
Емкостное планирование отвечает на один практический вопрос: когда докупать ресурсы, чтобы не упереться в потолок в самый неподходящий момент и при этом не платить годами за простаивающее железо. Задача администратора тут не угадать, а измерить. В этом уроке разберем, какие метрики реально отражают нагрузку, как из шума временных рядов вытащить тренд, чем пик отличается от роста и какими инструментами 2026 года все это собирать и рисовать.
Как это работает
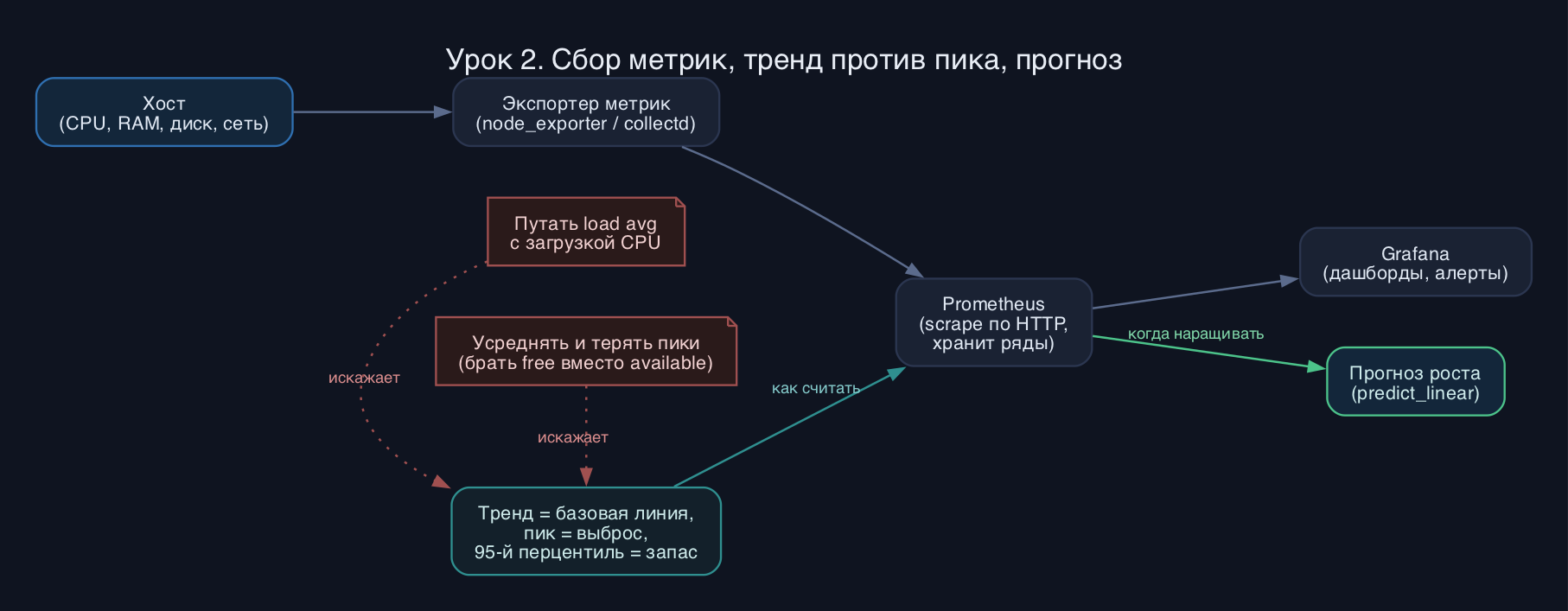
Любая система состоит из четырех классов ресурсов: процессор, память, дисковый ввод-вывод и сеть. Емкостное планирование - это наблюдение за каждым из них во времени и экстраполяция в будущее. Ключевая идея: одно мгновенное значение бесполезно, нужен ряд значений за недели и месяцы, иначе вы не отличите случайный всплеск от устойчивого роста.
Тренд - это медленное направленное изменение базовой линии потребления. Пик - кратковременный выброс над этой линией. Сезонность - регулярные колебания: ночь-день, будни-выходные, конец месяца с отчетами. Если усреднять слишком грубо, вы спрячете пики и недооцените нужный запас. Если смотреть только на максимумы, переоцените и купите лишнее. Поэтому считают перцентили: 95-й перцентиль показывает уровень, который превышается лишь 5 процентов времени, и именно он обычно лежит в основе расчета запаса.
Важно мерить правильную метрику, а не удобную. Load average не равен загрузке CPU: это число процессов в очереди на выполнение, и на многоядерной машине его надо делить на количество ядер. Память: смотрите на available, а не на free, потому что Linux отдает свободную RAM под кэш страниц, и низкий free - это норма, а не беда. Для диска главный сигнал - не заполнение, а задержка и насыщение очереди запросов.
Современный подход 2026 - модель pull. Агент-экспортер на каждом хосте отдает метрики по HTTP, а центральный сервер Prometheus периодически их забирает (scrape) и хранит как временные ряды с метками. Раньше доминировала push-модель (collectd шлет данные в центральное хранилище) - она жива в больших инсталляциях и встроенных устройствах, но для типового парка серверов сегодня берут Prometheus плюс Grafana для визуализации.
Команды и примеры
Быстрый срез текущей нагрузки штатными утилитами:
Код: Выделить всё
uptime # load average за 1, 5, 15 минут
nproc # сколько ядер - на это число делим load
vmstat 5 6 # 6 замеров с шагом 5 с: si/so - своппинг, wa - ожидание IO
iostat -xz 5 # %util и await по дискам (пакет sysstat)
free -h # смотрим строку available, а не free
sar -u -f /var/log/sa/sa15 # исторический CPU из накопленных логов sysstatКод: Выделить всё
apt install sysstat
# включить сбор: ENABLED="true" в /etc/default/sysstat
systemctl enable --now sysstatКод: Выделить всё
dnf install sysstat
systemctl enable --now sysstat
# таймеры сбора и ротации:
systemctl list-timers 'sysstat*'Код: Выделить всё
apt install prometheus-node-exporter
systemctl enable --now prometheus-node-exporter
curl -s localhost:9100/metrics | grep node_memory_MemAvailableКод: Выделить всё
dnf install golang-github-prometheus-node-exporter # из EPEL
systemctl enable --now node_exporterКод: Выделить всё
scrape_configs:
- job_name: nodes
scrape_interval: 15s
static_configs:
- targets: ['web1:9100', 'db1:9100']Код: Выделить всё
# средняя загрузка CPU по хосту за 5 минут, в процентах
100 - (avg by(instance)(rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
# через сколько секунд заполнится / по тренду за 6 часов
predict_linear(node_filesystem_avail_bytes{mountpoint="/"}[6h], 0)
# 95-й перцентиль сетевого трафика за неделю
quantile_over_time(0.95, rate(node_network_receive_bytes_total[5m])[7d:5m])Частые грабли
- Путать load average с загрузкой CPU. Load 8 на 16-ядерной машине - это полупустая система, на 4-ядерной - перегрузка вдвое.
- Тревожиться из-за низкого free. Считайте по available; вытесняемый кэш мгновенно освобождается под нужды приложений.
- Усреднять по часу или дню и так терять пики. Минутные всплески, которые роняют сервис, исчезают в часовом среднем - храните сырые данные и считайте перцентили.
- Слишком короткое окно наблюдения. Без захвата месячной и недельной сезонности (отчеты, выходные) прогноз врет в разы.
- Линейная экстраполяция взрывного роста. predict_linear корректен для плавных трендов, но недооценит экспоненту - проверяйте форму кривой глазами.
- Забыть про retention и место под сам мониторинг. Высокая частота scrape и долгое хранение сами требуют диска и памяти.
- Мерить только CPU. Узким местом чаще оказывается дисковая задержка (await) или насыщение сети, а не процессор.
- Установите sysstat и включите историческое накопление, дайте поработать пару часов под обычной нагрузкой.
- Снимите load average через uptime, поделите на nproc и оцените реальную загрузку ядер.
- Параллельно запустите vmstat 5 и нагрузочно скопируйте большой файл - найдите рост wa и активность в столбцах bi/bo.
- Поставьте node_exporter, проверьте curl на порту 9100, убедитесь что метрики отдаются.
- Поднимите Prometheus (хотя бы в контейнере podman) и добавьте свой хост в scrape_configs.
- Выполните в веб-интерфейсе запрос с predict_linear по свободному месту на / и оцените прогноз.
- Постройте в Grafana график 95-го перцентиля по CPU за сутки и сравните его с максимумом и средним.
- Чем load average отличается от процента загрузки CPU и как его правильно интерпретировать на N ядрах?
- Почему при емкостном планировании используют 95-й перцентиль, а не среднее или максимум?
- В чем разница между push-моделью collectd и pull-моделью Prometheus, и где какая уместна?
- Какую метрику памяти брать для оценки реального давления - free или available, и почему?
- Что вычисляет функция predict_linear и в каком случае ее прогноз окажется заниженным?
- Какие столбцы вывода vmstat и iostat сигнализируют о том, что узкое место - диск, а не процессор?

