собирает логи и режет ресурсы через cgroups v2. Это ровно та часть, где админ перестаёт играть и начинает эксплуатировать.
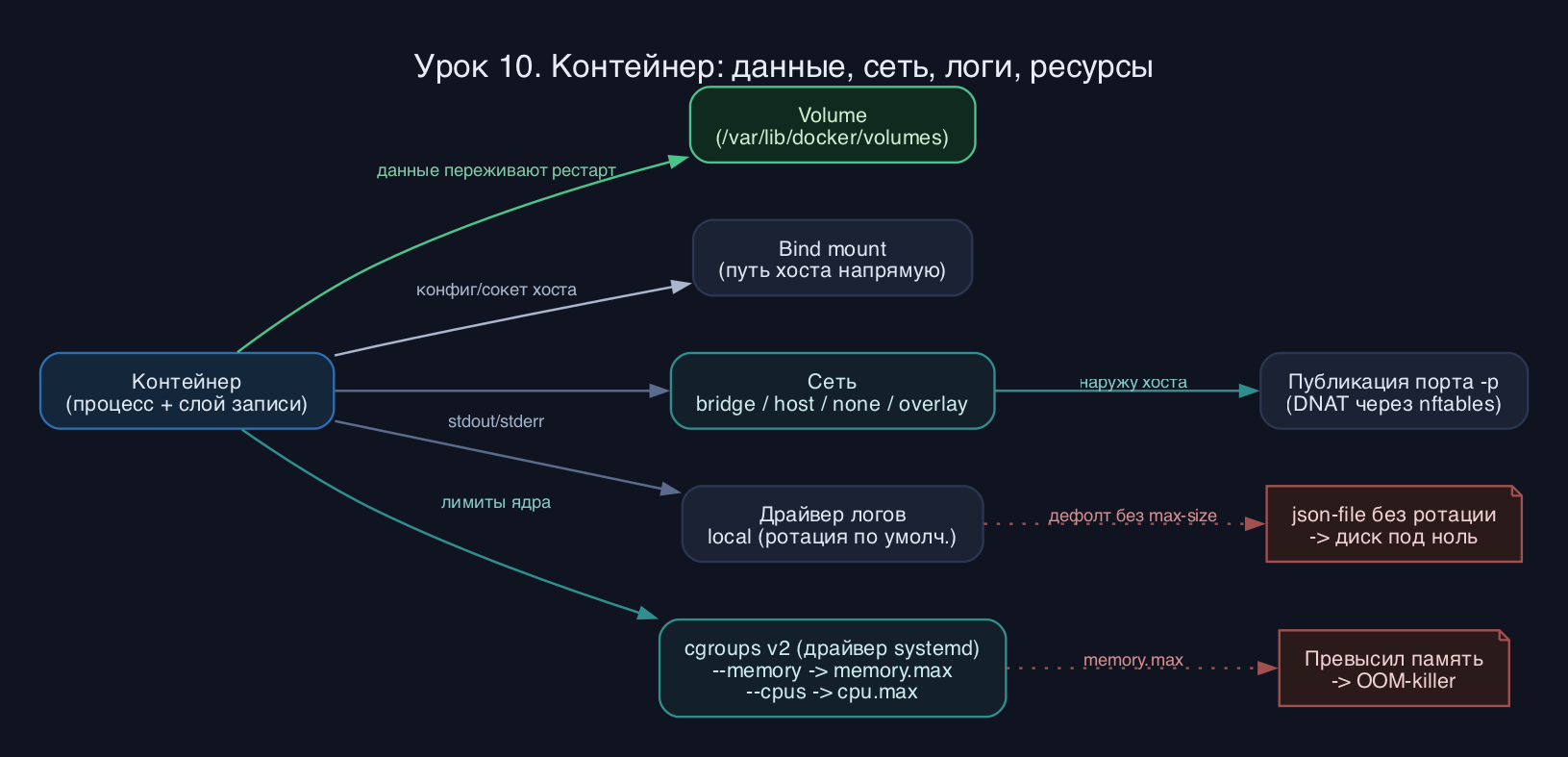
Как это работает
Слой записи контейнера эфемерный: удалили контейнер - потеряли всё, что он туда нагенерил. Чтобы данные пережили перезапуск, их выносят наружу. Есть два механизма. Том (volume) - это каталог, которым управляет сам Docker внутри /var/lib/docker/volumes, с собственным жизненным циклом. Bind mount - это когда вы напрямую подсовываете контейнеру конкретный путь хоста. Том переносимый и не зависит от структуры хоста, поэтому для данных приложений рекомендуют именно его. Bind mount удобен, когда нужно дать контейнеру реальный файл хоста (конфиг, сокет, исходники при разработке), но он жёстко привязан к ФС хоста и легко ломает изоляцию.
Сеть в Docker построена на драйверах. По умолчанию контейнеры попадают в bridge - программный коммутатор docker0, за которым стоит NAT через nftables (в современных ядрах iptables-команды Docker транслируются в nft, legacy-таблицы это наследие). Драйвер host убирает сетевую изоляцию вообще: контейнер делит сетевой стек с хостом, публикация портов не нужна и не работает. Драйвер none даёт только loopback - полная изоляция. Overlay соединяет контейнеры на разных хостах в один L2-сегмент поверх VXLAN, это основа Swarm. Пользовательский bridge отличается от дефолтного тем, что в нём работает встроенный DNS по именам контейнеров - это важно, дефолтный bridge резолвинг по имени не даёт.
Публикация порта (-p 8080:80) ставит правило DNAT: трафик на порт 8080 хоста перенаправляется на порт 80 внутри контейнера. Без публикации порт виден только внутри сети Docker, наружу хоста его нет.
Логи контейнера - это то, что процесс пишет в stdout и stderr. Перехватывает их драйвер логирования. По умолчанию это json-file: построчный JSON в /var/lib/docker/containers. Беда дефолта в том, что без настройки ротации он растёт безгранично и однажды забивает диск. На 2026 год для одиночных хостов рекомендуют драйвер local - бинарный сжатый формат с включённой по умолчанию ротацией. json-file оставлен дефолтом ради совместимости и потому, что его парсят сборщики логов Kubernetes. Драйверы вроде journald, syslog, fluentd отдают логи во внешние системы. Важно: docker logs работает только с json-file, local и journald.
Ограничение ресурсов опирается на cgroups v2 - единую иерархию ядра, которой через драйвер systemd управляет Docker. На Debian 13, Ubuntu 24.04, RHEL 10 и Fedora 41+ v2 включена из коробки, а драйвер cgroup по умолчанию systemd. Флаг --memory ставит жёсткий потолок памяти (cgroup memory.max): превысил - процесс убивает OOM-killer ядра. Флаг --cpus задаёт долю процессорного времени (через cpu.max, он же CPUQuota у systemd): --cpus=1.5 это полтора ядра. Это не привязка к конкретным ядрам, а квота времени на период.
Команды и примеры
Тома и bind mount. Современный синтаксис --mount явный и предпочтительнее старого -v:
Код: Выделить всё
docker volume create appdata
docker run -d --name db \
--mount type=volume,src=appdata,dst=/var/lib/postgresql/data \
postgres:17
# bind mount каталога хоста, только чтение
docker run --rm \
--mount type=bind,src=/etc/myapp,dst=/etc/myapp,ro \
alpine cat /etc/myapp/config.yml
docker volume ls
docker volume inspect appdata
docker volume rm appdata
Код: Выделить всё
docker network create --driver bridge backend
docker run -d --name redis --network backend redis:7
docker run --rm --network backend alpine ping -c1 redis # резолвится по имени
docker network ls
docker network inspect backend
docker run -d --network host nginx # стек хоста, -p игнорируется
docker run --rm --network none alpine ip a # только lo
Код: Выделить всё
docker run -d --name app \
--log-driver local \
--log-opt max-size=10m --log-opt max-file=3 \
myapp:latest
Код: Выделить всё
{
"log-driver": "local",
"log-opts": { "max-size": "10m", "max-file": "5" }
}
Код: Выделить всё
sudo systemctl restart docker
docker info --format '{{.LoggingDriver}}'
Код: Выделить всё
docker run -d --name limited \
--memory 512m --memory-swap 512m \
--cpus 1.5 \
nginx
docker stats limited --no-stream
docker info | grep -i cgroup # Cgroup Version: 2, Driver: systemd
cat /sys/fs/cgroup/system.slice/docker-*.scope/memory.max
Код: Выделить всё
stat -fc %T /sys/fs/cgroup/ # cgroup2fs = v2
Код: Выделить всё
docker system df # сколько занято образами, томами, кэшем
docker container prune # удалить остановленные контейнеры
docker image prune -a # все образы без контейнеров
docker volume prune # ОСТОРОЖНО: висячие тома, это данные
docker builder prune # кэш сборки
docker system prune -a --volumes # снести всё лишнее разом
- json-file без max-size забивает диск под ноль, и узнаёшь об этом, когда демон уже не стартует. Ставьте ротацию глобально в daemon.json, по контейнеру задним числом не применится.
- docker volume prune и тем более system prune --volumes сносят данные без подтверждения по имени. Один лишний ключ - и базы нет.
- Дефолтный bridge не резолвит контейнеры по имени. Завязались на --link (он deprecated) - переходите на пользовательскую сеть.
- --memory-swap по умолчанию равен удвоенному --memory, то есть своп всё равно доступен. Чтобы реально запретить своп, явно ставьте --memory-swap равным --memory.
- Лимиты применились, а контейнер их не видит изнутри (free, nproc показывают хост). Это нормально: cgroup ограничивает, но не подменяет /proc. JVM и Node до сих пор иногда читают хостовую память - проверяйте флаги рантайма.
- На старом ядре с cgroup v1 часть лимитов v2 (например memory.max swap) ведёт себя иначе. Сверяйтесь с docker info, не полагайтесь на привычки.
- host-сеть несовместима с -p и убивает изоляцию портов: контейнер занимает порты хоста напрямую, конфликты гарантированы.
- Создайте том appdata и пользовательскую сеть backend.
- Запустите postgres:17 с томом на /var/lib/postgresql/data, в сети backend, с лимитами --memory 512m --cpus 1.0 и драйвером логов local.
- Подключите второй контейнер (alpine) в backend и пингуйте postgres по имени - убедитесь, что DNS работает.
- Нагрузите контейнер и посмотрите docker stats: упирается ли он в заданный потолок CPU.
- Проверьте memory.max контейнера в /sys/fs/cgroup и сравните с заданным лимитом.
- Удалите контейнер postgres, создайте заново на тот же том - данные должны быть на месте.
- Прогоните docker system df, затем docker container prune и docker image prune. Том appdata не трогайте.
- Чем volume отличается от bind mount по жизненному циклу и переносимости, и какой когда выбирать?
- Почему контейнеры в пользовательском bridge видят друг друга по имени, а в дефолтном bridge - нет?
- Что делает -p 8080:80 на уровне ядра и почему этот ключ бессмысленен при --network host?
- Почему драйвер local в 2026 предпочтительнее json-file и в чём подвох дефолта?
- Как --cpus=1.5 и --memory=512m отображаются на cgroup v2, и что произойдёт при превышении памяти?
- Чем опасен docker system prune --volumes и как чистить безопасно?

