
Контейнер - это не маленькая виртуалка и не магия. Это обычный процесс на вашем хосте, которому ядро показывает урезанную и подмененную картину системы. Задача администратора - понимать, ЧТО именно изолирует контейнер, а что остается общим с хостом, потому что от этого зависят и безопасность, и отладка, и расследование инцидентов. В этом уроке мы разберем кирпичи, из которых ядро Linux собирает контейнер: namespaces, cgroups v2, capabilities, seccomp, а также LSM (SELinux и AppArmor). Потом сравним контейнер с виртуальной машиной и закроем тему стандартами OCI и режимом rootless.
Как это работает
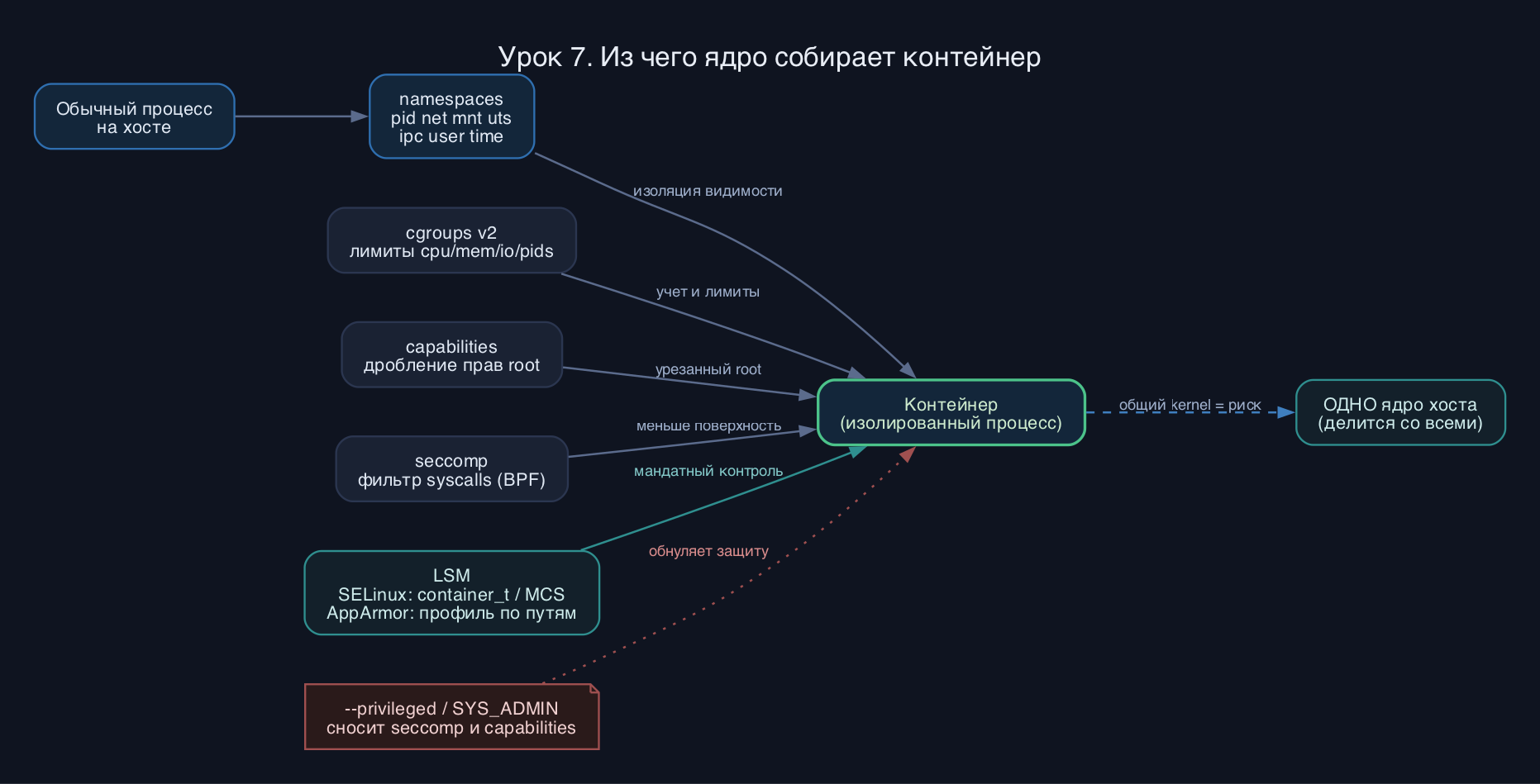
Главная идея: в Linux нет системного вызова create_container. Есть набор независимых механизмов ядра, а среда выполнения (runc, crun) просто комбинирует их при запуске обычного процесса. Уберите все эти механизмы - и контейнер превратится в простой процесс хоста.
Namespaces дают процессу собственную копию какого-то глобального ресурса ядра. Их несколько видов. PID namespace дает свое дерево процессов, где главный процесс контейнера получает PID 1. NET namespace дает отдельный стек сети: свои интерфейсы, таблицы маршрутизации, правила nftables. MNT namespace - свое дерево монтирования, поэтому контейнер видит свою корневую ФС. UTS - свои hostname и domainname. IPC - свою область System V IPC и POSIX-очередей. USER namespace отображает UID/GID контейнера на другие UID/GID хоста, и именно он позволяет быть root внутри, оставаясь непривилегированным снаружи. Time namespace (более новый) подменяет показания монотонных часов. Все это просто разные view на одно ядро - ядро у хоста и контейнера ОДНО.
Cgroups v2 отвечают не за изоляцию видимости, а за лимиты и учет ресурсов. Это единая иерархия (unified hierarchy), смонтированная в /sys/fs/cgroup, где для группы процессов задаются memory.max, cpu.max, io.max, pids.max. На современных системах cgroups v1 уже снят с поддержки, и systemd, и контейнерные движки работают через v2.
Capabilities дробят всемогущество root на отдельные права. Вместо булева root/не-root ядро проверяет конкретный бит: CAP_NET_BIND_SERVICE (слушать порт ниже 1024), CAP_NET_ADMIN, CAP_SYS_ADMIN (самая опасная, почти равна root). Движки по умолчанию выдают контейнеру урезанный набор и срезают остальное.
Seccomp фильтрует системные вызовы через BPF-программу. Профиль по умолчанию у Docker и Podman блокирует десятки опасных вызовов (например keyctl, ptrace в чужие процессы) и резко уменьшает поверхность атаки на ядро.
LSM - дополнительный слой мандатного контроля. В RHEL/Fedora это SELinux: контейнерным процессам присваивается тип container_t, а файлам - метка с категориями (MCS), так что процесс одного контейнера не лезет в файлы другого. В Debian/Ubuntu по умолчанию AppArmor с профилем вроде docker-default или подключаемым crun-профилем, который ограничивает доступ по путям.
Отличие от ВМ принципиальное. Виртуалка через гипервизор эмулирует железо и крутит ПОЛНОЕ гостевое ядро - сильная изоляция, но накладные расходы и медленный старт. Контейнер делит ядро хоста - почти нулевой оверхед и старт за миллисекунды, но дыра в ядре пробивает всю изоляцию. Отсюда промежуточные решения вроде Kata Containers, где под видом контейнера прячется микро-ВМ.
OCI (Open Container Initiative) - набор спецификаций, которые делают экосистему совместимой. Image Specification описывает формат образа: слои, манифест, конфиг. Runtime Specification описывает config.json и жизненный цикл уже распакованного контейнера (bundle), который запускает низкоуровневый runtime - runc или crun. Стандарт развязал сборку, хранение и запуск, поэтому образ из Docker одинаково стартует в Podman, containerd и CRI-O в Kubernetes.
Rootless - запуск всего стека без root на хосте. Опирается на USER namespace и subuid/subgid: ваш UID отображается в root ВНУТРИ контейнера, а наружу остается ваш непривилегированный пользователь. Сеть поднимается в user space через slirp4netns или pasta. Главный профит для безопасности: компрометация контейнера не дает root на хосте.
Команды и примеры
Посмотреть список и тип namespaces текущей системы и процесса:
Код: Выделить всё
lsns
lsns -p $$
ls -l /proc/self/ns/
Код: Выделить всё
unshare --user --map-root-user --pid --mount-proc --net --uts --fork bash
# внутри:
id # uid=0(root) - но это root только в user namespace
hostname c1 # своя UTS
ip a # пустой стек сети - свой NET namespace
Код: Выделить всё
stat -fc %T /sys/fs/cgroup # cgroup2fs = v2
Код: Выделить всё
docker run --rm \
--cap-drop=ALL --cap-add=NET_BIND_SERVICE \
--security-opt seccomp=/etc/docker/seccomp.json \
--pids-limit 100 --memory 256m \
nginx
Код: Выделить всё
podman run --rm \
--cap-drop=ALL --cap-add=CAP_NET_BIND_SERVICE \
--security-opt seccomp=/usr/share/containers/seccomp.json \
--pids-limit 100 --memory 256m \
docker.io/library/nginx
Код: Выделить всё
podman exec myctr grep Cap /proc/1/status
podman exec myctr cat /proc/1/attr/current # на RHEL: ...:container_t:s0:c123,c456
Код: Выделить всё
grep $(whoami) /etc/subuid /etc/subgid
# при отсутствии записи:
sudo usermod --add-subuids 100000-165535 --add-subgids 100000-165535 $(whoami)
podman system migrate
Код: Выделить всё
cat /sys/kernel/security/lsm # покажет selinux или apparmor среди прочих
getenforce # RHEL/Fedora: Enforcing
aa-status # Debian/Ubuntu: профили AppArmor
- Путать изоляцию и лимиты. Namespaces скрывают ресурсы, cgroups их ограничивают. Без cgroups контейнер съест всю память хоста, хотя процессов чужих и не видит.
- Думать, что root в контейнере безопасен сам по себе. Без user namespace UID 0 внутри - это UID 0 снаружи на смонтированных томах. Спасает rootless или --userns.
- --cap-add=SYS_ADMIN ради удобства. Эта capability фактически возвращает почти полный root и обнуляет смысл изоляции.
- --privileged в проде. Он снимает seccomp, отдает все capabilities и устройства - последняя мера для отладки, не для эксплуатации.
- На RHEL ловить Permission denied при bind-mount тома. Это SELinux: нужен суффikс :Z (приватная метка) или :z (общая) у -v, а не chmod 777.
- Отключать seccomp профиль (--security-opt seccomp=unconfined), чтобы заработала программа. Сначала разберитесь, какой syscall блокируется (audit/strace), и допишите профиль.
- Считать cgroups v1 рабочим вариантом в 2026. Он удален из поддержки; rootless-лимиты cpu/memory корректно работают только на v2.
- Шаг 1. Выполните lsns и запишите, какие namespaces уже есть у вашей shell.
- Шаг 2. Запустите unshare с флагами --user --map-root-user --pid --net --uts --mount-proc --fork bash и убедитесь через id, hostname, ip a, что вы в изолированной среде, но при этом непривилегированный снаружи (во втором терминале проверьте свой реальный UID процесса bash).
- Шаг 3. Установите podman (dnf или apt), проверьте записи в /etc/subuid и при необходимости добавьте их, затем запустите rootless-контейнер podman run --rm -it alpine sh.
- Шаг 4. Внутри сделайте id (root) и в другом терминале хоста найдите процесс через ps - убедитесь, что снаружи он бежит под вашим непривилегированным UID или из диапазона subuid.
- Шаг 5. Запустите контейнер с --cap-drop=ALL и попробуйте сменить hostname внутри - получите отказ; добавьте нужную capability и повторите.
- Шаг 6. На RHEL смонтируйте том без :Z, поймайте отказ доступа, затем с :Z - и сравните метку через ls -Z.
- Какой namespace отвечает за то, что главный процесс контейнера видит себя как PID 1, и что произойдет, если этот процесс завершится?
- Чем принципиально отличается роль cgroups v2 от роли namespaces при создании контейнера?
- Почему контейнер с UID 0 внутри без user namespace опаснее, чем тот же контейнер в rootless-режиме?
- Какие две OCI-спецификации существуют и за что отвечает каждая из них?
- Что делает флаг --privileged и почему его не стоит использовать в продакшене?
- Как SELinux в режиме MCS не дает процессу одного контейнера читать файлы другого и какой суффикс у bind-mount это учитывает?

