
Tarantool устроен так, что весь пользовательский код и обработка запросов крутятся в одном потоке - TX (transaction) - на кооперативных файберах. Это убирает блокировки и гонки, но имеет цену: любой кусок кода, который долго не отдаёт управление (yield), задерживает всех остальных. Поэтому профилирование в Tarantool - это в первую очередь поиск ответа на вопрос "кто украл время у TX-потока": Lua-логика, garbage collector LuaJIT, диск (WAL), сеть (iproto) или фрагментация памяти. Инструменты делятся на три слоя: дешёвая интроспекция (fiber.info, fiber.top, box.stat, box.slab.info), Lua/JIT-профайлеры (sysprof, memprof, jit.dump/jit.p) и системные профайлеры (perf, gperftools, pstack/gdb).
Механика: где именно теряется времяГлавное правило: сначала локализуй узкое место дешёвыми средствами (где горит CPU, диск или память), и только потом доставай тяжёлый профайлер. Иначе соберёшь гигабайт сэмплов не там.
TX-поток и кооперативность. Один TX-поток исполняет цикл событий (event loop, ev_run на базе libev). Внутри одной итерации выполняются готовые файберы, по очереди, пока каждый сам не вызовет yield (явно через fiber.yield/fiber.sleep или неявно при обращении к диску, сети, при box-операции с репликацией). Пока файбер считает в чистом Lua без yield - event loop стоит. Отсюда первый класс узких мест: CPU-bound Lua без точек переключения.
Как считается CPU файбера. Учёт времени включается лениво. Когда вызван fiber.top_enable(), при каждом переключении контекста (функция clock_set_on_csw в ядре) берётся дельта аппаратного счётчика (на x86 - TSC) и прибавляется и к статистике всего cord (TX-потока), и к статистике уходящего файбера. То есть метрика instant/average - это доля времени потока, потраченная файбером между yield-ами. Важное следствие: учёт привязан к context switch, поэтому файбер, который не делает yield, не "тикает" корректно, а свежесозданный файбер какое-то время показывает nan/inf, пока не прожил полную итерацию. Дополнительно считается cpu_misses - сколько раз TX-поток заметил, что ОС переместила его на другое ядро (повод закрепить процесс через taskset/cpu affinity).
Диск: WAL. Каждая запись (insert/replace/update/delete) после применения в памяти попадает в WAL-поток, который делает fsync согласно wal_mode (write - без fsync на каждую транзакцию, fsync - с fsync, none - без WAL). Запись синхронная для файбера: он засыпает до подтверждения. Если диск медленный, в лог сыплется too long WAL write, и это второй класс узких мест. Порог регулируется too_long_threshold (по умолчанию 0.5 c). Учтите: этот таймер меряет не только сам fsync, но и cbus-планирование и итерацию event loop, поэтому "too long WAL" иногда сигналит на самом деле о перегруженном CPU.
LuaJIT GC и трассы. LuaJIT компилирует горячие циклы в машинные трассы (после hotloop итераций, по умолчанию 56). Инкрементальный mark-and-sweep GC при большом объёме мусора может съедать десятки процентов CPU (в perf это видно как lj_gc_step / gc_onestep). Конструкции, которые JIT не умеет компилировать (NYI - Not Yet Implemented, например pairs/next в некоторых случаях, string.format с рядом спецификаторов), вызывают abort трассы и падение в интерпретатор - третий класс узких мест.
Сеть: iproto. Бинарный протокол обслуживается отдельными network-потоками, которые перекладывают сообщения в TX через cbus. Лимит net_msg_max (по умолчанию 768) ограничивает число одновременных запросов в обработке, защищая TX от перегруза.
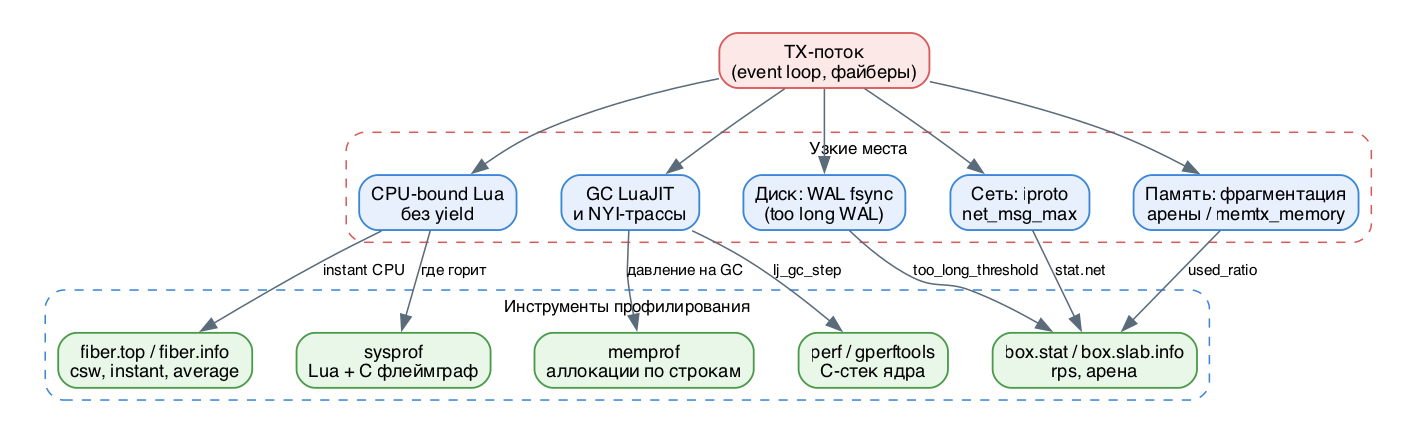
Узкие места TX-потока и инструменты профилирования
Ключевые команды и код
fiber.top - кто ест CPU прямо сейчас.
Код: Выделить всё
local fiber = require('fiber')
fiber.top_enable() -- включает учёт времени (есть накладные расходы)
-- подождать пару секунд под нагрузкой
fiber.top()
-- cpu:
-- instant average time
-- 45.2% 44.8% 12.30 (имя файбера)
fiber.top_disable() -- выключить, чтобы убрать оверхед
fiber.info - стеки и переключения. Поле csw (context switches) показывает, как часто файбер уступает управление; backtrace - в каких C-функциях он сейчас. Маленький csw при большом CPU - признак не-yield-ящего цикла.
Код: Выделить всё
require('fiber').info()
Код: Выделить всё
box.stat() -- rps по REPLACE/SELECT/CALL и т.д.
box.stat.net() -- сетевой трафик, число соединений
box.slab.info() -- arena_used_ratio, quota_used_ratio, items_used_ratio
Профайлер Lua (sysprof) - семплирующий, видит и Lua, и C-стек.
Код: Выделить всё
misc.sysprof.start({mode = 'C', interval = 10, path = 'sysprof.bin'})
-- ... нагрузка ...
misc.sysprof.stop()
-- разбор в флеймграф:
-- tarantool -e 'require("sysprof")(arg)' - sysprof.bin > tmp
-- perl flamegraph.pl tmp > sysprof.svg
Профайлер памяти (memprof) - давит ли код на GC.
Код: Выделить всё
collectgarbage() -- собрать старый мусор
misc.memprof.start('memprof.bin')
-- ... нагрузка ...
misc.memprof.stop()
-- tarantool -e 'require("memprof")(arg)' - memprof.bin
Частые заблуждения и грабли
- "fiber.top бесплатен" - нет. Учёт читает таймер на каждом переключении, поэтому держите его включённым только на окно профилирования.
- "nan/inf в fiber.top - баг" - нет, это нормально сразу после top_enable и для свежих файберов: статистика ещё не накоплена за полную итерацию.
- "too long WAL = медленный диск" - не всегда. Таймер включает CPU-фазу event loop; перегруженный TX-поток даёт тот же варнинг.
- "memprof ловит любую память" - только Lua-аллокации. malloc в C, тупл-арена memtx он не видит (для них - valgrind, box.slab.info, perf).
- "JIT всегда ускоряет" - конструкции из списка NYI обрывают трассу; jit.off() перед memprof рекомендуется, иначе аллокации с трасс маркируются как INTERNAL.
- "Tarantool отдаёт память после delete" - почти никогда. Память возвращается ОС только после рестарта; внутри арена переиспользуется.
- "pstack/gdb безопасны на проде" - они замораживают процесс примерно на секунду на каждый вызов; на хайлоаде это удар. perf и gperftools имеют почти нулевой оверхед.
Воспроизведите CPU-bound файбер и найдите его через fiber.top. В консоли Tarantool:
Код: Выделить всё
local fiber = require('fiber')
fiber.top_enable()
fiber.create(function()
fiber.name('hog')
local x = 0
for i = 1, 2e9 do x = x + i % 7 end -- считает без yield
end)
-- сразу же, в этой же консоли:
fiber.top()
Контрольные вопросы
- Почему файбер, выполняющий тяжёлый цикл без yield, делает форум неотзывчивым, хотя CPU вроде бы свободен на других ядрах? Что в архитектуре TX-потока это объясняет?
- В какой момент Tarantool обновляет CPU-метрику файбера и почему свежесозданный файбер может показывать nan в fiber.top?
- Чем sysprof отличается от memprof по тому, что они измеряют, и какой из них вы возьмёте при подозрении на нагрузку от GC LuaJIT?
- Варнинг "too long WAL write" не всегда означает медленный диск - назовите хотя бы одну другую причину и инструмент, которым вы это проверите.