
Прежде чем поднимать первую виртуалку на KVM или запускать контейнер в podman, нужно разложить по полкам сам зоопарк технологий: чем полная виртуализация отличается от паравиртуализации, почему гипервизор типа 1 быстрее типа 2, где проходит граница между эмуляцией и виртуализацией и зачем в современном ядре вообще нужны расширения VT-x и AMD-V. Этот урок решает задачу архитектора: выбрать правильный инструмент под нагрузку и не наступить на грабли оверкоммита и NUMA в проде. Дальше будут конкретные команды и конфиги libvirt, но без этой картины в голове они превратятся в копипасту.
Как это работает
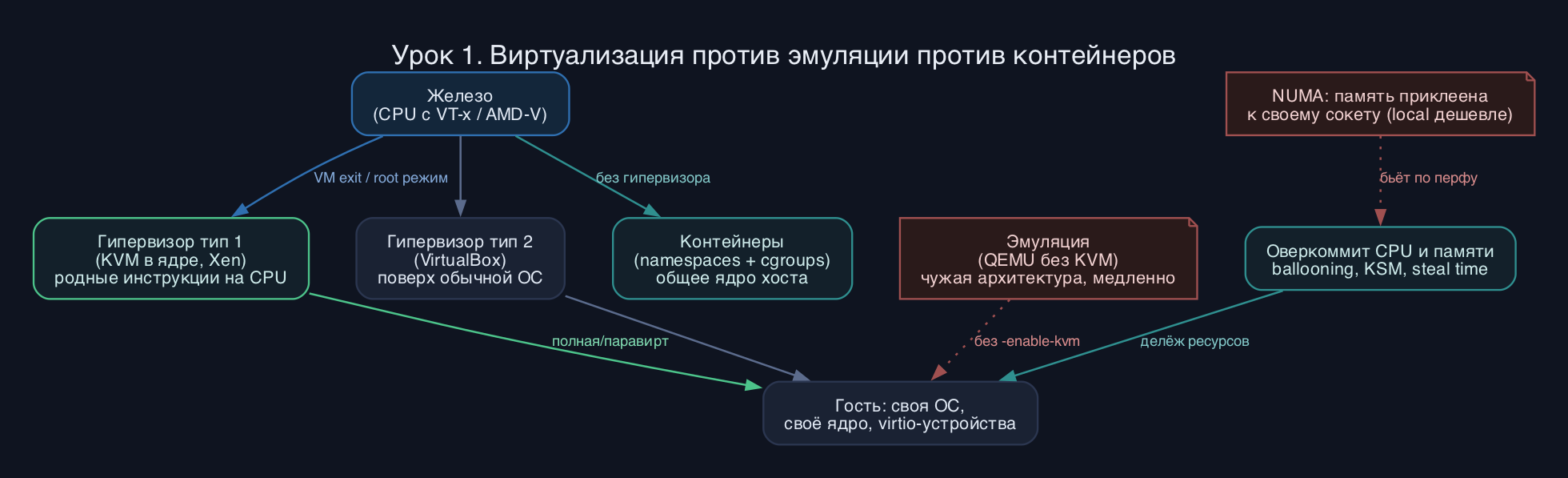
Виртуализация - это иллюзия отдельной машины, которую гипервизор продаёт гостевой ОС. Гость думает, что владеет процессором, памятью и устройствами, а на деле делит их с соседями. Ключевая проблема: на x86 часть инструкций исторически вела себя по-разному в нулевом и третьем кольце защиты, но не вызывала исключения при выполнении из гостя. Поэтому изоляцию приходилось городить программно.
Полная виртуализация (full virtualization) даёт гостю немодифицированную ОС: она не знает, что виртуализирована. Раньше это достигалось бинарной трансляцией опасных инструкций на лету (так делал ранний VMware). Паравиртуализация (paravirtualization) идёт другим путём: ядро гостя пропатчено и вместо привилегированных инструкций делает гипервызовы (hypercalls) напрямую к гипервизору. Это быстрее, но требует поддержки в госте - классика Xen PV. В 2026 чистый PV почти вымер, остались паравиртуальные драйверы (virtio, Xen PVHVM) поверх аппаратной виртуализации.
Аппаратная виртуализация (Intel VT-x, AMD-V, она же AMD SVM) добавила новый режим работы CPU - root и non-root. Гость крутится в non-root прямо на железе, а при попытке выполнить привилегированную операцию процессор делает VM exit и передаёт управление гипервизору. Это убрало нужду в бинарной трансляции. Сверху лежат расширения для памяти: EPT у Intel и NPT (RVI) у AMD - аппаратная трансляция гостевых адресов без дорогих shadow page tables.
Эмуляция - это не виртуализация. Эмулятор интерпретирует или транслирует чужую архитектуру: QEMU без KVM честно эмулирует ARM на x86, выполняя каждую инструкцию программно. Медленно, но кроссплатформенно. Виртуализация же гоняет родные инструкции гостя прямо на CPU - возможна только когда архитектуры гостя и хоста совпадают.
Гипервизор типа 1 (bare-metal) ставится прямо на железо и сам является минимальной ОС: VMware ESXi, Xen, Microsoft Hyper-V. Тип 2 (hosted) работает как приложение поверх обычной ОС: VirtualBox, VMware Workstation. KVM - особый случай: это модуль ядра Linux, который превращает само ядро в гипервизор типа 1, поэтому в экзамене его относят к типу 1, хотя рядом крутится полноценный Linux.
Контейнеры - это вообще не виртуализация железа. Они делят одно ядро хоста, а изоляция строится на namespaces (что процесс видит) и cgroups (сколько ресурсов берёт). Нет гостевой ОС, нет гипервизора, нет эмуляции устройств - отсюда мгновенный старт и почти нулевой оверхед, но и общее ядро как единая точка отказа и поверхность атаки.
Оверкоммит - это продажа ресурсов больше, чем есть физически, в расчёте что не все попросят сразу. CPU-оверкоммит: суммарно vCPU больше, чем ядер хоста; планировщик ядра тасует их, но при пике растёт steal time. Память-оверкоммит опаснее: если все гости разом займут обещанное, вмешается OOM killer. Сглаживают это ballooning (virtio-balloon - драйвер в госте по команде хоста отдаёт страницы обратно) и KSM (ksmd ищет одинаковые страницы памяти у разных гостей и склеивает их).
NUMA - это про то, что у многосокетного сервера память приклеена к конкретному CPU, и доступ к чужой памяти (remote) дороже своей (local). Если vCPU гостя бегает по одной NUMA-ноде, а его память лежит на другой - получаем просадку. Поэтому крупные гости пинят к нодам и применяют NUMA-aware размещение.
Команды и примеры
Первое, что проверяет инженер на новом хосте - поддержку аппаратной виртуализации в CPU:
Код: Выделить всё
# vmx - это Intel VT-x, svm - AMD-V
grep -E -o 'vmx|svm' /proc/cpuinfo | sort -u
# человекочитаемая сводка и проверка готовности к KVM
lscpu | grep -i virtual
Код: Выделить всё
# Debian 13 / Ubuntu 24.04
apt install cpu-checker libvirt-clients
kvm-ok
# RHEL 10 / Fedora 41+
dnf install libvirt-client
virt-host-validate
Код: Выделить всё
lsmod | grep kvm
# ожидаем kvm_intel или kvm_amd плюс базовый kvm
Код: Выделить всё
# 0 - эвристика, 1 - всегда разрешать, 2 - строгий учёт по ratio
cat /proc/sys/vm/overcommit_memory
cat /sys/kernel/mm/ksm/run # 1 = KSM активен
cat /sys/kernel/mm/ksm/pages_sharing # сколько страниц реально склеено
Код: Выделить всё
numactl --hardware # сколько нод, сколько памяти на каждой
numastat # промахи и попадания по нодам
- Флаги vmx/svm есть в /proc/cpuinfo, но виртуализация выключена в BIOS/UEFI (Intel VT-x / AMD SVM Mode) - модуль kvm_intel загрузится, но машины будут падать или работать через эмуляцию. Всегда проверяйте virt-host-validate.
- Путаница тип 1 и тип 2 на экзамене: KVM это тип 1, потому что гипервизор живёт в ядре, хоть рядом и крутится Linux. VirtualBox - тип 2.
- Эмуляцию называют виртуализацией. Если QEMU запущен без -enable-kvm (или без accel=kvm), он эмулирует CPU программно - производительность падает в десятки раз, а вы думаете что виртуализируете.
- Память-оверкоммит без ballooning и swap на проде - первый же пик нагрузки приводит к OOM killer, который убивает гостя целиком, а не освобождает страницы аккуратно.
- Игнор NUMA на двухсокетном сервере: гость с памятью на чужой ноде теряет проценты производительности на ровном месте, и это не видно в top.
- KSM экономит память, но тратит CPU на сканирование и считается утечкой для криптонагрузок - на хостах с секретами его часто отключают по соображениям безопасности (side-channel).
- На своём хосте определите вендора CPU и тип поддержки: выполните grep по vmx/svm в /proc/cpuinfo и зафиксируйте результат.
- Установите проверочные утилиты для своего семейства (cpu-checker в Debian/Ubuntu или libvirt-client в RHEL/Fedora) и прогоните kvm-ok либо virt-host-validate.
- Проверьте загруженные модули через lsmod | grep kvm и определите, intel у вас или amd.
- Посмотрите текущий режим vm.overcommit_memory и статус KSM в /sys/kernel/mm/ksm/run.
- Выполните numactl --hardware и нарисуйте на бумаге топологию: сколько нод, сколько памяти и ядер на каждой.
- Сформулируйте письменно для своего железа: какой тип гипервизора вы будете использовать и почему, и где у вас риск оверкоммита.
- В чём принципиальная разница между полной виртуализацией и паравиртуализацией, и почему вторая исторически была быстрее до появления VT-x?
- Почему KVM относят к гипервизорам типа 1, хотя он работает внутри полноценной ОС Linux?
- Чем эмуляция отличается от виртуализации, и в каком единственном случае возможна именно виртуализация, а не эмуляция?
- Что физически происходит в процессоре при VM exit, и какую роль играют EPT/NPT?
- Как ballooning и KSM помогают при оверкоммите памяти, и в чём риск каждого из них?
- Почему на многосокетном сервере важно учитывать NUMA при размещении крупного гостя?

