
Когда обсуждают факторы ранжирования, по привычке смотрят на рантайм - на ту часть, что считает релевантность под конкретный запрос. Но добрая половина сигналов рождается задолго до запроса, в офлайн-контуре, который во внутренней терминологии называется роботом. Это разбор того, что робот делает на основе двух стыкующихся утечек - исходников каталога robot/ (краулинг и индексация) и корпуса факторов web_production (срез примерно 2022). Тезис простой: робот не ранжирует, он готовит холст. Канон-документ, статику, даты, тематику и эмбеддинги - всё то, что рантайм потом просто читает как готовые значения FI_*.
Что такое robot/ как конвейер
robot/ - это офлайн и near-online конвейер получения индексной правды. Он отвечает на вопросы, которые рантайм уже не пересматривает: что вообще попадёт в базу, какой URL станет каноничным носителем сигналов, с какой статикой, датой и в каком тире. Всего 32 компонента, и они довольно чётко распадаются по ролям.
Краулинг и транспорт сырья.
Код: Выделить всё
zora сетевой фетчер-прокси (скачивание)
uzor/addurl диспетчеры скачивания и приёмки URL
kwyt хранилище страниц: TTL, выбор IsLast-версии
rthub потоковый постпроцессинг, веер по индексаторам
salmon_agent мониторинг (факторов не даёт)
Код: Выделить всё
gemini каноникализация, owner, main-URL
mirror кластеризация зеркал, выбор главного
superdups внутрихостовые супердубли
fast_ban исключение из индекса
robots_txt исключение из индекса
selectionrank отбор в тиры
Код: Выделить всё
jupiter главный офлайн-производитель: ERF/HERF,
Link-Ann, keyinv, DSSM
lemur fresh-движок: ссылочный граф, робот-ранги,
SeoMark, host/owner-агрегаты
library упаковка ERF/HERF/аннотаций/omni (Oxygen),
selection rank
mercury realtime-сборка тех же lump-ов
melter realtime-сборка для быстрого контура
quality даты (html_dater), EDR/userdata, robotrank,
rotor-волатильность, dns-spam
watto mobile-friendly
bert инференс эмбеддингов при индексации
catfilter каталожная/гео/коммерч. разметка
Из 32 компонентов реально вычисляют или материализуют статику лишь около семи: jupiter, lemur, library, mercury, melter, quality, watto - плюс rthub, zora, catfilter и bert как поставщики сырья и эмбеддингов. Остальное - транспорт, идентичность, мониторинг и чужие вертикали.
Общий шов: ERF/HERF и каноничный документ
Почему две утечки вообще можно сшивать. Шов проходит ровно по ERF/HERF-статике и по каноничному документу. Робот в jupiter и library материализует посчитанное в индексные структуры, а рантайм читает их как факторы. Одни и те же сущности фигурируют по обе стороны.
Код: Выделить всё
robot пишет в индекс рантайм читает как
----------------------------- ------------------
SDocErf2Info -> erf_doc_lumps FI_* (документная статика)
THostErfInfoProto FI_* (хостовая статика)
TRegHostErfInfoProto
-> erf_herf_features
TDocLinkErfInfoProto / LinkAnn FI_* (ссылки/анкоры)
ann / factorann FI_* (аннотации)
DSSM-omni FI_* (эмбеддинги)
Сам корпус - 1923 фактора web_production с метаданными: cpp_name (FI_*), группа и тег (TG_*), статус live/dead, стадия (TG_L2 или TG_L3), способ потребления (TG_NN_OVER_FEATURES_USE). Робото-зависимые семейства - группы RegHostStatic, RegDocStatic, Domain, Datetime, Annotation, Xref, LinkBM25; теги TG_LINK_GRAPH, TG_OWNER, TG_DOWNER, TG_THEME_CLASSIF, TG_COMMERCIAL, TG_DATE, TG_STATIC_REGINFO, TG_WIKIPEDIA, TG_CATALOG, TG_DOC_CONTENT; срезы static&host&live (101 слот) и static&doc&live без хоста (249 слотов).Важная оговорка. Имена компонентов в роботе не равны cpp_name факторов один к одному, и часть связей гипотетична. Срез примерно 2022, пороги и имена могли смениться.
Но больше половины слотов мертвы: TG_DEPRECATED около 2117 пометок (с пересечениями тегов) и TG_UNUSED около 521. Живых робото-зависимых меньше, чем кажется по названиям групп.
Код: Выделить всё
семейство живых/всего
--------------- -----------
RegDocStatic 19/23
RegHostStatic 7/17
Datetime 8/8
Domain 0/10
Annotation 3/133
Xref 3/60
LinkBM25 0/9
TG_LINK_GRAPH 18/39
TG_OWNER 58/136
TG_DOWNER 2/48
Что робот поставляет как входы формулы
В каскаде ранжирования 2026 робот отрабатывает до запроса и кормит все три уровня.
Код: Выделить всё
L0/L1 отбор кандидатов: обратный индекс + дешёвый
BM25-матч + статика хоста -> тысячи URL
L2 ГЛАВНАЯ модель: GBDT (MatrixNet/CatBoost)
+ NN-over-features (1578 факторов) -> скоринг
L3 реранк: свежесть, разнообразие, дедуп хостов,
гео/персонализация -> топ
Документная статика (H/Q, срез static&doc&live, 249 живых): FI_PAGE_RANK[0], FI_HOPS[65], FI_ADD_TIME[41], FI_IS_MAIN_PAGE[42], FI_URL_LEN[111], FI_DOC_LEN[110], FI_TEXT_FEATURES[100], FI_IS_HTML[114], FI_RUS_LANG[40], FI_SR[24] - сложносоставной static rank.
Хостовая и owner-статика (H, срез static&host&live, 101 живой): FI_HOST_SIZE[113] (размер хоста имени Расковалова), FI_YA_BAR[14], FI_YABAR_CORE_HOST[105], FI_ADD_TIME_MP[43], классификаторы FI_NEWS[11], FI_CATALOG[13], FI_IS_BLOG[96].
Даты (множитель свежести): вся группа Datetime (8/8 живых) и TG_DATE (13/19) - FI_DATER_AGE[380], FI_FIRST_VALID_TS_10DAYS[442], FI_DATER_ADDTIME_80HOURS[1861], FI_PAGE_DATE[345].
Ссылки и анкоры (A): TG_LINK_GRAPH - FI_NUM_LINKS[37], FI_LINK_QUALITY_FIXED[405], анкорные аннотации, FI_QU_BM15_WEIGHTED[761] (запросы к URL), FI_NHOP_TEXT_BCLM_WEIGHTED[666] (тексты из хопов).
Тематика, коммерция, гео (множители): TG_THEME_CLASSIF, TG_COMMERCIAL - FI_IS_ESHOP[136], FI_ESHOP_VALUE[203]; TG_STATIC_REGINFO - FI_PAGE_REGION_SIZE[517].
Нейро-эмбеддинги документа при индексации (документная сторона T): BERT/DSSM-предсказания и омни-эмбеддинги, считаемые в bert/jupiter/library/mercury/melter заранее и кладущиеся в индекс.
И, наконец, сам выбор каноничного документа - какому URL вообще приписываются все перечисленные факторы. Это решение робота через gemini/mirror/superdups, и оно первично по отношению ко всему остальному.
Чего робот НЕ поставляет - и это основной вес
Парадокс в том, что самое весомое в формуле считается вне робота, уже под запрос или из логов.
B - Поведение (примерно 30-40 процентов): USLongPeriodUrlMobileLongClickProb, семейство LossesProb, dwell-time, CTR, click machine, окна 90/365/730/1600 дней. Источник - логи поиска, Метрики, Браузера. Робот тут лишь хранит документ-носитель.
T - Нейро-текст рантайм (примерно 25-35 процентов): DSSM/BERT-близость query к doc, LingBoost, KNN-расширения - считаются на лету под конкретный запрос.
Q - Запросные (примерно 8-12 процентов): покрытие запроса, IDF, BM25-группы - TG_DYNAMIC, рантайм базового поиска.
Раскладка долей влияния
Веса иллюстративны, реальные обучаемы и проприетарны - это ориентир порядка величин, а не точные коэффициенты.
Код: Выделить всё
Группа Доля Робот?
--------------- ------- ---------
B Поведение 30-40% Нет
T Нейро-текст 25-35% Частично
Q Запрос-док 8-12% Нет
H Хост/владелец 8-12% Да
A Ссылки/анкоры 5-10% Да
B логи поиска / Метрика / Браузер / Yabar
(робот лишь хранит документ-носитель)
T рантайм (query-doc) + док-эмбеддинги
при индексации (робот - только док-сторона)
Q рантайм базового поиска
H jupiter/lemur/quality/mirror
(часть H - поведенческие YaBar/Browser)
A lemur/jupiter/mercury
(классика Xref/LinkBM25 мертва)
Практический смысл для оптимизатора: робото-зависимая часть (статика, даты, граф, owner, каноникализация) - это то, на что вы влияете структурой сайта и временем, и это база, без которой документ не попадёт даже в кандидаты L0/L1. Но потолок выдачи задаёт поведение и рантайм-нейро, которые робот не считает. Холст можно нарисовать идеально и всё равно проиграть по B и T.Робот безусловно покрывает H и A и поставляет документную сторону T. Но весомое - B (поведение), рантайм-T (нейро-близость под запрос) и Q (запросные) - считается преимущественно НЕ в роботе. Робот рисует холст: канон-документ, статику, даты, тематику, эмбеддинги. Краски - поведение и нейро-рантайм - ложатся на этот холст уже в момент запроса.
Дисклеймер: срез примерно 2022, имена компонентов и пороги могли смениться, соответствия robot - факторы частично гипотетичны, веса групп иллюстративны.
Диаграммы конвейера
Конвейер обхода и индексации (все этапы):
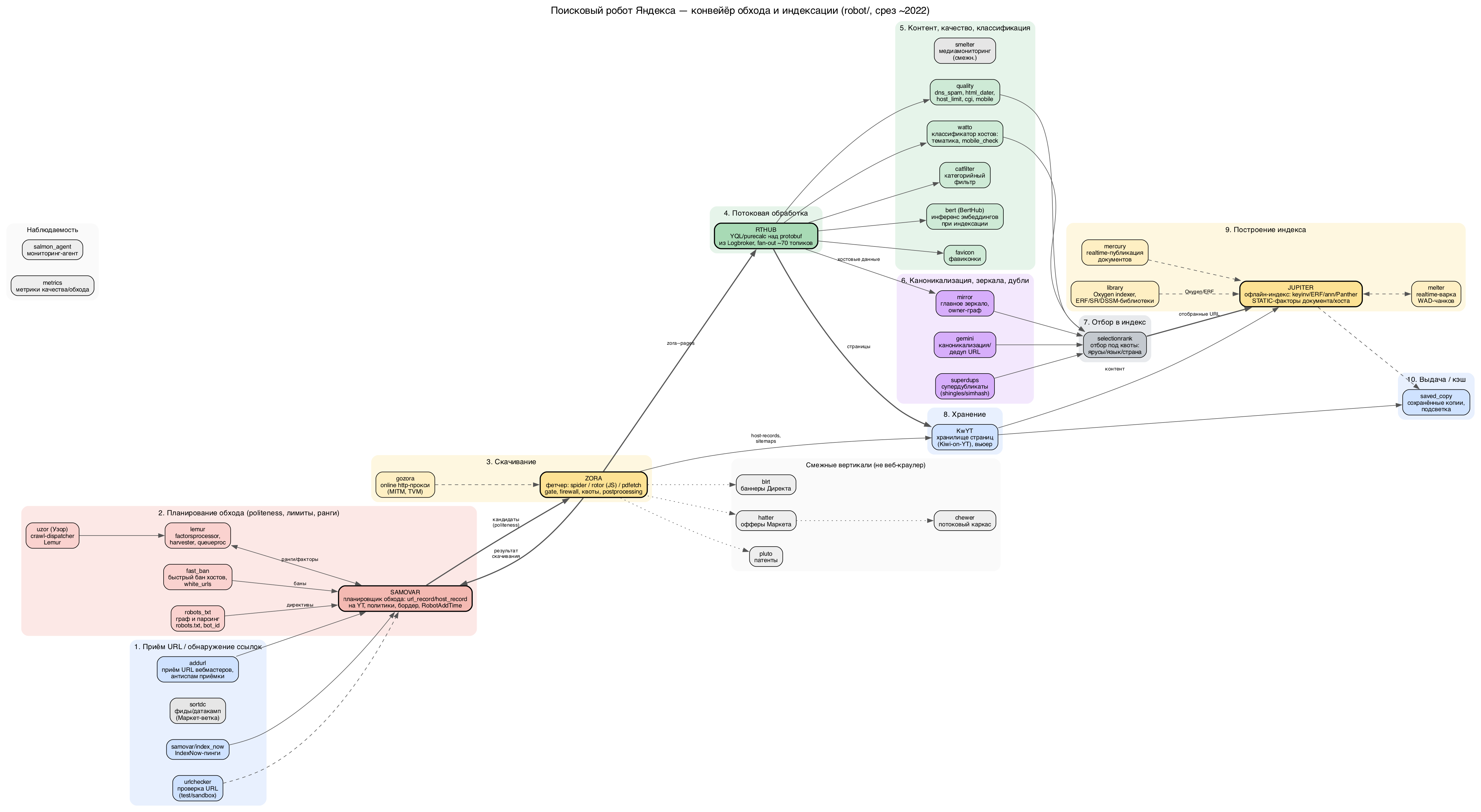
Мост робот - семейства факторов:
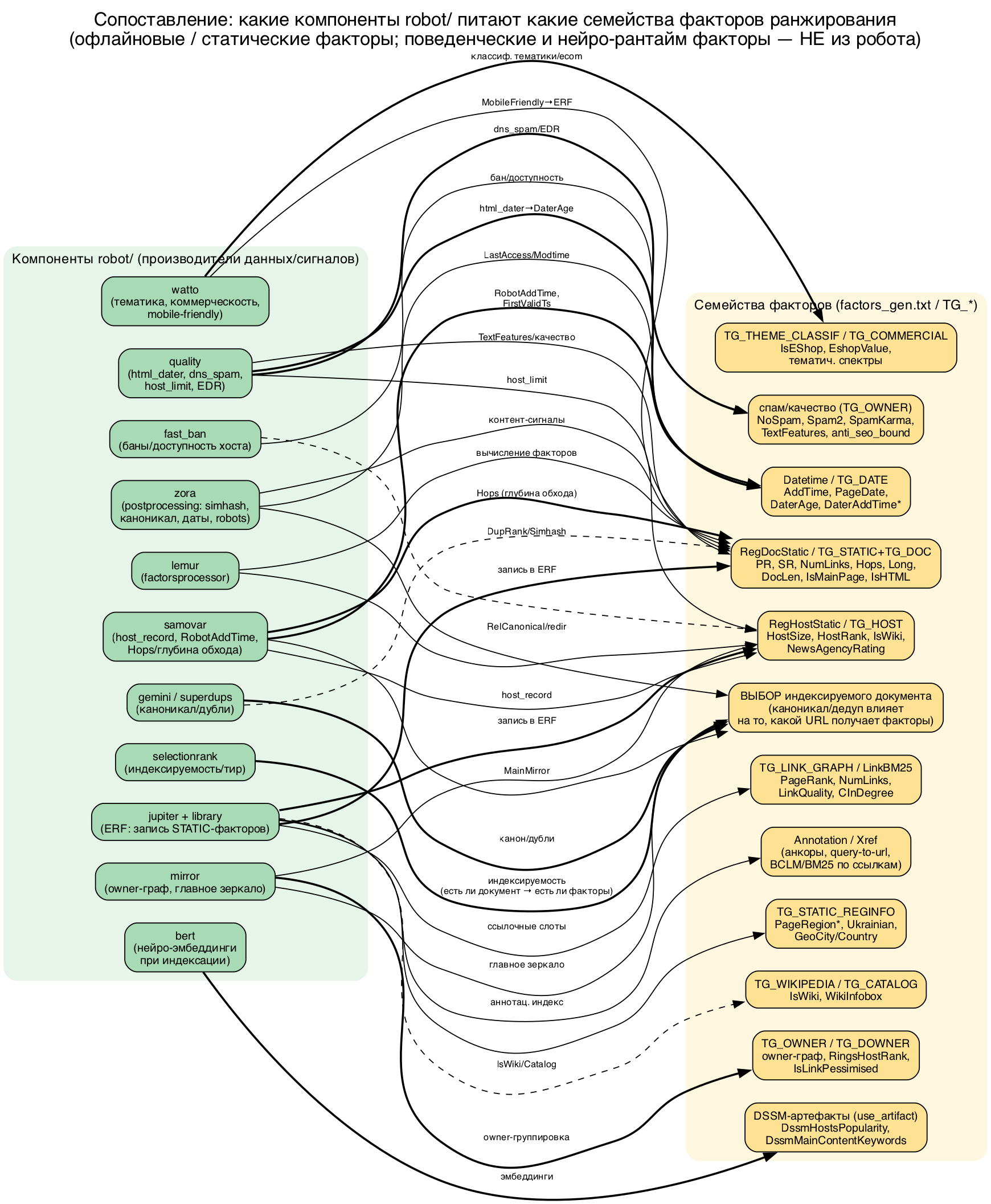
Разборы по этапам робота
- Каноникализация, зеркала, супердубли (нулевой фактор): viewtopic.php?t=1843
- Даты документа и датировщик: viewtopic.php?t=1844
- Ссылочный граф и SeoMark: viewtopic.php?t=1845
- Отбор в индекс и тиры (selectionrank): viewtopic.php?t=1846
- Нейро-эмбеддинги при индексации: viewtopic.php?t=1847
- Что робот НЕ считает: viewtopic.php?t=1848
Общий синтез всей серии: viewtopic.php?t=1855